 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeK-EXAONE Technical Report
Jan 05, 2026This technical report presents K-EXAONE, a large-scale multilingual language model developed by LG AI Research. K-EXAONE is built on a Mixture-of-Experts architecture with 236B total parameters, activating 23B parameters during inference. It supports a 256K-token context window and covers six languages: Korean, English, Spanish, German, Japanese, and Vietnamese. We evaluate K-EXAONE on a comprehensive benchmark suite spanning reasoning, agentic, general, Korean, and multilingual abilities. Across these evaluations, K-EXAONE demonstrates performance comparable to open-weight models of similar size. K-EXAONE, designed to advance AI for a better life, is positioned as a powerful proprietary AI foundation model for a wide range of industrial and research applications.
IF-MDM: Implicit Face Motion Diffusion Model for High-Fidelity Realtime Talking Head Generation
Dec 05, 2024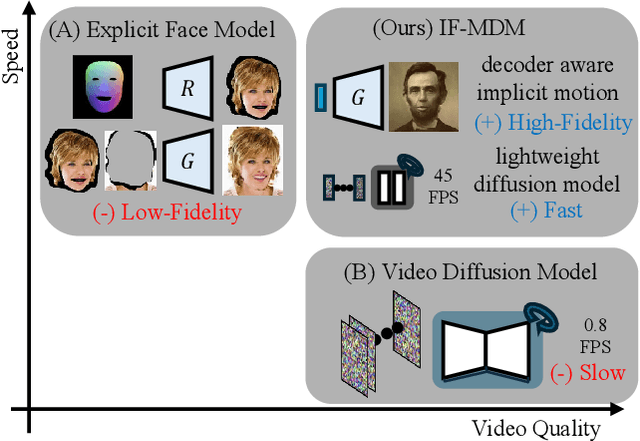

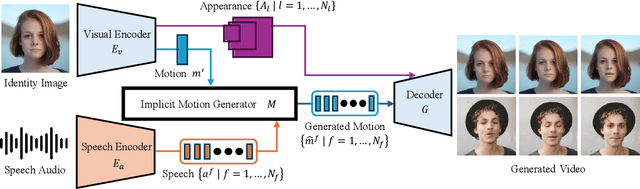

We introduce a novel approach for high-resolution talking head generation from a single image and audio input. Prior methods using explicit face models, like 3D morphable models (3DMM) and facial landmarks, often fall short in generating high-fidelity videos due to their lack of appearance-aware motion representation. While generative approaches such as video diffusion models achieve high video quality, their slow processing speeds limit practical application. Our proposed model, Implicit Face Motion Diffusion Model (IF-MDM), employs implicit motion to encode human faces into appearance-aware compressed facial latents, enhancing video generation. Although implicit motion lacks the spatial disentanglement of explicit models, which complicates alignment with subtle lip movements, we introduce motion statistics to help capture fine-grained motion information. Additionally, our model provides motion controllability to optimize the trade-off between motion intensity and visual quality during inference. IF-MDM supports real-time generation of 512x512 resolution videos at up to 45 frames per second (fps). Extensive evaluations demonstrate its superior performance over existing diffusion and explicit face models. The code will be released publicly, available alongside supplementary materials. The video results can be found on https://bit.ly/ifmdm_supplementary.
NTIRE 2020 Challenge on Perceptual Extreme Super-Resolution: Methods and Results
May 03, 2020
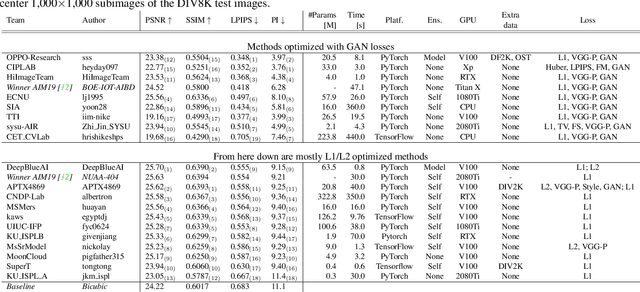

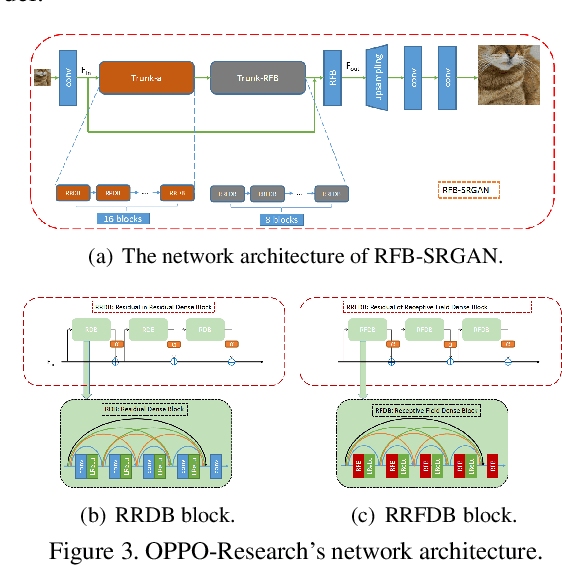
This paper reviews the NTIRE 2020 challenge on perceptual extreme super-resolution with focus on proposed solutions and results. The challenge task was to super-resolve an input image with a magnification factor 16 based on a set of prior examples of low and corresponding high resolution images. The goal is to obtain a network design capable to produce high resolution results with the best perceptual quality and similar to the ground truth. The track had 280 registered participants, and 19 teams submitted the final results. They gauge the state-of-the-art in single image super-resolution.