 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmni-RRM: Advancing Omni Reward Modeling via Automatic Rubric-Grounded Preference Synthesis
Jan 31, 2026Multimodal large language models (MLLMs) have shown remarkable capabilities, yet their performance is often capped by the coarse nature of existing alignment techniques. A critical bottleneck remains the lack of effective reward models (RMs): existing RMs are predominantly vision-centric, return opaque scalar scores, and rely on costly human annotations. We introduce \textbf{Omni-RRM}, the first open-source rubric-grounded reward model that produces structured, multi-dimension preference judgments with dimension-wise justifications across \textbf{text, image, video, and audio}. At the core of our approach is \textbf{Omni-Preference}, a large-scale dataset built via a fully automated pipeline: we synthesize candidate response pairs by contrasting models of different capabilities, and use strong teacher models to \emph{reconcile and filter} preferences while providing a modality-aware \emph{rubric-grounded rationale} for each pair. This eliminates the need for human-labeled training preferences. Omni-RRM is trained in two stages: supervised fine-tuning to learn the rubric-grounded outputs, followed by reinforcement learning (GRPO) to sharpen discrimination on difficult, low-contrast pairs. Comprehensive evaluations show that Omni-RRM achieves state-of-the-art accuracy on video (80.2\% on ShareGPT-V) and audio (66.8\% on Audio-HH-RLHF) benchmarks, and substantially outperforms existing open-source RMs on image tasks, with a 17.7\% absolute gain over its base model on overall accuracy. Omni-RRM also improves downstream performance via Best-of-$N$ selection and transfers to text-only preference benchmarks. Our data, code, and models are available at https://anonymous.4open.science/r/Omni-RRM-CC08.
Unlocking the Address Book: Dissecting the Sparse Semantic Structure of LLM Key-Value Caches via Sparse Autoencoders
Dec 11, 2025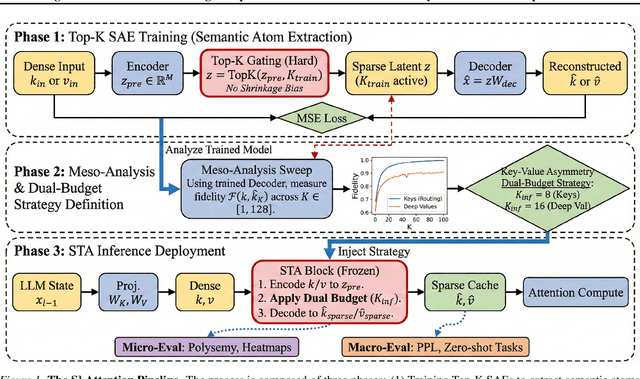

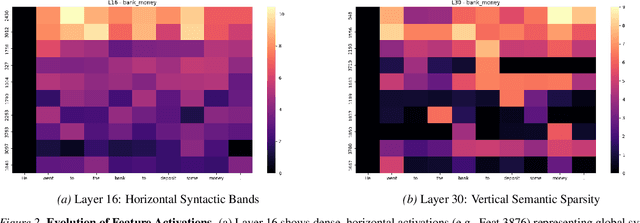

The Key-Value (KV) cache is the primary memory bottleneck in long-context Large Language Models, yet it is typically treated as an opaque numerical tensor. In this work, we propose \textbf{STA-Attention}, a framework that utilizes Top-K Sparse Autoencoders (SAEs) to decompose the KV cache into interpretable ``semantic atoms.'' Unlike standard $L_1$-regularized SAEs, our Top-K approach eliminates shrinkage bias, preserving the precise dot-product geometry required for attention. Our analysis uncovers a fundamental \textbf{Key-Value Asymmetry}: while Key vectors serve as highly sparse routers dominated by a ``Semantic Elbow,'' deep Value vectors carry dense content payloads requiring a larger budget. Based on this structure, we introduce a Dual-Budget Strategy that selectively preserves the most informative semantic components while filtering representational noise. Experiments on Yi-6B, Mistral-7B, Qwen2.5-32B, and others show that our semantic reconstructions maintain perplexity and zero-shot performance comparable to the original models, effectively bridging the gap between mechanistic interpretability and faithful attention modeling.
Beyond Darkness: Thermal-Supervised 3D Gaussian Splatting for Low-Light Novel View Synthesis
Nov 17, 2025Under extremely low-light conditions, novel view synthesis (NVS) faces severe degradation in terms of geometry, color consistency, and radiometric stability. Standard 3D Gaussian Splatting (3DGS) pipelines fail when applied directly to underexposed inputs, as independent enhancement across views causes illumination inconsistencies and geometric distortion. To address this, we present DTGS, a unified framework that tightly couples Retinex-inspired illumination decomposition with thermal-guided 3D Gaussian Splatting for illumination-invariant reconstruction. Unlike prior approaches that treat enhancement as a pre-processing step, DTGS performs joint optimization across enhancement, geometry, and thermal supervision through a cyclic enhancement-reconstruction mechanism. A thermal supervisory branch stabilizes both color restoration and geometry learning by dynamically balancing enhancement, structural, and thermal losses. Moreover, a Retinex-based decomposition module embedded within the 3DGS loop provides physically interpretable reflectance-illumination separation, ensuring consistent color and texture across viewpoints. To evaluate our method, we construct RGBT-LOW, a new multi-view low-light thermal dataset capturing severe illumination degradation. Extensive experiments show that DTGS significantly outperforms existing low-light enhancement and 3D reconstruction baselines, achieving superior radiometric consistency, geometric fidelity, and color stability under extreme illumination.
GUI Knowledge Bench: Revealing the Knowledge Gap Behind VLM Failures in GUI Tasks
Oct 30, 2025Large vision language models (VLMs) have advanced graphical user interface (GUI) task automation but still lag behind humans. We hypothesize this gap stems from missing core GUI knowledge, which existing training schemes (such as supervised fine tuning and reinforcement learning) alone cannot fully address. By analyzing common failure patterns in GUI task execution, we distill GUI knowledge into three dimensions: (1) interface perception, knowledge about recognizing widgets and system states; (2) interaction prediction, knowledge about reasoning action state transitions; and (3) instruction understanding, knowledge about planning, verifying, and assessing task completion progress. We further introduce GUI Knowledge Bench, a benchmark with multiple choice and yes/no questions across six platforms (Web, Android, MacOS, Windows, Linux, IOS) and 292 applications. Our evaluation shows that current VLMs identify widget functions but struggle with perceiving system states, predicting actions, and verifying task completion. Experiments on real world GUI tasks further validate the close link between GUI knowledge and task success. By providing a structured framework for assessing GUI knowledge, our work supports the selection of VLMs with greater potential prior to downstream training and provides insights for building more capable GUI agents.
SCOMatch: Alleviating Overtrusting in Open-set Semi-supervised Learning
Sep 26, 2024



Open-set semi-supervised learning (OSSL) leverages practical open-set unlabeled data, comprising both in-distribution (ID) samples from seen classes and out-of-distribution (OOD) samples from unseen classes, for semi-supervised learning (SSL). Prior OSSL methods initially learned the decision boundary between ID and OOD with labeled ID data, subsequently employing self-training to refine this boundary. These methods, however, suffer from the tendency to overtrust the labeled ID data: the scarcity of labeled data caused the distribution bias between the labeled samples and the entire ID data, which misleads the decision boundary to overfit. The subsequent self-training process, based on the overfitted result, fails to rectify this problem. In this paper, we address the overtrusting issue by treating OOD samples as an additional class, forming a new SSL process. Specifically, we propose SCOMatch, a novel OSSL method that 1) selects reliable OOD samples as new labeled data with an OOD memory queue and a corresponding update strategy and 2) integrates the new SSL process into the original task through our Simultaneous Close-set and Open-set self-training. SCOMatch refines the decision boundary of ID and OOD classes across the entire dataset, thereby leading to improved results. Extensive experimental results show that SCOMatch significantly outperforms the state-of-the-art methods on various benchmarks. The effectiveness is further verified through ablation studies and visualization.
Generative Iris Prior Embedded Transformer for Iris Restoration
Jun 28, 2024



Iris restoration from complexly degraded iris images, aiming to improve iris recognition performance, is a challenging problem. Due to the complex degradation, directly training a convolutional neural network (CNN) without prior cannot yield satisfactory results. In this work, we propose a generative iris prior embedded Transformer model (Gformer), in which we build a hierarchical encoder-decoder network employing Transformer block and generative iris prior. First, we tame Transformer blocks to model long-range dependencies in target images. Second, we pretrain an iris generative adversarial network (GAN) to obtain the rich iris prior, and incorporate it into the iris restoration process with our iris feature modulator. Our experiments demonstrate that the proposed Gformer outperforms state-of-the-art methods. Besides, iris recognition performance has been significantly improved after applying Gformer.
* Our code is available at https://github.com/sawyercharlton/Gformer
GIEBench: Towards Holistic Evaluation of Group Identity-based Empathy for Large Language Models
Jun 24, 2024
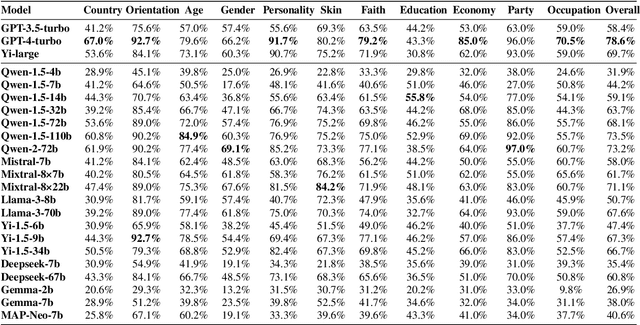

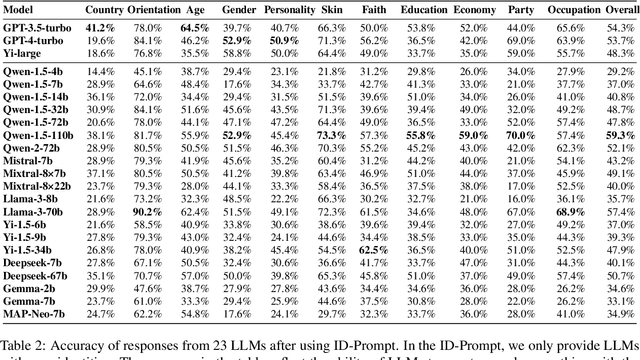
As large language models (LLMs) continue to develop and gain widespread application, the ability of LLMs to exhibit empathy towards diverse group identities and understand their perspectives is increasingly recognized as critical. Most existing benchmarks for empathy evaluation of LLMs focus primarily on universal human emotions, such as sadness and pain, often overlooking the context of individuals' group identities. To address this gap, we introduce GIEBench, a comprehensive benchmark that includes 11 identity dimensions, covering 97 group identities with a total of 999 single-choice questions related to specific group identities. GIEBench is designed to evaluate the empathy of LLMs when presented with specific group identities such as gender, age, occupation, and race, emphasizing their ability to respond from the standpoint of the identified group. This supports the ongoing development of empathetic LLM applications tailored to users with different identities. Our evaluation of 23 LLMs revealed that while these LLMs understand different identity standpoints, they fail to consistently exhibit equal empathy across these identities without explicit instructions to adopt those perspectives. This highlights the need for improved alignment of LLMs with diverse values to better accommodate the multifaceted nature of human identities. Our datasets are available at https://github.com/GIEBench/GIEBench.
From Obstacle to Opportunity: Enhancing Semi-supervised Learning with Synthetic Data
May 27, 2024



Semi-supervised learning (SSL) can utilize unlabeled data to enhance model performance. In recent years, with increasingly powerful generative models becoming available, a large number of synthetic images have been uploaded to public image sets. Therefore, when collecting unlabeled data from these sources, the inclusion of synthetic images is inevitable. This prompts us to consider the impact of unlabeled data mixed with real and synthetic images on SSL. In this paper, we set up a new task, Real and Synthetic hybrid SSL (RS-SSL), to investigate this problem. We discover that current SSL methods are unable to fully utilize synthetic data and are sometimes negatively affected. Then, by analyzing the issues caused by synthetic images, we propose a new SSL method, RSMatch, to tackle the RS-SSL problem. Extensive experimental results show that RSMatch can better utilize the synthetic data in unlabeled images to improve the SSL performance. The effectiveness is further verified through ablation studies and visualization.
CLIP model is an Efficient Online Lifelong Learner
May 24, 2024Online Lifelong Learning (OLL) addresses the challenge of learning from continuous and non-stationary data streams. Existing online lifelong learning methods based on image classification models often require preset conditions such as the total number of classes or maximum memory capacity, which hinders the realization of real never-ending learning and renders them impractical for real-world scenarios. In this work, we propose that vision-language models, such as Contrastive Language-Image Pretraining (CLIP), are more suitable candidates for online lifelong learning. We discover that maintaining symmetry between image and text is crucial during Parameter-Efficient Tuning (PET) for CLIP model in online lifelong learning. To this end, we introduce the Symmetric Image-Text (SIT) tuning strategy. We conduct extensive experiments on multiple lifelong learning benchmark datasets and elucidate the effectiveness of SIT through gradient analysis. Additionally, we assess the impact of lifelong learning on generalizability of CLIP and found that tuning the image encoder is beneficial for lifelong learning, while tuning the text encoder aids in zero-shot learning.
Rethinking Class-Incremental Learning from a Dynamic Imbalanced Learning Perspective
May 24, 2024



Deep neural networks suffer from catastrophic forgetting when continually learning new concepts. In this paper, we analyze this problem from a data imbalance point of view. We argue that the imbalance between old task and new task data contributes to forgetting of the old tasks. Moreover, the increasing imbalance ratio during incremental learning further aggravates the problem. To address the dynamic imbalance issue, we propose Uniform Prototype Contrastive Learning (UPCL), where uniform and compact features are learned. Specifically, we generate a set of non-learnable uniform prototypes before each task starts. Then we assign these uniform prototypes to each class and guide the feature learning through prototype contrastive learning. We also dynamically adjust the relative margin between old and new classes so that the feature distribution will be maintained balanced and compact. Finally, we demonstrate through extensive experiments that the proposed method achieves state-of-the-art performance on several benchmark datasets including CIFAR100, ImageNet100 and TinyImageNet.