 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributional Stability of Tangent-Linearized Gaussian Inference on Smooth Manifolds
Feb 22, 2026Gaussian inference on smooth manifolds is central to robotics, but exact marginalization and conditioning are generally non-Gaussian and geometry-dependent. We study tangent-linearized Gaussian inference and derive explicit non-asymptotic $W_2$ stability bounds for projection marginalization and surface-measure conditioning. The bounds separate local second-order geometric distortion from nonlocal tail leakage and, for Gaussian inputs, yield closed-form diagnostics from $(μ,Σ)$ and curvature/reach surrogates. Circle and planar-pushing experiments validate the predicted calibration transition near $\sqrt{\|Σ\|_{\mathrm{op}}}/R\approx 1/6$ and indicate that normal-direction uncertainty is the dominant failure mode when locality breaks. These diagnostics provide practical triggers for switching from single-chart linearization to multi-chart or sample-based manifold inference.
You Only Pose Once: A Minimalist's Detection Transformer for Monocular RGB Category-level 9D Multi-Object Pose Estimation
Aug 20, 2025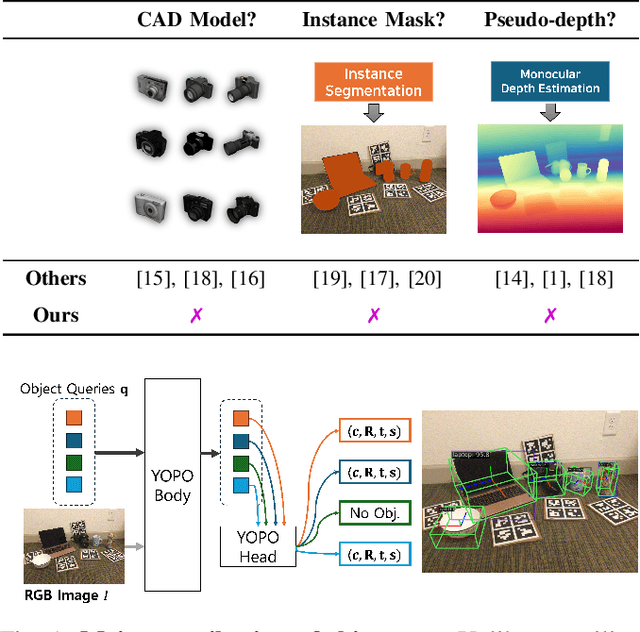
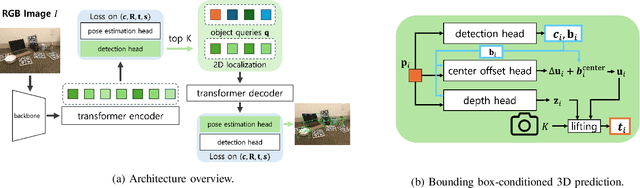

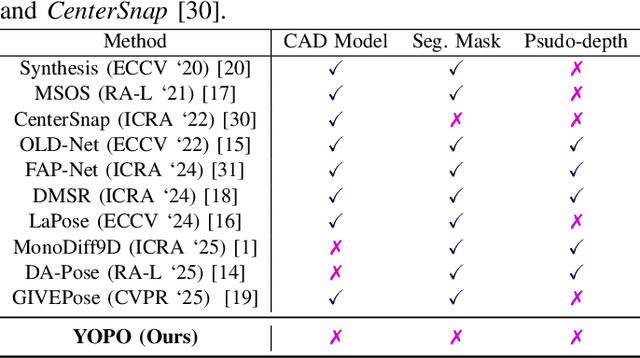
Accurately recovering the full 9-DoF pose of unseen instances within specific categories from a single RGB image remains a core challenge for robotics and automation. Most existing solutions still rely on pseudo-depth, CAD models, or multi-stage cascades that separate 2D detection from pose estimation. Motivated by the need for a simpler, RGB-only alternative that learns directly at the category level, we revisit a longstanding question: Can object detection and 9-DoF pose estimation be unified with high performance, without any additional data? We show that they can with our method, YOPO, a single-stage, query-based framework that treats category-level 9-DoF estimation as a natural extension of 2D detection. YOPO augments a transformer detector with a lightweight pose head, a bounding-box-conditioned translation module, and a 6D-aware Hungarian matching cost. The model is trained end-to-end only with RGB images and category-level pose labels. Despite its minimalist design, YOPO sets a new state of the art on three benchmarks. On the REAL275 dataset, it achieves 79.6% $\rm{IoU}_{50}$ and 54.1% under the $10^\circ$$10{\rm{cm}}$ metric, surpassing prior RGB-only methods and closing much of the gap to RGB-D systems. The code, models, and additional qualitative results can be found on our project.
Masked Autoregressive Model for Weather Forecasting
Sep 30, 2024The growing impact of global climate change amplifies the need for accurate and reliable weather forecasting. Traditional autoregressive approaches, while effective for temporal modeling, suffer from error accumulation in long-term prediction tasks. The lead time embedding method has been suggested to address this issue, but it struggles to maintain crucial correlations in atmospheric events. To overcome these challenges, we propose the Masked Autoregressive Model for Weather Forecasting (MAM4WF). This model leverages masked modeling, where portions of the input data are masked during training, allowing the model to learn robust spatiotemporal relationships by reconstructing the missing information. MAM4WF combines the advantages of both autoregressive and lead time embedding methods, offering flexibility in lead time modeling while iteratively integrating predictions. We evaluate MAM4WF across weather, climate forecasting, and video frame prediction datasets, demonstrating superior performance on five test datasets.
RHINO: Rotated DETR with Dynamic Denoising via Hungarian Matching for Oriented Object Detection
May 15, 2023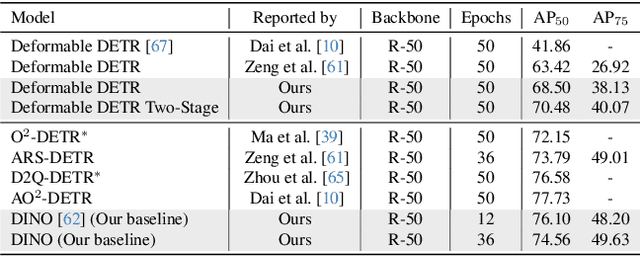
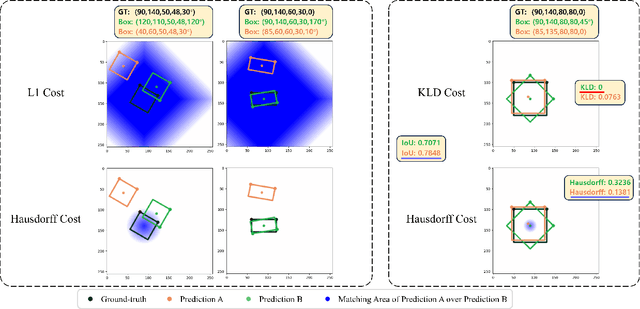

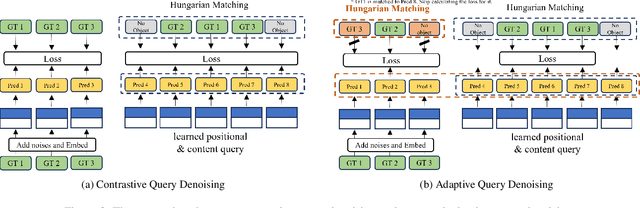
With the publication of DINO, a variant of the Detection Transformer (DETR), Detection Transformers are breaking the record in the object detection benchmark with the merits of their end-to-end design and scalability. However, the extension of DETR to oriented object detection has not been thoroughly studied although more benefits from its end-to-end architecture are expected such as removing NMS and anchor-related costs. In this paper, we propose a first strong DINO-based baseline for oriented object detection. We found that straightforward employment of DETRs for oriented object detection does not guarantee non-duplicate prediction, and propose a simple cost to mitigate this. Furthermore, we introduce a $\textit{dynamic denoising}$ strategy that uses Hungarian matching to filter redundant noised queries and $\textit{query alignment}$ to preserve matching consistency between Transformer decoder layers. Our proposed model outperforms previous rotated DETRs and other counterparts, achieving state-of-the-art performance in DOTA-v1.0/v1.5/v2.0, and DIOR-R benchmarks.
Implicit Stacked Autoregressive Model for Video Prediction
Mar 14, 2023



Future frame prediction has been approached through two primary methods: autoregressive and non-autoregressive. Autoregressive methods rely on the Markov assumption and can achieve high accuracy in the early stages of prediction when errors are not yet accumulated. However, their performance tends to decline as the number of time steps increases. In contrast, non-autoregressive methods can achieve relatively high performance but lack correlation between predictions for each time step. In this paper, we propose an Implicit Stacked Autoregressive Model for Video Prediction (IAM4VP), which is an implicit video prediction model that applies a stacked autoregressive method. Like non-autoregressive methods, stacked autoregressive methods use the same observed frame to estimate all future frames. However, they use their own predictions as input, similar to autoregressive methods. As the number of time steps increases, predictions are sequentially stacked in the queue. To evaluate the effectiveness of IAM4VP, we conducted experiments on three common future frame prediction benchmark datasets and weather\&climate prediction benchmark datasets. The results demonstrate that our proposed model achieves state-of-the-art performance.
Self-Pair: Synthesizing Changes from Single Source for Object Change Detection in Remote Sensing Imagery
Dec 20, 2022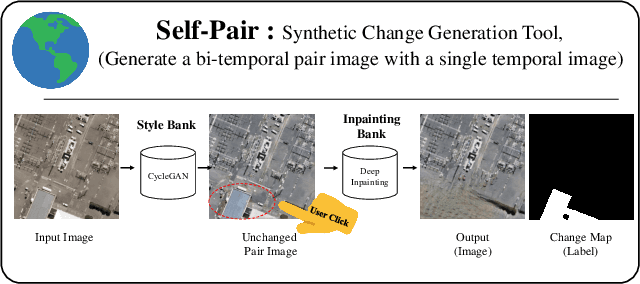
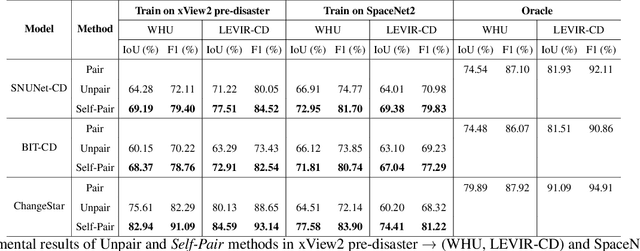
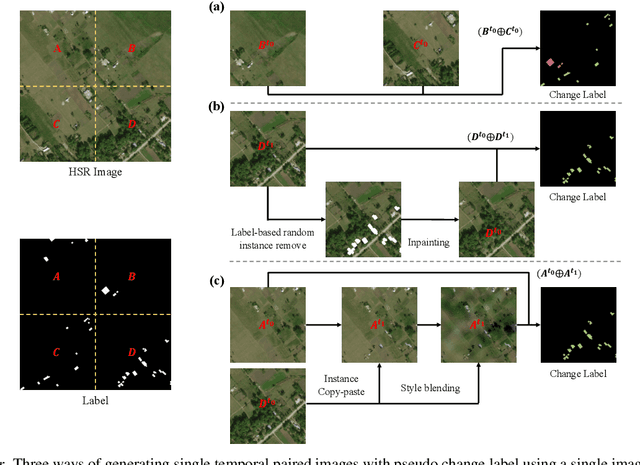
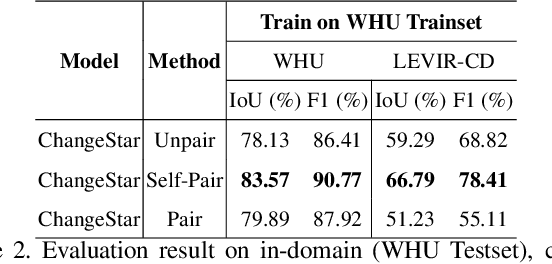
For change detection in remote sensing, constructing a training dataset for deep learning models is difficult due to the requirements of bi-temporal supervision. To overcome this issue, single-temporal supervision which treats change labels as the difference of two semantic masks has been proposed. This novel method trains a change detector using two spatially unrelated images with corresponding semantic labels such as building. However, training on unpaired datasets could confuse the change detector in the case of pixels that are labeled unchanged but are visually significantly different. In order to maintain the visual similarity in unchanged area, in this paper, we emphasize that the change originates from the source image and show that manipulating the source image as an after-image is crucial to the performance of change detection. Extensive experiments demonstrate the importance of maintaining visual information between pre- and post-event images, and our method outperforms existing methods based on single-temporal supervision. code is available at https://github.com/seominseok0429/Self-Pair-for-Change-Detection.