 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRHINO: Rotated DETR with Dynamic Denoising via Hungarian Matching for Oriented Object Detection
May 15, 2023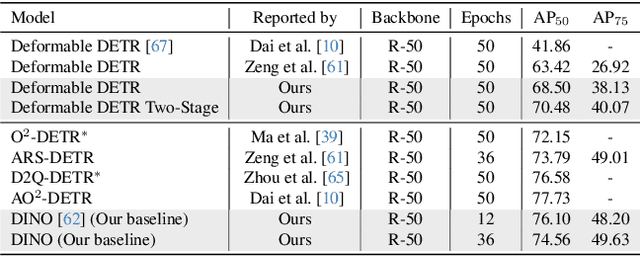
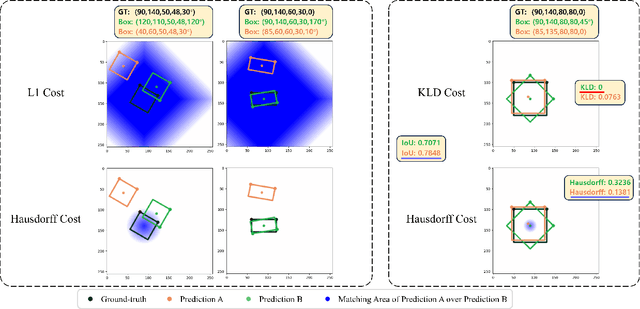

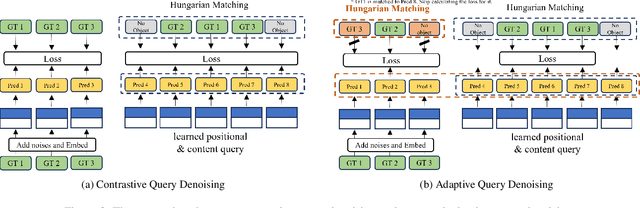
With the publication of DINO, a variant of the Detection Transformer (DETR), Detection Transformers are breaking the record in the object detection benchmark with the merits of their end-to-end design and scalability. However, the extension of DETR to oriented object detection has not been thoroughly studied although more benefits from its end-to-end architecture are expected such as removing NMS and anchor-related costs. In this paper, we propose a first strong DINO-based baseline for oriented object detection. We found that straightforward employment of DETRs for oriented object detection does not guarantee non-duplicate prediction, and propose a simple cost to mitigate this. Furthermore, we introduce a $\textit{dynamic denoising}$ strategy that uses Hungarian matching to filter redundant noised queries and $\textit{query alignment}$ to preserve matching consistency between Transformer decoder layers. Our proposed model outperforms previous rotated DETRs and other counterparts, achieving state-of-the-art performance in DOTA-v1.0/v1.5/v2.0, and DIOR-R benchmarks.
Deep Closed-Form Subspace Clustering
Aug 26, 2019
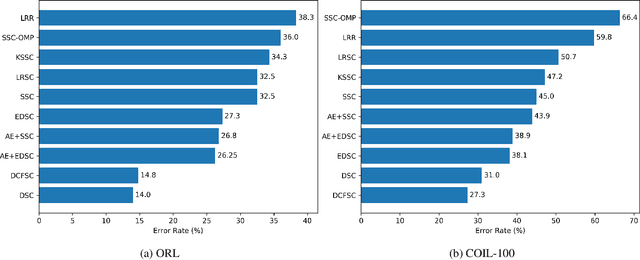
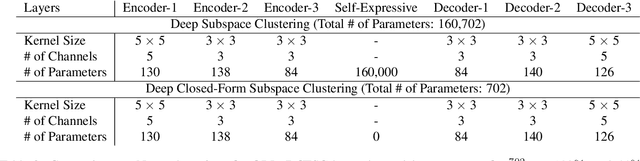
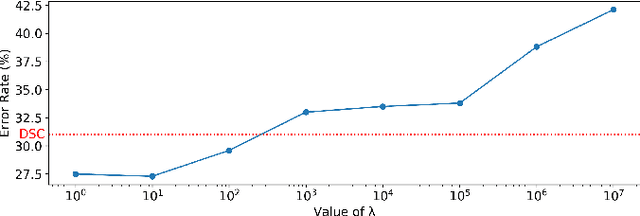
We propose Deep Closed-Form Subspace Clustering (DCFSC), a new embarrassingly simple model for subspace clustering with learning non-linear mapping. Compared with the previous deep subspace clustering (DSC) techniques, our DCFSC does not have any parameters at all for the self-expressive layer. Instead, DCFSC utilizes the implicit data-driven self-expressive layer derived from closed-form shallow auto-encoder. Moreover, DCFSC also has no complicated optimization scheme, unlike the other subspace clustering methods. With its extreme simplicity, DCFSC has significant memory-related benefits over the existing DSC method, especially on the large dataset. Several experiments showed that our DCFSC model had enough potential to be a new reference model for subspace clustering on large-scale high-dimensional dataset.
Why are Saliency Maps Noisy? Cause of and Solution to Noisy Saliency Maps
Feb 20, 2019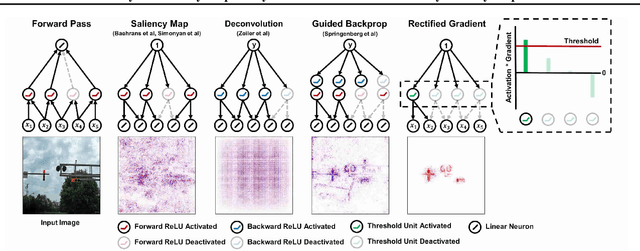
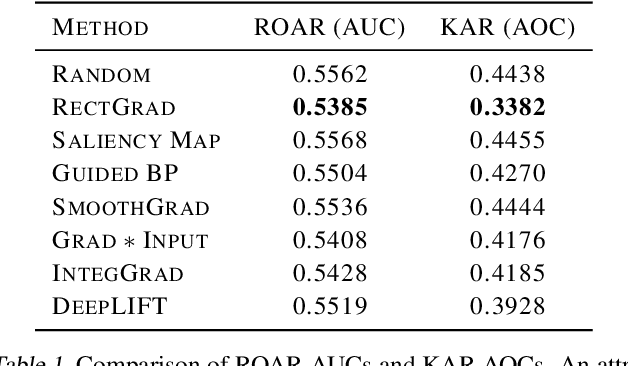
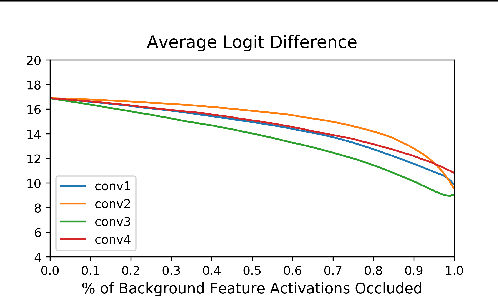

Saliency Map, the gradient of the score function with respect to the input, is the most basic technique for interpreting deep neural network decisions. However, saliency maps are often visually noisy. Although several hypotheses were proposed to account for this phenomenon, there are few works that provide rigorous analyses of noisy saliency maps. In this paper, we identify that noise occurs in saliency maps when irrelevant features pass through ReLU activation functions. Then we propose Rectified Gradient, a method that solves this problem through layer-wise thresholding during backpropagation. Experiments with neural networks trained on CIFAR-10 and ImageNet showed effectiveness of our method and its superiority to other attribution methods.
Noise-adding Methods of Saliency Map as Series of Higher Order Partial Derivative
Jun 08, 2018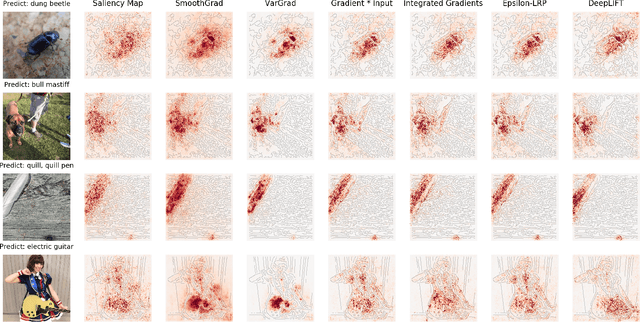

SmoothGrad and VarGrad are techniques that enhance the empirical quality of standard saliency maps by adding noise to input. However, there were few works that provide a rigorous theoretical interpretation of those methods. We analytically formalize the result of these noise-adding methods. As a result, we observe two interesting results from the existing noise-adding methods. First, SmoothGrad does not make the gradient of the score function smooth. Second, VarGrad is independent of the gradient of the score function. We believe that our findings provide a clue to reveal the relationship between local explanation methods of deep neural networks and higher-order partial derivatives of the score function.