 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAIS-LLM: A Unified Framework for Maritime Trajectory Prediction, Anomaly Detection, and Collision Risk Assessment with Explainable Forecasting
Aug 11, 2025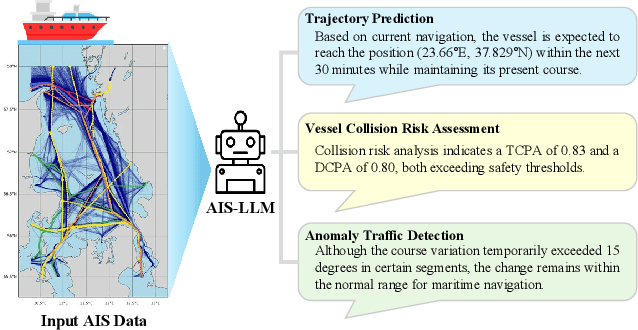

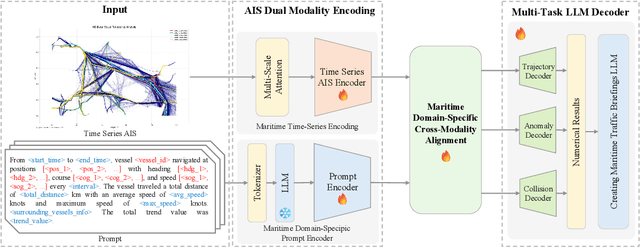

With the increase in maritime traffic and the mandatory implementation of the Automatic Identification System (AIS), the importance and diversity of maritime traffic analysis tasks based on AIS data, such as vessel trajectory prediction, anomaly detection, and collision risk assessment, is rapidly growing. However, existing approaches tend to address these tasks individually, making it difficult to holistically consider complex maritime situations. To address this limitation, we propose a novel framework, AIS-LLM, which integrates time-series AIS data with a large language model (LLM). AIS-LLM consists of a Time-Series Encoder for processing AIS sequences, an LLM-based Prompt Encoder, a Cross-Modality Alignment Module for semantic alignment between time-series data and textual prompts, and an LLM-based Multi-Task Decoder. This architecture enables the simultaneous execution of three key tasks: trajectory prediction, anomaly detection, and risk assessment of vessel collisions within a single end-to-end system. Experimental results demonstrate that AIS-LLM outperforms existing methods across individual tasks, validating its effectiveness. Furthermore, by integratively analyzing task outputs to generate situation summaries and briefings, AIS-LLM presents the potential for more intelligent and efficient maritime traffic management.
PBVS 2024 Solution: Self-Supervised Learning and Sampling Strategies for SAR Classification in Extreme Long-Tail Distribution
Dec 17, 2024



The Multimodal Learning Workshop (PBVS 2024) aims to improve the performance of automatic target recognition (ATR) systems by leveraging both Synthetic Aperture Radar (SAR) data, which is difficult to interpret but remains unaffected by weather conditions and visible light, and Electro-Optical (EO) data for simultaneous learning. The subtask, known as the Multi-modal Aerial View Imagery Challenge - Classification, focuses on predicting the class label of a low-resolution aerial image based on a set of SAR-EO image pairs and their respective class labels. The provided dataset consists of SAR-EO pairs, characterized by a severe long-tail distribution with over a 1000-fold difference between the largest and smallest classes, making typical long-tail methods difficult to apply. Additionally, the domain disparity between the SAR and EO datasets complicates the effectiveness of standard multimodal methods. To address these significant challenges, we propose a two-stage learning approach that utilizes self-supervised techniques, combined with multimodal learning and inference through SAR-to-EO translation for effective EO utilization. In the final testing phase of the PBVS 2024 Multi-modal Aerial View Image Challenge - Classification (SAR Classification) task, our model achieved an accuracy of 21.45%, an AUC of 0.56, and a total score of 0.30, placing us 9th in the competition.
A Multi-In-Single-Out Network for Video Frame Interpolation without Optical Flow
Dec 05, 2023In general, deep learning-based video frame interpolation (VFI) methods have predominantly focused on estimating motion vectors between two input frames and warping them to the target time. While this approach has shown impressive performance for linear motion between two input frames, it exhibits limitations when dealing with occlusions and nonlinear movements. Recently, generative models have been applied to VFI to address these issues. However, as VFI is not a task focused on generating plausible images, but rather on predicting accurate intermediate frames between two given frames, performance limitations still persist. In this paper, we propose a multi-in-single-out (MISO) based VFI method that does not rely on motion vector estimation, allowing it to effectively model occlusions and nonlinear motion. Additionally, we introduce a novel motion perceptual loss that enables MISO-VFI to better capture the spatio-temporal correlations within the video frames. Our MISO-VFI method achieves state-of-the-art results on VFI benchmarks Vimeo90K, Middlebury, and UCF101, with a significant performance gap compared to existing approaches.
1st Place Solution to MultiEarth 2023 Challenge on Multimodal SAR-to-EO Image Translation
Jun 22, 2023


The Multimodal Learning for Earth and Environment Workshop (MultiEarth 2023) aims to harness the substantial amount of remote sensing data gathered over extensive periods for the monitoring and analysis of Earth's ecosystems'health. The subtask, Multimodal SAR-to-EO Image Translation, involves the use of robust SAR data, even under adverse weather and lighting conditions, transforming it into high-quality, clear, and visually appealing EO data. In the context of the SAR2EO task, the presence of clouds or obstructions in EO data can potentially pose a challenge. To address this issue, we propose the Clean Collector Algorithm (CCA), designed to take full advantage of this cloudless SAR data and eliminate factors that may hinder the data learning process. Subsequently, we applied pix2pixHD for the SAR-to-EO translation and Restormer for image enhancement. In the final evaluation, the team 'CDRL' achieved an MAE of 0.07313, securing the top rank on the leaderboard.
VisDA 2022 Challenge: Domain Adaptation for Industrial Waste Sorting
Mar 26, 2023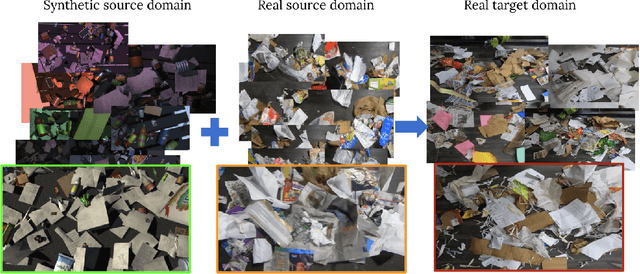
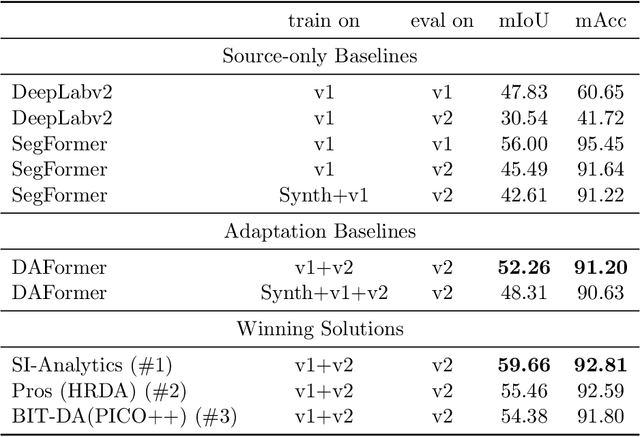

Label-efficient and reliable semantic segmentation is essential for many real-life applications, especially for industrial settings with high visual diversity, such as waste sorting. In industrial waste sorting, one of the biggest challenges is the extreme diversity of the input stream depending on factors like the location of the sorting facility, the equipment available in the facility, and the time of year, all of which significantly impact the composition and visual appearance of the waste stream. These changes in the data are called ``visual domains'', and label-efficient adaptation of models to such domains is needed for successful semantic segmentation of industrial waste. To test the abilities of computer vision models on this task, we present the VisDA 2022 Challenge on Domain Adaptation for Industrial Waste Sorting. Our challenge incorporates a fully-annotated waste sorting dataset, ZeroWaste, collected from two real material recovery facilities in different locations and seasons, as well as a novel procedurally generated synthetic waste sorting dataset, SynthWaste. In this competition, we aim to answer two questions: 1) can we leverage domain adaptation techniques to minimize the domain gap? and 2) can synthetic data augmentation improve performance on this task and help adapt to changing data distributions? The results of the competition show that industrial waste detection poses a real domain adaptation problem, that domain generalization techniques such as augmentations, ensembling, etc., improve the overall performance on the unlabeled target domain examples, and that leveraging synthetic data effectively remains an open problem. See https://ai.bu.edu/visda-2022/
CAFS: Class Adaptive Framework for Semi-Supervised Semantic Segmentation
Mar 21, 2023
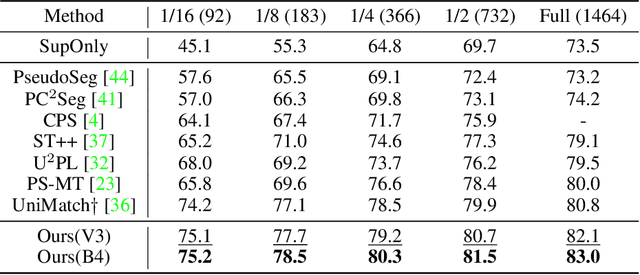


Semi-supervised semantic segmentation learns a model for classifying pixels into specific classes using a few labeled samples and numerous unlabeled images. The recent leading approach is consistency regularization by selftraining with pseudo-labeling pixels having high confidences for unlabeled images. However, using only highconfidence pixels for self-training may result in losing much of the information in the unlabeled datasets due to poor confidence calibration of modern deep learning networks. In this paper, we propose a class-adaptive semisupervision framework for semi-supervised semantic segmentation (CAFS) to cope with the loss of most information that occurs in existing high-confidence-based pseudolabeling methods. Unlike existing semi-supervised semantic segmentation frameworks, CAFS constructs a validation set on a labeled dataset, to leverage the calibration performance for each class. On this basis, we propose a calibration aware class-wise adaptive thresholding and classwise adaptive oversampling using the analysis results from the validation set. Our proposed CAFS achieves state-ofthe-art performance on the full data partition of the base PASCAL VOC 2012 dataset and on the 1/4 data partition of the Cityscapes dataset with significant margins of 83.0% and 80.4%, respectively. The code is available at https://github.com/cjf8899/CAFS.
Bidirectional Domain Mixup for Domain Adaptive Semantic Segmentation
Mar 17, 2023



Mixup provides interpolated training samples and allows the model to obtain smoother decision boundaries for better generalization. The idea can be naturally applied to the domain adaptation task, where we can mix the source and target samples to obtain domain-mixed samples for better adaptation. However, the extension of the idea from classification to segmentation (i.e., structured output) is nontrivial. This paper systematically studies the impact of mixup under the domain adaptaive semantic segmentation task and presents a simple yet effective mixup strategy called Bidirectional Domain Mixup (BDM). In specific, we achieve domain mixup in two-step: cut and paste. Given the warm-up model trained from any adaptation techniques, we forward the source and target samples and perform a simple threshold-based cut out of the unconfident regions (cut). After then, we fill-in the dropped regions with the other domain region patches (paste). In doing so, we jointly consider class distribution, spatial structure, and pseudo label confidence. Based on our analysis, we found that BDM leaves domain transferable regions by cutting, balances the dataset-level class distribution while preserving natural scene context by pasting. We coupled our proposal with various state-of-the-art adaptation models and observe significant improvement consistently. We also provide extensive ablation experiments to empirically verify our main components of the framework. Visit our project page with the code at https://sites.google.com/view/bidirectional-domain-mixup
1st Place Solution to NeurIPS 2022 Challenge on Visual Domain Adaptation
Nov 26, 2022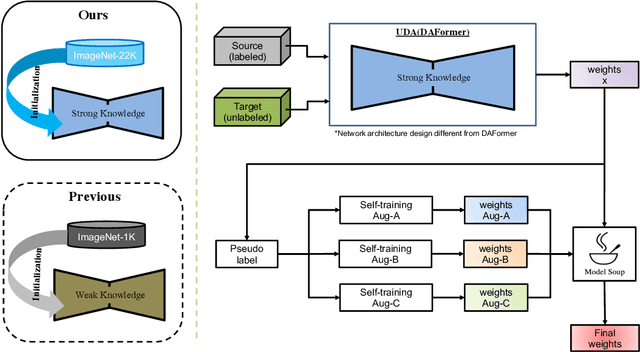



The Visual Domain Adaptation(VisDA) 2022 Challenge calls for an unsupervised domain adaptive model in semantic segmentation tasks for industrial waste sorting. In this paper, we introduce the SIA_Adapt method, which incorporates several methods for domain adaptive models. The core of our method in the transferable representation from large-scale pre-training. In this process, we choose a network architecture that differs from the state-of-the-art for domain adaptation. After that, self-training using pseudo-labels helps to make the initial adaptation model more adaptable to the target domain. Finally, the model soup scheme helped to improve the generalization performance in the target domain. Our method SIA_Adapt achieves 1st place in the VisDA2022 challenge. The code is available on https: //github.com/DaehanKim-Korea/VisDA2022_Winner_Solution.
Source Domain Subset Sampling for Semi-Supervised Domain Adaptation in Semantic Segmentation
May 03, 2022
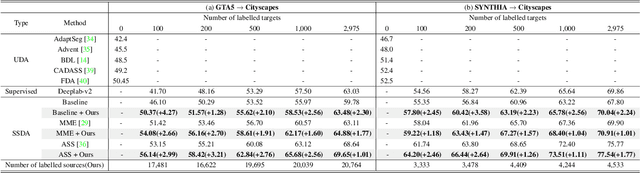

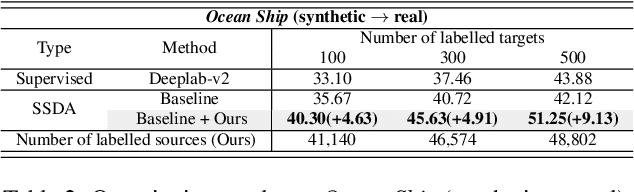
In this paper, we introduce source domain subset sampling (SDSS) as a new perspective of semi-supervised domain adaptation. We propose domain adaptation by sampling and exploiting only a meaningful subset from source data for training. Our key assumption is that the entire source domain data may contain samples that are unhelpful for the adaptation. Therefore, the domain adaptation can benefit from a subset of source data composed solely of helpful and relevant samples. The proposed method effectively subsamples full source data to generate a small-scale meaningful subset. Therefore, training time is reduced, and performance is improved with our subsampled source data. To further verify the scalability of our method, we construct a new dataset called Ocean Ship, which comprises 500 real and 200K synthetic sample images with ground-truth labels. The SDSS achieved a state-of-the-art performance when applied on GTA5 to Cityscapes and SYNTHIA to Cityscapes public benchmark datasets and a 9.13 mIoU improvement on our Ocean Ship dataset over a baseline model.
Unsupervised Change Detection Based on Image Reconstruction Loss
Apr 05, 2022
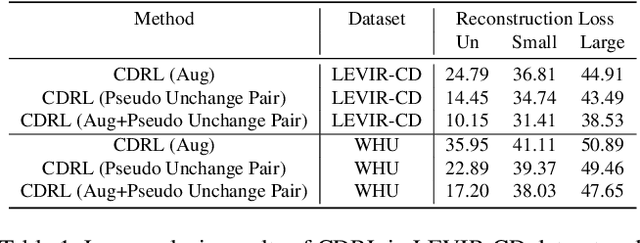


To train the change detector, bi-temporal images taken at different times in the same area are used. However, collecting labeled bi-temporal images is expensive and time consuming. To solve this problem, various unsupervised change detection methods have been proposed, but they still require unlabeled bi-temporal images. In this paper, we propose unsupervised change detection based on image reconstruction loss using only unlabeled single temporal single image. The image reconstruction model is trained to reconstruct the original source image by receiving the source image and the photometrically transformed source image as a pair. During inference, the model receives bi-temporal images as the input, and tries to reconstruct one of the inputs. The changed region between bi-temporal images shows high reconstruction loss. Our change detector showed significant performance in various change detection benchmark datasets even though only a single temporal single source image was used. The code and trained models will be publicly available for reproducibility.