 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisDA 2022 Challenge: Domain Adaptation for Industrial Waste Sorting
Mar 26, 2023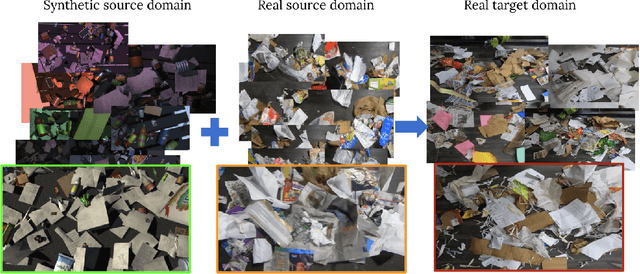

Label-efficient and reliable semantic segmentation is essential for many real-life applications, especially for industrial settings with high visual diversity, such as waste sorting. In industrial waste sorting, one of the biggest challenges is the extreme diversity of the input stream depending on factors like the location of the sorting facility, the equipment available in the facility, and the time of year, all of which significantly impact the composition and visual appearance of the waste stream. These changes in the data are called ``visual domains'', and label-efficient adaptation of models to such domains is needed for successful semantic segmentation of industrial waste. To test the abilities of computer vision models on this task, we present the VisDA 2022 Challenge on Domain Adaptation for Industrial Waste Sorting. Our challenge incorporates a fully-annotated waste sorting dataset, ZeroWaste, collected from two real material recovery facilities in different locations and seasons, as well as a novel procedurally generated synthetic waste sorting dataset, SynthWaste. In this competition, we aim to answer two questions: 1) can we leverage domain adaptation techniques to minimize the domain gap? and 2) can synthetic data augmentation improve performance on this task and help adapt to changing data distributions? The results of the competition show that industrial waste detection poses a real domain adaptation problem, that domain generalization techniques such as augmentations, ensembling, etc., improve the overall performance on the unlabeled target domain examples, and that leveraging synthetic data effectively remains an open problem. See https://ai.bu.edu/visda-2022/
Bidirectional Domain Mixup for Domain Adaptive Semantic Segmentation
Mar 17, 2023



Mixup provides interpolated training samples and allows the model to obtain smoother decision boundaries for better generalization. The idea can be naturally applied to the domain adaptation task, where we can mix the source and target samples to obtain domain-mixed samples for better adaptation. However, the extension of the idea from classification to segmentation (i.e., structured output) is nontrivial. This paper systematically studies the impact of mixup under the domain adaptaive semantic segmentation task and presents a simple yet effective mixup strategy called Bidirectional Domain Mixup (BDM). In specific, we achieve domain mixup in two-step: cut and paste. Given the warm-up model trained from any adaptation techniques, we forward the source and target samples and perform a simple threshold-based cut out of the unconfident regions (cut). After then, we fill-in the dropped regions with the other domain region patches (paste). In doing so, we jointly consider class distribution, spatial structure, and pseudo label confidence. Based on our analysis, we found that BDM leaves domain transferable regions by cutting, balances the dataset-level class distribution while preserving natural scene context by pasting. We coupled our proposal with various state-of-the-art adaptation models and observe significant improvement consistently. We also provide extensive ablation experiments to empirically verify our main components of the framework. Visit our project page with the code at https://sites.google.com/view/bidirectional-domain-mixup
1st Place Solution to NeurIPS 2022 Challenge on Visual Domain Adaptation
Nov 26, 2022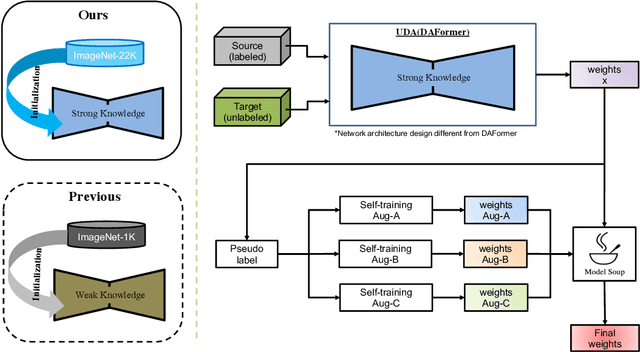



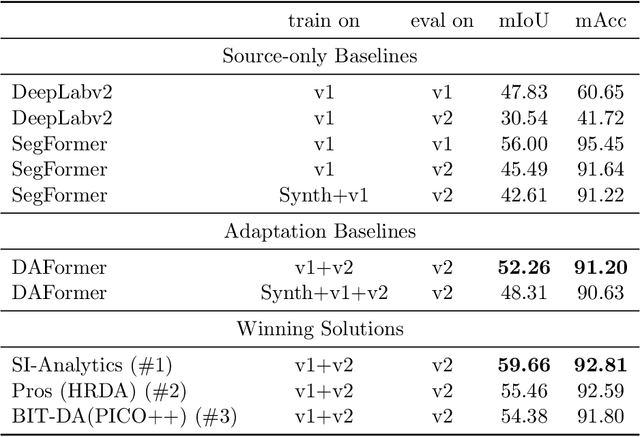
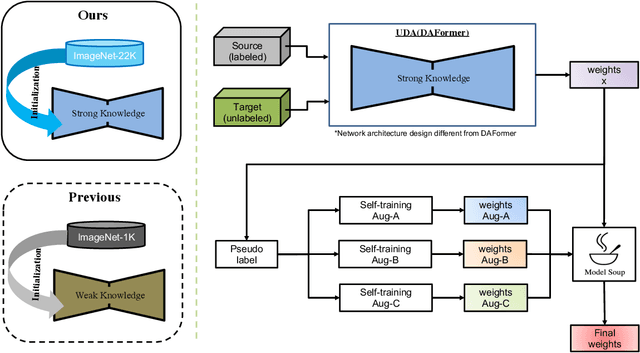
The Visual Domain Adaptation(VisDA) 2022 Challenge calls for an unsupervised domain adaptive model in semantic segmentation tasks for industrial waste sorting. In this paper, we introduce the SIA_Adapt method, which incorporates several methods for domain adaptive models. The core of our method in the transferable representation from large-scale pre-training. In this process, we choose a network architecture that differs from the state-of-the-art for domain adaptation. After that, self-training using pseudo-labels helps to make the initial adaptation model more adaptable to the target domain. Finally, the model soup scheme helped to improve the generalization performance in the target domain. Our method SIA_Adapt achieves 1st place in the VisDA2022 challenge. The code is available on https: //github.com/DaehanKim-Korea/VisDA2022_Winner_Solution.
Source Domain Subset Sampling for Semi-Supervised Domain Adaptation in Semantic Segmentation
May 03, 2022
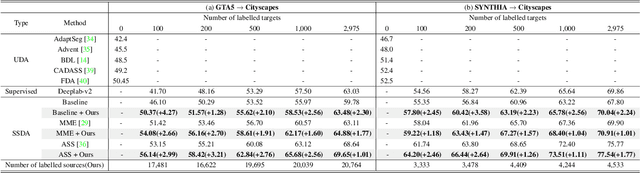

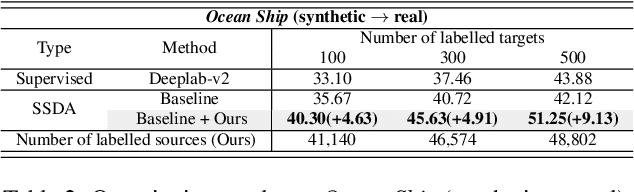
In this paper, we introduce source domain subset sampling (SDSS) as a new perspective of semi-supervised domain adaptation. We propose domain adaptation by sampling and exploiting only a meaningful subset from source data for training. Our key assumption is that the entire source domain data may contain samples that are unhelpful for the adaptation. Therefore, the domain adaptation can benefit from a subset of source data composed solely of helpful and relevant samples. The proposed method effectively subsamples full source data to generate a small-scale meaningful subset. Therefore, training time is reduced, and performance is improved with our subsampled source data. To further verify the scalability of our method, we construct a new dataset called Ocean Ship, which comprises 500 real and 200K synthetic sample images with ground-truth labels. The SDSS achieved a state-of-the-art performance when applied on GTA5 to Cityscapes and SYNTHIA to Cityscapes public benchmark datasets and a 9.13 mIoU improvement on our Ocean Ship dataset over a baseline model.
Masked Deep Q-Recommender for Effective Question Scheduling
Dec 19, 2021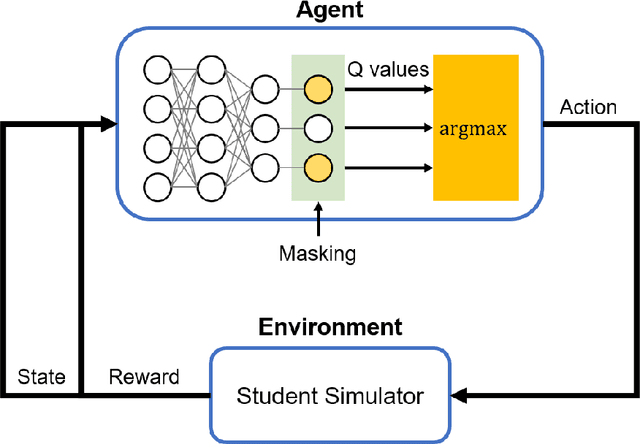
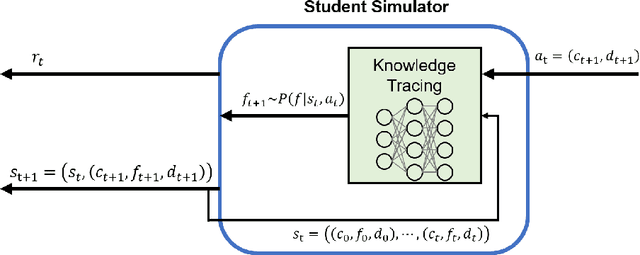

Providing appropriate questions according to a student's knowledge level is imperative in personalized learning. However, It requires a lot of manual effort for teachers to understand students' knowledge status and provide optimal questions accordingly. To address this problem, we introduce a question scheduling model that can effectively boost student knowledge level using Reinforcement Learning (RL). Our proposed method first evaluates students' concept-level knowledge using knowledge tracing (KT) model. Given predicted student knowledge, RL-based recommender predicts the benefits of each question. With curriculum range restriction and duplicate penalty, the recommender selects questions sequentially until it reaches the predefined number of questions. In an experimental setting using a student simulator, which gives 20 questions per day for two weeks, questions recommended by the proposed method increased average student knowledge level by 21.3%, superior to an expert-designed schedule baseline with a 10% increase in student knowledge levels.
Diagnostic Assessment Generation via Combinatorial Search
Dec 06, 2021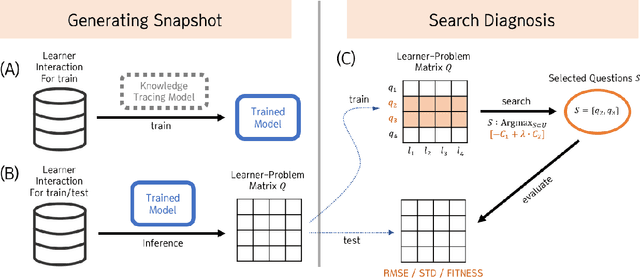
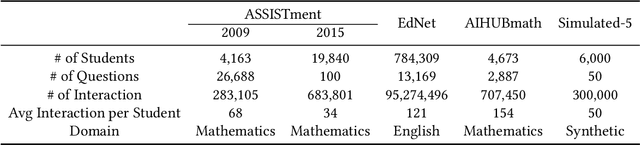
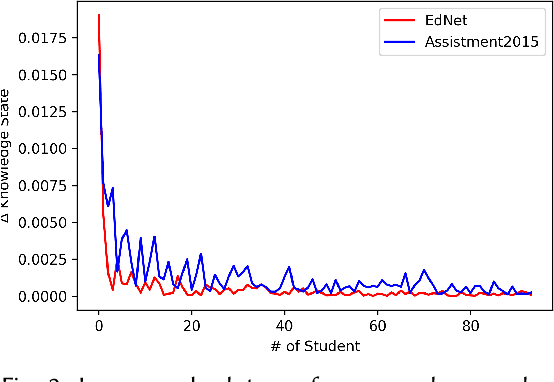
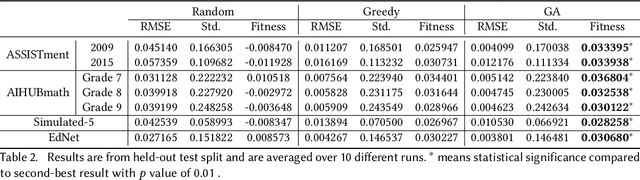
Initial assessment tests are crucial in capturing learner knowledge states in a consistent manner. Aside from crafting questions itself, putting together relevant problems to form a question sheet is also a time-consuming process. In this work, we present a generic formulation of question assembly and a genetic algorithm based method that can generate assessment tests from raw problem-solving history. First, we estimate the learner-question knowledge matrix (snapshot). Each matrix element stands for the probability that a learner correctly answers a specific question. We formulate the task as a combinatorial search over this snapshot. To ensure representative and discriminative diagnostic tests, questions are selected (1) that has a low root mean squared error against the whole question pool and (2) high standard deviation among learner performances. Experimental results show that the proposed method outperforms greedy and random baseline by a large margin in one private dataset and four public datasets. We also performed qualitative analysis on the generated assessment test for 9th graders, which enjoys good problem scatterness across the whole 9th grader curriculum and decent difficulty level distribution.