 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Semantic Segmentation via Spatial and Multi-Scale Aware Visual Class Embedding
Paper and Code
Dec 20, 2021
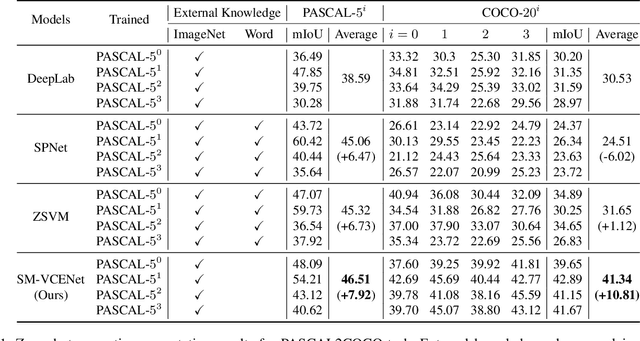


Fully supervised semantic segmentation technologies bring a paradigm shift in scene understanding. However, the burden of expensive labeling cost remains as a challenge. To solve the cost problem, recent studies proposed language model based zero-shot semantic segmentation (L-ZSSS) approaches. In this paper, we address L-ZSSS has a limitation in generalization which is a virtue of zero-shot learning. Tackling the limitation, we propose a language-model-free zero-shot semantic segmentation framework, Spatial and Multi-scale aware Visual Class Embedding Network (SM-VCENet). Furthermore, leveraging vision-oriented class embedding SM-VCENet enriches visual information of the class embedding by multi-scale attention and spatial attention. We also propose a novel benchmark (PASCAL2COCO) for zero-shot semantic segmentation, which provides generalization evaluation by domain adaptation and contains visually challenging samples. In experiments, our SM-VCENet outperforms zero-shot semantic segmentation state-of-the-art by a relative margin in PASCAL-5i benchmark and shows generalization-robustness in PASCAL2COCO benchmark.