 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlow-Assisted Motion Learning Network for Weakly-Supervised Group Activity Recognition
May 28, 2024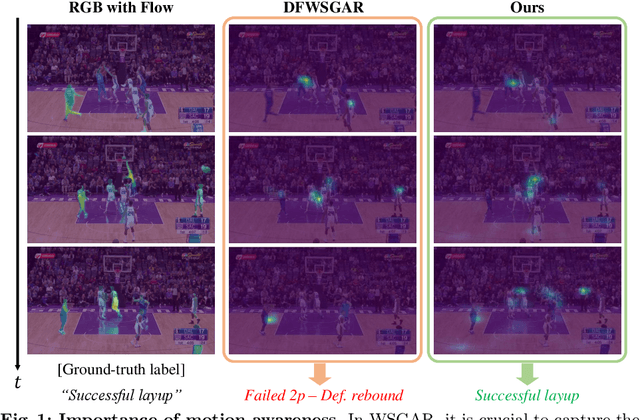



Weakly-Supervised Group Activity Recognition (WSGAR) aims to understand the activity performed together by a group of individuals with the video-level label and without actor-level labels. We propose Flow-Assisted Motion Learning Network (Flaming-Net) for WSGAR, which consists of the motion-aware actor encoder to extract actor features and the two-pathways relation module to infer the interaction among actors and their activity. Flaming-Net leverages an additional optical flow modality in the training stage to enhance its motion awareness when finding locally active actors. The first pathway of the relation module, the actor-centric path, initially captures the temporal dynamics of individual actors and then constructs inter-actor relationships. In parallel, the group-centric path starts by building spatial connections between actors within the same timeframe and then captures simultaneous spatio-temporal dynamics among them. We demonstrate that Flaming-Net achieves new state-of-the-art WSGAR results on two benchmarks, including a 2.8%p higher MPCA score on the NBA dataset. Importantly, we use the optical flow modality only for training and not for inference.
Spatio-Temporal Proximity-Aware Dual-Path Model for Panoramic Activity Recognition
Mar 21, 2024



Panoramic Activity Recognition (PAR) seeks to identify diverse human activities across different scales, from individual actions to social group and global activities in crowded panoramic scenes. PAR presents two major challenges: 1) recognizing the nuanced interactions among numerous individuals and 2) understanding multi-granular human activities. To address these, we propose Social Proximity-aware Dual-Path Network (SPDP-Net) based on two key design principles. First, while previous works often focus on spatial distance among individuals within an image, we argue to consider the spatio-temporal proximity. It is crucial for individual relation encoding to correctly understand social dynamics. Secondly, deviating from existing hierarchical approaches (individual-to-social-to-global activity), we introduce a dual-path architecture for multi-granular activity recognition. This architecture comprises individual-to-global and individual-to-social paths, mutually reinforcing each other's task with global-local context through multiple layers. Through extensive experiments, we validate the effectiveness of the spatio-temporal proximity among individuals and the dual-path architecture in PAR. Furthermore, SPDP-Net achieves new state-of-the-art performance with 46.5\% of overall F1 score on JRDB-PAR dataset.
Towards Robust Multimodal Prompting With Missing Modalities
Dec 27, 2023



Recently, multimodal prompting, which introduces learnable missing-aware prompts for all missing modality cases, has exhibited impressive performance. However, it encounters two critical issues: 1) The number of prompts grows exponentially as the number of modalities increases; and 2) It lacks robustness in scenarios with different missing modality settings between training and inference. In this paper, we propose a simple yet effective prompt design to address these challenges. Instead of using missing-aware prompts, we utilize prompts as modality-specific tokens, enabling them to capture the unique characteristics of each modality. Furthermore, our prompt design leverages orthogonality between prompts as a key element to learn distinct information across different modalities and promote diversity in the learned representations. Extensive experiments demonstrate that our prompt design enhances both performance and robustness while reducing the number of prompts.
CAFS: Class Adaptive Framework for Semi-Supervised Semantic Segmentation
Mar 21, 2023
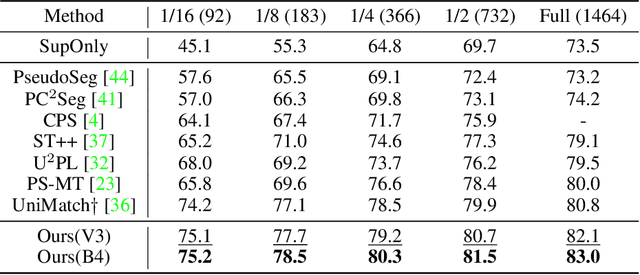


Semi-supervised semantic segmentation learns a model for classifying pixels into specific classes using a few labeled samples and numerous unlabeled images. The recent leading approach is consistency regularization by selftraining with pseudo-labeling pixels having high confidences for unlabeled images. However, using only highconfidence pixels for self-training may result in losing much of the information in the unlabeled datasets due to poor confidence calibration of modern deep learning networks. In this paper, we propose a class-adaptive semisupervision framework for semi-supervised semantic segmentation (CAFS) to cope with the loss of most information that occurs in existing high-confidence-based pseudolabeling methods. Unlike existing semi-supervised semantic segmentation frameworks, CAFS constructs a validation set on a labeled dataset, to leverage the calibration performance for each class. On this basis, we propose a calibration aware class-wise adaptive thresholding and classwise adaptive oversampling using the analysis results from the validation set. Our proposed CAFS achieves state-ofthe-art performance on the full data partition of the base PASCAL VOC 2012 dataset and on the 1/4 data partition of the Cityscapes dataset with significant margins of 83.0% and 80.4%, respectively. The code is available at https://github.com/cjf8899/CAFS.
Zero-Shot Semantic Segmentation via Spatial and Multi-Scale Aware Visual Class Embedding
Dec 20, 2021
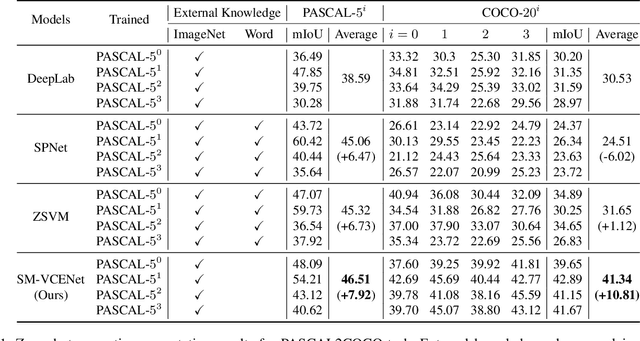


Fully supervised semantic segmentation technologies bring a paradigm shift in scene understanding. However, the burden of expensive labeling cost remains as a challenge. To solve the cost problem, recent studies proposed language model based zero-shot semantic segmentation (L-ZSSS) approaches. In this paper, we address L-ZSSS has a limitation in generalization which is a virtue of zero-shot learning. Tackling the limitation, we propose a language-model-free zero-shot semantic segmentation framework, Spatial and Multi-scale aware Visual Class Embedding Network (SM-VCENet). Furthermore, leveraging vision-oriented class embedding SM-VCENet enriches visual information of the class embedding by multi-scale attention and spatial attention. We also propose a novel benchmark (PASCAL2COCO) for zero-shot semantic segmentation, which provides generalization evaluation by domain adaptation and contains visually challenging samples. In experiments, our SM-VCENet outperforms zero-shot semantic segmentation state-of-the-art by a relative margin in PASCAL-5i benchmark and shows generalization-robustness in PASCAL2COCO benchmark.
NL-LinkNet: Toward Lighter but More Accurate Road Extraction with Non-Local Operations
Aug 22, 2019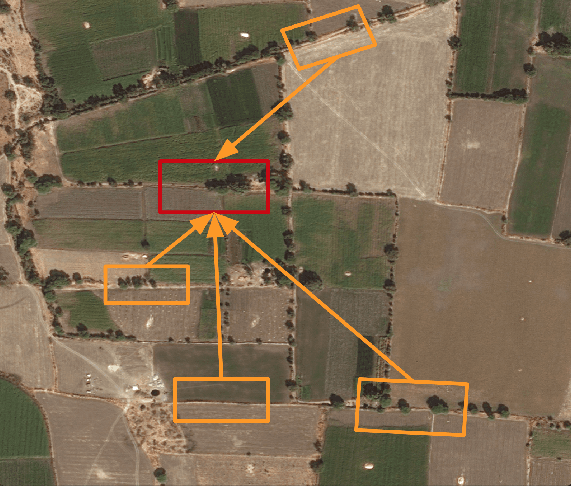
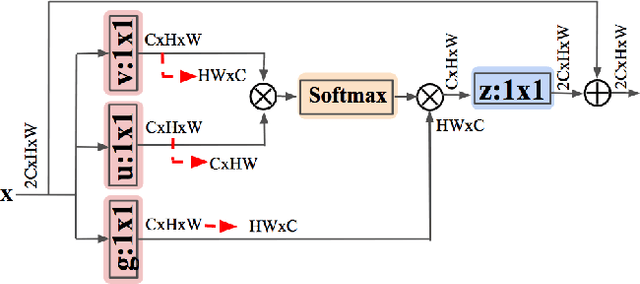
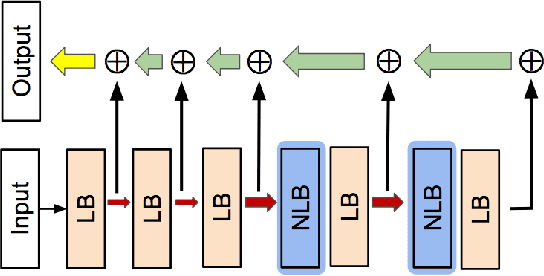
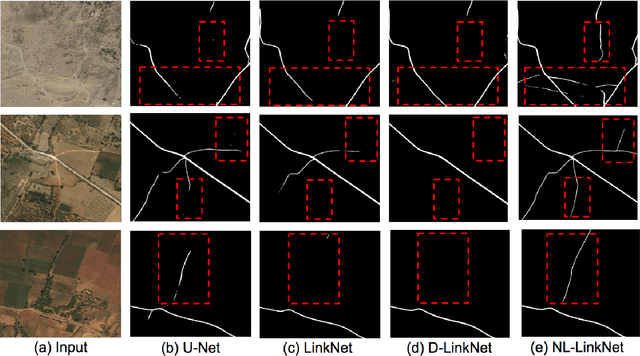
Road extraction from very high resolution satellite images is one of the most important topics in the field of remote sensing. For the road segmentation problem, spatial properties of the data can usually be captured using Convolutional Neural Networks. However, this approach only considers a few local neighborhoods at a time and has difficulty capturing long-range dependencies. In order to overcome the problem, we propose Non-Local LinkNet with non-local blocks that can grasp relations between global features. It enables each spatial feature point to refer to all other contextual information and results in more accurate road segmentation. In detail, our method achieved 65.00\% mIOU scores on the DeepGlobe 2018 Road Extraction Challenge dataset. Our best model outperformed D-LinkNet, 1st-ranked solution, by a significant gap of mIOU 0.88\% with much less number of parameters. We also present empirical analyses on proper usage of non-local blocks for the baseline model.