 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNTIRE 2020 Challenge on Perceptual Extreme Super-Resolution: Methods and Results
May 03, 2020
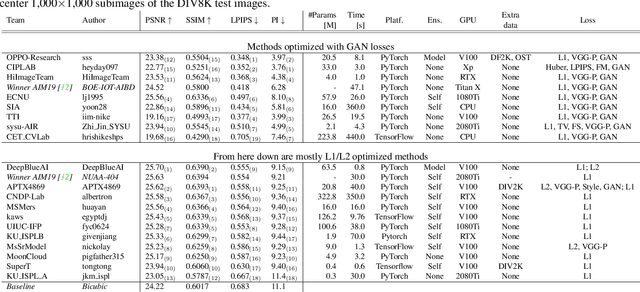

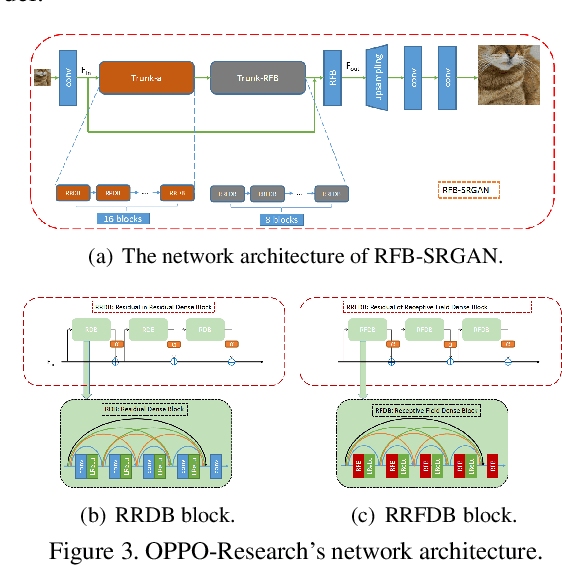
This paper reviews the NTIRE 2020 challenge on perceptual extreme super-resolution with focus on proposed solutions and results. The challenge task was to super-resolve an input image with a magnification factor 16 based on a set of prior examples of low and corresponding high resolution images. The goal is to obtain a network design capable to produce high resolution results with the best perceptual quality and similar to the ground truth. The track had 280 registered participants, and 19 teams submitted the final results. They gauge the state-of-the-art in single image super-resolution.
Revisiting Classical Bagging with Modern Transfer Learning for On-the-fly Disaster Damage Detector
Oct 04, 2019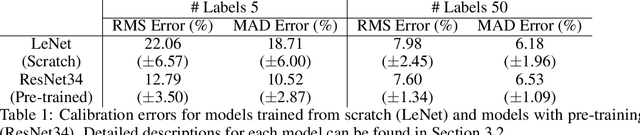
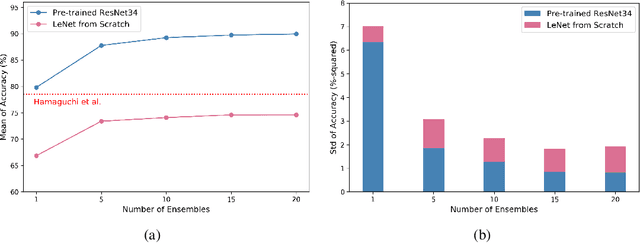
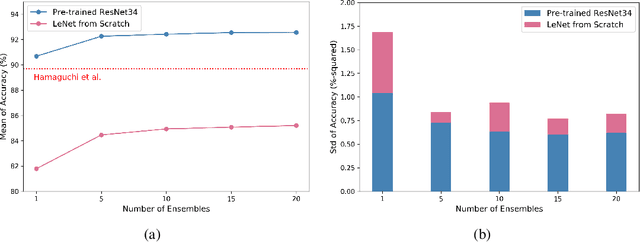
Automatic post-disaster damage detection using aerial imagery is crucial for quick assessment of damage caused by disaster and development of a recovery plan. The main problem preventing us from creating an applicable model in practice is that damaged (positive) examples we are trying to detect are much harder to obtain than undamaged (negative) examples, especially in short time. In this paper, we revisit the classical bootstrap aggregating approach in the context of modern transfer learning for data-efficient disaster damage detection. Unlike previous classical ensemble learning articles, our work points out the effectiveness of simple bagging in deep transfer learning that has been underestimated in the context of imbalanced classification. Benchmark results on the AIST Building Change Detection dataset show that our approach significantly outperforms existing methodologies, including the recently proposed disentanglement learning.
Deep Closed-Form Subspace Clustering
Aug 26, 2019
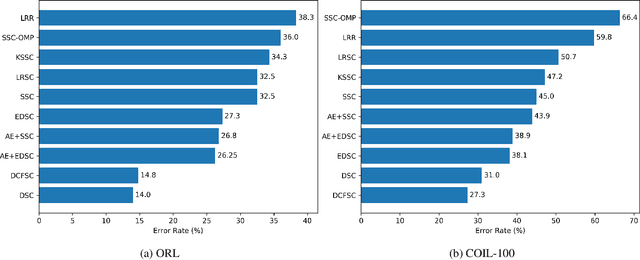
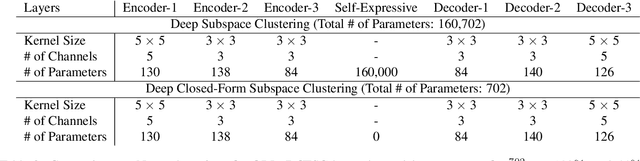
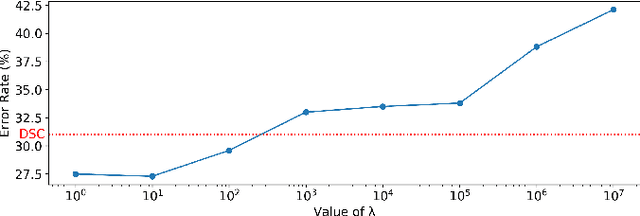
We propose Deep Closed-Form Subspace Clustering (DCFSC), a new embarrassingly simple model for subspace clustering with learning non-linear mapping. Compared with the previous deep subspace clustering (DSC) techniques, our DCFSC does not have any parameters at all for the self-expressive layer. Instead, DCFSC utilizes the implicit data-driven self-expressive layer derived from closed-form shallow auto-encoder. Moreover, DCFSC also has no complicated optimization scheme, unlike the other subspace clustering methods. With its extreme simplicity, DCFSC has significant memory-related benefits over the existing DSC method, especially on the large dataset. Several experiments showed that our DCFSC model had enough potential to be a new reference model for subspace clustering on large-scale high-dimensional dataset.
NL-LinkNet: Toward Lighter but More Accurate Road Extraction with Non-Local Operations
Aug 22, 2019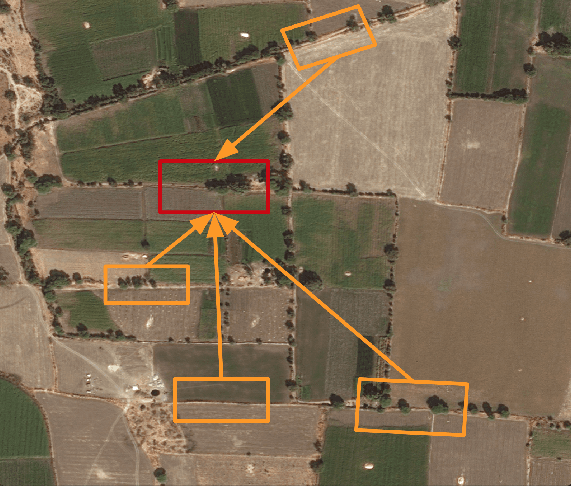
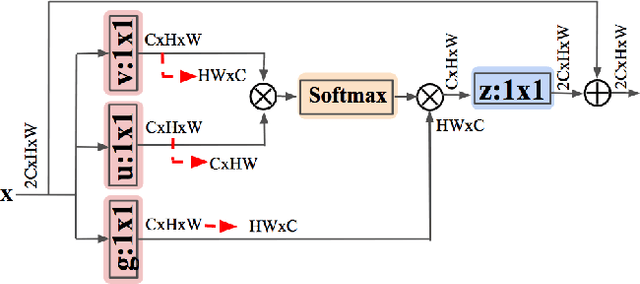
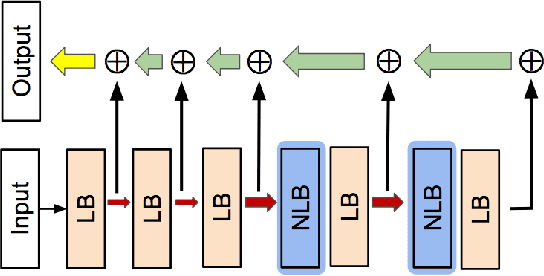
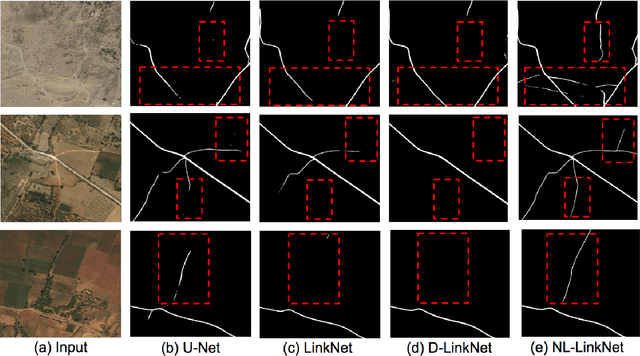
Road extraction from very high resolution satellite images is one of the most important topics in the field of remote sensing. For the road segmentation problem, spatial properties of the data can usually be captured using Convolutional Neural Networks. However, this approach only considers a few local neighborhoods at a time and has difficulty capturing long-range dependencies. In order to overcome the problem, we propose Non-Local LinkNet with non-local blocks that can grasp relations between global features. It enables each spatial feature point to refer to all other contextual information and results in more accurate road segmentation. In detail, our method achieved 65.00\% mIOU scores on the DeepGlobe 2018 Road Extraction Challenge dataset. Our best model outperformed D-LinkNet, 1st-ranked solution, by a significant gap of mIOU 0.88\% with much less number of parameters. We also present empirical analyses on proper usage of non-local blocks for the baseline model.
Bridging Adversarial Robustness and Gradient Interpretability
Apr 19, 2019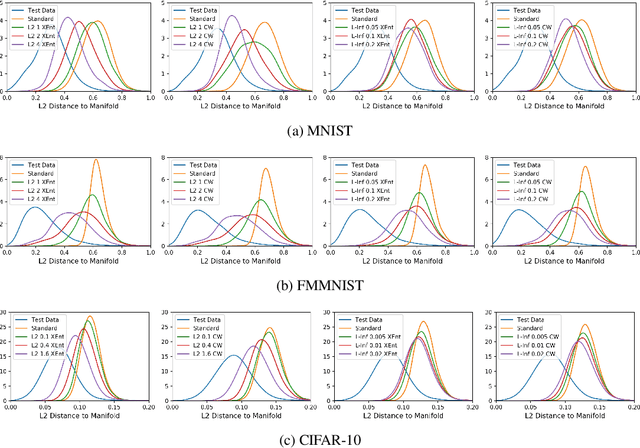

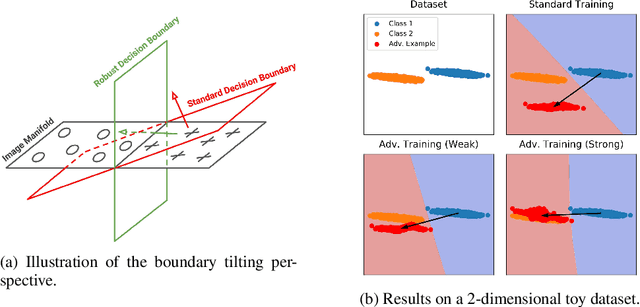

Adversarial training is a training scheme designed to counter adversarial attacks by augmenting the training dataset with adversarial examples. Surprisingly, several studies have observed that loss gradients from adversarially trained DNNs are visually more interpretable than those from standard DNNs. Although this phenomenon is interesting, there are only few works that have offered an explanation. In this paper, we attempted to bridge this gap between adversarial robustness and gradient interpretability. To this end, we identified that loss gradients from adversarially trained DNNs align better with human perception because adversarial training restricts gradients closer to the image manifold. We then demonstrated that adversarial training causes loss gradients to be quantitatively meaningful. Finally, we showed that under the adversarial training framework, there exists an empirical trade-off between test accuracy and loss gradient interpretability and proposed two potential approaches to resolving this trade-off.
Why are Saliency Maps Noisy? Cause of and Solution to Noisy Saliency Maps
Feb 20, 2019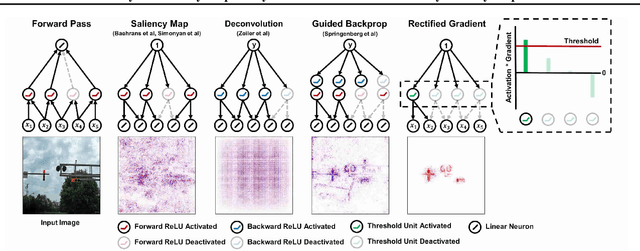
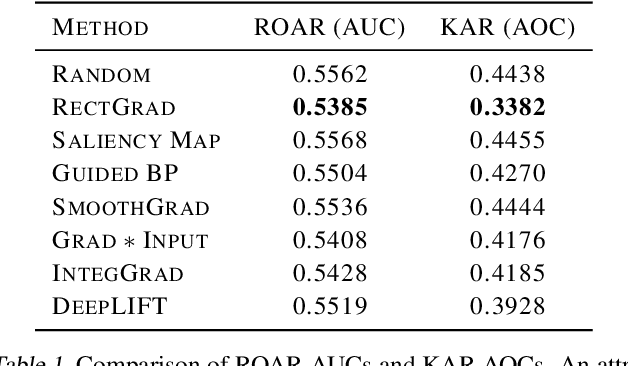

Saliency Map, the gradient of the score function with respect to the input, is the most basic technique for interpreting deep neural network decisions. However, saliency maps are often visually noisy. Although several hypotheses were proposed to account for this phenomenon, there are few works that provide rigorous analyses of noisy saliency maps. In this paper, we identify that noise occurs in saliency maps when irrelevant features pass through ReLU activation functions. Then we propose Rectified Gradient, a method that solves this problem through layer-wise thresholding during backpropagation. Experiments with neural networks trained on CIFAR-10 and ImageNet showed effectiveness of our method and its superiority to other attribution methods.
Domain Adaptive Generation of Aircraft on Satellite Imagery via Simulated and Unsupervised Learning
Jun 08, 2018


Object detection and classification for aircraft are the most important tasks in the satellite image analysis. The success of modern detection and classification methods has been based on machine learning and deep learning. One of the key requirements for those learning processes is huge data to train. However, there is an insufficient portion of aircraft since the targets are on military action and oper- ation. Considering the characteristics of satellite imagery, this paper attempts to provide a framework of the simulated and unsupervised methodology without any additional su- pervision or physical assumptions. Finally, the qualitative and quantitative analysis revealed a potential to replenish insufficient data for machine learning platform for satellite image analysis.
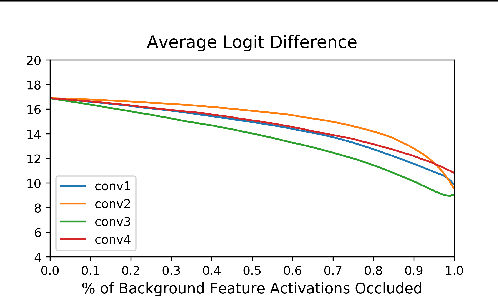
Noise-adding Methods of Saliency Map as Series of Higher Order Partial Derivative
Jun 08, 2018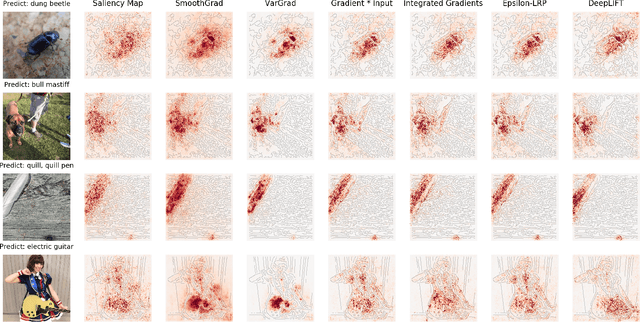

SmoothGrad and VarGrad are techniques that enhance the empirical quality of standard saliency maps by adding noise to input. However, there were few works that provide a rigorous theoretical interpretation of those methods. We analytically formalize the result of these noise-adding methods. As a result, we observe two interesting results from the existing noise-adding methods. First, SmoothGrad does not make the gradient of the score function smooth. Second, VarGrad is independent of the gradient of the score function. We believe that our findings provide a clue to reveal the relationship between local explanation methods of deep neural networks and higher-order partial derivatives of the score function.
On reproduction of On the regularization of Wasserstein GANs
Dec 16, 2017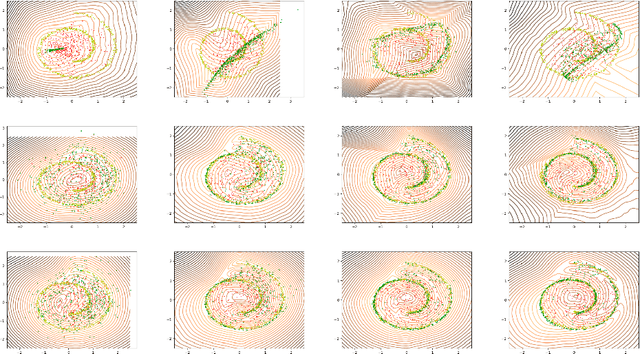



This report has several purposes. First, our report is written to investigate the reproducibility of the submitted paper On the regularization of Wasserstein GANs (2018). Second, among the experiments performed in the submitted paper, five aspects were emphasized and reproduced: learning speed, stability, robustness against hyperparameter, estimating the Wasserstein distance, and various sampling method. Finally, we identify which parts of the contribution can be reproduced, and at what cost in terms of resources. All source code for reproduction is open to the public.