 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMirage2Matter: A Physically Grounded Gaussian World Model from Video
Jan 24, 2026The scalability of embodied intelligence is fundamentally constrained by the scarcity of real-world interaction data. While simulation platforms provide a promising alternative, existing approaches often suffer from a substantial visual and physical gap to real environments and rely on expensive sensors, precise robot calibration, or depth measurements, limiting their practicality at scale. We present Simulate Anything, a graphics-driven world modeling and simulation framework that enables efficient generation of high-fidelity embodied training data using only multi-view environment videos and off-the-shelf assets. Our approach reconstructs real-world environments into a photorealistic scene representation using 3D Gaussian Splatting (3DGS), seamlessly capturing fine-grained geometry and appearance from video. We then leverage generative models to recover a physically realistic representation and integrate it into a simulation environment via a precision calibration target, enabling accurate scale alignment between the reconstructed scene and the real world. Together, these components provide a unified, editable, and physically grounded world model. Vision Language Action (VLA) models trained on our simulated data achieve strong zero-shot performance on downstream tasks, matching or even surpassing results obtained with real-world data, highlighting the potential of reconstruction-driven world modeling for scalable and practical embodied intelligence training.
A Brain-inspired Embodied Intelligence for Fluid and Fast Reflexive Robotics Control
Jan 21, 2026Recent advances in embodied intelligence have leveraged massive scaling of data and model parameters to master natural-language command following and multi-task control. In contrast, biological systems demonstrate an innate ability to acquire skills rapidly from sparse experience. Crucially, current robotic policies struggle to replicate the dynamic stability, reflexive responsiveness, and temporal memory inherent in biological motion. Here we present Neuromorphic Vision-Language-Action (NeuroVLA), a framework that mimics the structural organization of the bio-nervous system between the cortex, cerebellum, and spinal cord. We adopt a system-level bio-inspired design: a high-level model plans goals, an adaptive cerebellum module stabilizes motion using high-frequency sensors feedback, and a bio-inspired spinal layer executes lightning-fast actions generation. NeuroVLA represents the first deployment of a neuromorphic VLA on physical robotics, achieving state-of-the-art performance. We observe the emergence of biological motor characteristics without additional data or special guidance: it stops the shaking in robotic arms, saves significant energy(only 0.4w on Neuromorphic Processor), shows temporal memory ability and triggers safety reflexes in less than 20 milliseconds.
SURPRISE3D: A Dataset for Spatial Understanding and Reasoning in Complex 3D Scenes
Jul 10, 2025The integration of language and 3D perception is critical for embodied AI and robotic systems to perceive, understand, and interact with the physical world. Spatial reasoning, a key capability for understanding spatial relationships between objects, remains underexplored in current 3D vision-language research. Existing datasets often mix semantic cues (e.g., object name) with spatial context, leading models to rely on superficial shortcuts rather than genuinely interpreting spatial relationships. To address this gap, we introduce S\textsc{urprise}3D, a novel dataset designed to evaluate language-guided spatial reasoning segmentation in complex 3D scenes. S\textsc{urprise}3D consists of more than 200k vision language pairs across 900+ detailed indoor scenes from ScanNet++ v2, including more than 2.8k unique object classes. The dataset contains 89k+ human-annotated spatial queries deliberately crafted without object name, thereby mitigating shortcut biases in spatial understanding. These queries comprehensively cover various spatial reasoning skills, such as relative position, narrative perspective, parametric perspective, and absolute distance reasoning. Initial benchmarks demonstrate significant challenges for current state-of-the-art expert 3D visual grounding methods and 3D-LLMs, underscoring the necessity of our dataset and the accompanying 3D Spatial Reasoning Segmentation (3D-SRS) benchmark suite. S\textsc{urprise}3D and 3D-SRS aim to facilitate advancements in spatially aware AI, paving the way for effective embodied interaction and robotic planning. The code and datasets can be found in https://github.com/liziwennba/SUPRISE.
3DWG: 3D Weakly Supervised Visual Grounding via Category and Instance-Level Alignment
May 03, 2025The 3D weakly-supervised visual grounding task aims to localize oriented 3D boxes in point clouds based on natural language descriptions without requiring annotations to guide model learning. This setting presents two primary challenges: category-level ambiguity and instance-level complexity. Category-level ambiguity arises from representing objects of fine-grained categories in a highly sparse point cloud format, making category distinction challenging. Instance-level complexity stems from multiple instances of the same category coexisting in a scene, leading to distractions during grounding. To address these challenges, we propose a novel weakly-supervised grounding approach that explicitly differentiates between categories and instances. In the category-level branch, we utilize extensive category knowledge from a pre-trained external detector to align object proposal features with sentence-level category features, thereby enhancing category awareness. In the instance-level branch, we utilize spatial relationship descriptions from language queries to refine object proposal features, ensuring clear differentiation among objects. These designs enable our model to accurately identify target-category objects while distinguishing instances within the same category. Compared to previous methods, our approach achieves state-of-the-art performance on three widely used benchmarks: Nr3D, Sr3D, and ScanRef.
CMamba: Learned Image Compression with State Space Models
Feb 07, 2025Learned Image Compression (LIC) has explored various architectures, such as Convolutional Neural Networks (CNNs) and transformers, in modeling image content distributions in order to achieve compression effectiveness. However, achieving high rate-distortion performance while maintaining low computational complexity (\ie, parameters, FLOPs, and latency) remains challenging. In this paper, we propose a hybrid Convolution and State Space Models (SSMs) based image compression framework, termed \textit{CMamba}, to achieve superior rate-distortion performance with low computational complexity. Specifically, CMamba introduces two key components: a Content-Adaptive SSM (CA-SSM) module and a Context-Aware Entropy (CAE) module. First, we observed that SSMs excel in modeling overall content but tend to lose high-frequency details. In contrast, CNNs are proficient at capturing local details. Motivated by this, we propose the CA-SSM module that can dynamically fuse global content extracted by SSM blocks and local details captured by CNN blocks in both encoding and decoding stages. As a result, important image content is well preserved during compression. Second, our proposed CAE module is designed to reduce spatial and channel redundancies in latent representations after encoding. Specifically, our CAE leverages SSMs to parameterize the spatial content in latent representations. Benefiting from SSMs, CAE significantly improves spatial compression efficiency while reducing spatial content redundancies. Moreover, along the channel dimension, CAE reduces inter-channel redundancies of latent representations via an autoregressive manner, which can fully exploit prior knowledge from previous channels without sacrificing efficiency. Experimental results demonstrate that CMamba achieves superior rate-distortion performance.
Urban4D: Semantic-Guided 4D Gaussian Splatting for Urban Scene Reconstruction
Dec 04, 2024
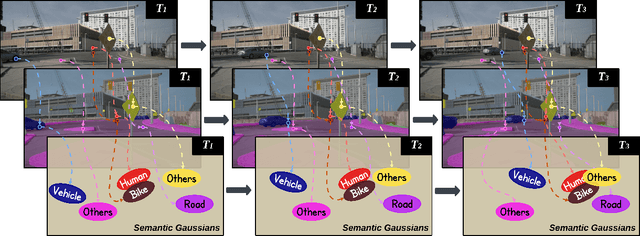

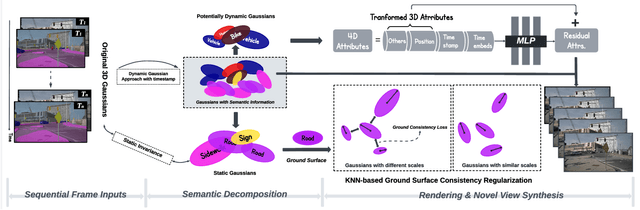
Reconstructing dynamic urban scenes presents significant challenges due to their intrinsic geometric structures and spatiotemporal dynamics. Existing methods that attempt to model dynamic urban scenes without leveraging priors on potentially moving regions often produce suboptimal results. Meanwhile, approaches based on manual 3D annotations yield improved reconstruction quality but are impractical due to labor-intensive labeling. In this paper, we revisit the potential of 2D semantic maps for classifying dynamic and static Gaussians and integrating spatial and temporal dimensions for urban scene representation. We introduce Urban4D, a novel framework that employs a semantic-guided decomposition strategy inspired by advances in deep 2D semantic map generation. Our approach distinguishes potentially dynamic objects through reliable semantic Gaussians. To explicitly model dynamic objects, we propose an intuitive and effective 4D Gaussian splatting (4DGS) representation that aggregates temporal information through learnable time embeddings for each Gaussian, predicting their deformations at desired timestamps using a multilayer perceptron (MLP). For more accurate static reconstruction, we also design a k-nearest neighbor (KNN)-based consistency regularization to handle the ground surface due to its low-texture characteristic. Extensive experiments on real-world datasets demonstrate that Urban4D not only achieves comparable or better quality than previous state-of-the-art methods but also effectively captures dynamic objects while maintaining high visual fidelity for static elements.
Technical Report for SoccerNet Challenge 2022 -- Replay Grounding Task
Oct 31, 2024



In order to make full use of video information, we transform the replay grounding problem into a video action location problem. We apply a unified network Faster-TAD proposed by us for temporal action detection to get the results of replay grounding. Finally, by observing the data distribution of the training data, we refine the output of the model to get the final submission.
Technical Report for ActivityNet Challenge 2022 -- Temporal Action Localization
Oct 31, 2024In the task of temporal action localization of ActivityNet-1.3 datasets, we propose to locate the temporal boundaries of each action and predict action class in untrimmed videos. We first apply VideoSwinTransformer as feature extractor to extract different features. Then we apply a unified network following Faster-TAD to simultaneously obtain proposals and semantic labels. Last, we ensemble the results of different temporal action detection models which complement each other. Faster-TAD simplifies the pipeline of TAD and gets remarkable performance, obtaining comparable results as those of multi-step approaches.
Training-Free Robust Interactive Video Object Segmentation
Jun 08, 2024



Interactive video object segmentation is a crucial video task, having various applications from video editing to data annotating. However, current approaches struggle to accurately segment objects across diverse domains. Recently, Segment Anything Model (SAM) introduces interactive visual prompts and demonstrates impressive performance across different domains. In this paper, we propose a training-free prompt tracking framework for interactive video object segmentation (I-PT), leveraging the powerful generalization of SAM. Although point tracking efficiently captures the pixel-wise information of objects in a video, points tend to be unstable when tracked over a long period, resulting in incorrect segmentation. Towards fast and robust interaction, we jointly adopt sparse points and boxes tracking, filtering out unstable points and capturing object-wise information. To better integrate reference information from multiple interactions, we introduce a cross-round space-time module (CRSTM), which adaptively aggregates mask features from previous rounds and frames, enhancing the segmentation stability. Our framework has demonstrated robust zero-shot video segmentation results on popular VOS datasets with interaction types, including DAVIS 2017, YouTube-VOS 2018, and MOSE 2023, maintaining a good tradeoff between performance and interaction time.
RoboMamba: Multimodal State Space Model for Efficient Robot Reasoning and Manipulation
Jun 06, 2024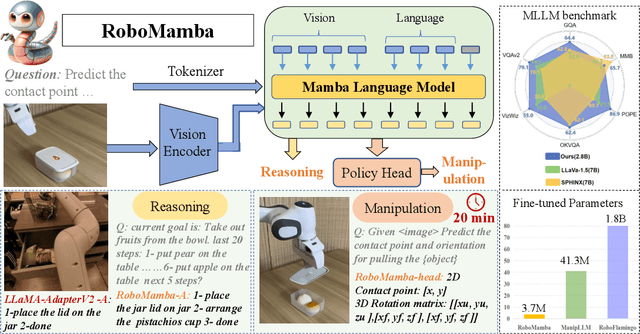



A fundamental objective in robot manipulation is to enable models to comprehend visual scenes and execute actions. Although existing robot Multimodal Large Language Models (MLLMs) can handle a range of basic tasks, they still face challenges in two areas: 1) inadequate reasoning ability to tackle complex tasks, and 2) high computational costs for MLLM fine-tuning and inference. The recently proposed state space model (SSM) known as Mamba demonstrates promising capabilities in non-trivial sequence modeling with linear inference complexity. Inspired by this, we introduce RoboMamba, an end-to-end robotic MLLM that leverages the Mamba model to deliver both robotic reasoning and action capabilities, while maintaining efficient fine-tuning and inference. Specifically, we first integrate the vision encoder with Mamba, aligning visual data with language embedding through co-training, empowering our model with visual common sense and robot-related reasoning. To further equip RoboMamba with action pose prediction abilities, we explore an efficient fine-tuning strategy with a simple policy head. We find that once RoboMamba possesses sufficient reasoning capability, it can acquire manipulation skills with minimal fine-tuning parameters (0.1\% of the model) and time (20 minutes). In experiments, RoboMamba demonstrates outstanding reasoning capabilities on general and robotic evaluation benchmarks. Meanwhile, our model showcases impressive pose prediction results in both simulation and real-world experiments, achieving inference speeds 7 times faster than existing robot MLLMs. Our project web page: https://sites.google.com/view/robomamba-web