 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy are Saliency Maps Noisy? Cause of and Solution to Noisy Saliency Maps
Feb 20, 2019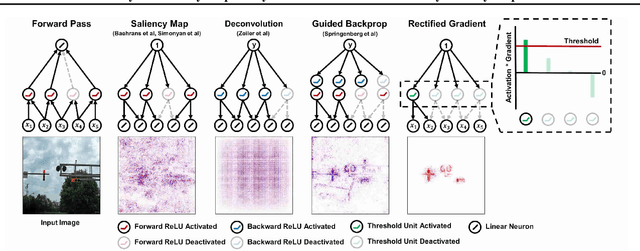
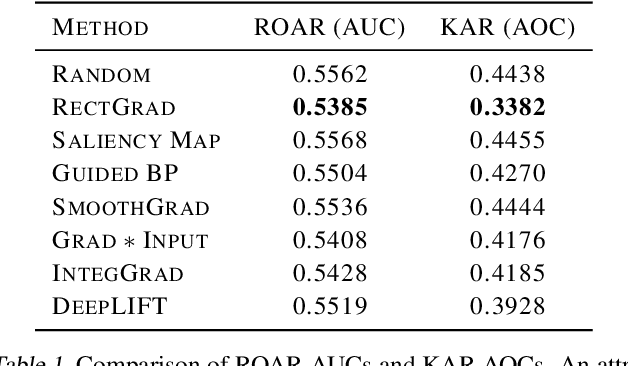
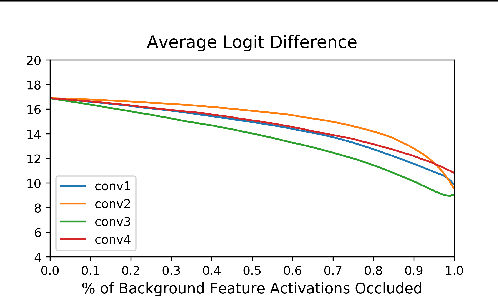

Saliency Map, the gradient of the score function with respect to the input, is the most basic technique for interpreting deep neural network decisions. However, saliency maps are often visually noisy. Although several hypotheses were proposed to account for this phenomenon, there are few works that provide rigorous analyses of noisy saliency maps. In this paper, we identify that noise occurs in saliency maps when irrelevant features pass through ReLU activation functions. Then we propose Rectified Gradient, a method that solves this problem through layer-wise thresholding during backpropagation. Experiments with neural networks trained on CIFAR-10 and ImageNet showed effectiveness of our method and its superiority to other attribution methods.
Noise-adding Methods of Saliency Map as Series of Higher Order Partial Derivative
Jun 08, 2018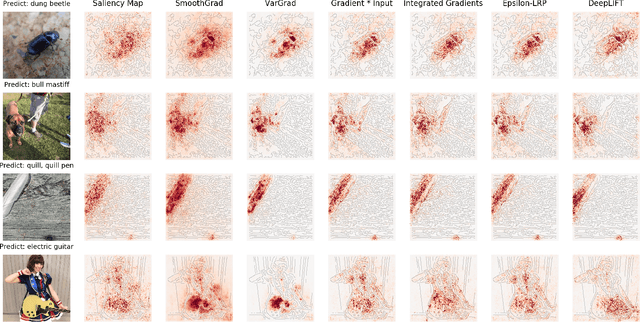

SmoothGrad and VarGrad are techniques that enhance the empirical quality of standard saliency maps by adding noise to input. However, there were few works that provide a rigorous theoretical interpretation of those methods. We analytically formalize the result of these noise-adding methods. As a result, we observe two interesting results from the existing noise-adding methods. First, SmoothGrad does not make the gradient of the score function smooth. Second, VarGrad is independent of the gradient of the score function. We believe that our findings provide a clue to reveal the relationship between local explanation methods of deep neural networks and higher-order partial derivatives of the score function.