 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDebiased Novel Category Discovering and Localization
Feb 29, 2024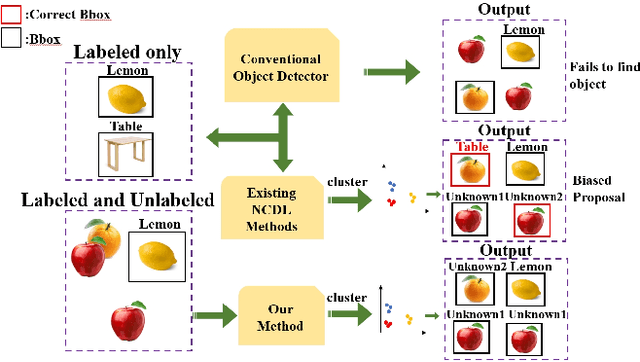

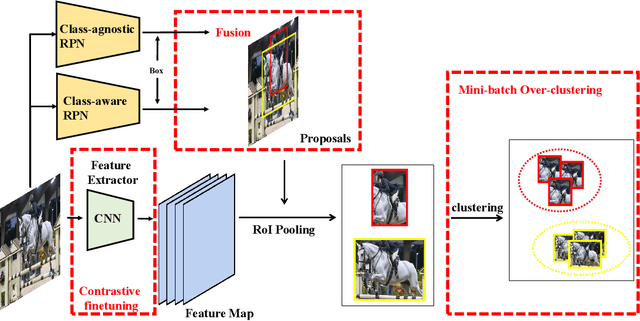

In recent years, object detection in deep learning has experienced rapid development. However, most existing object detection models perform well only on closed-set datasets, ignoring a large number of potential objects whose categories are not defined in the training set. These objects are often identified as background or incorrectly classified as pre-defined categories by the detectors. In this paper, we focus on the challenging problem of Novel Class Discovery and Localization (NCDL), aiming to train detectors that can detect the categories present in the training data, while also actively discover, localize, and cluster new categories. We analyze existing NCDL methods and identify the core issue: object detectors tend to be biased towards seen objects, and this leads to the neglect of unseen targets. To address this issue, we first propose an Debiased Region Mining (DRM) approach that combines class-agnostic Region Proposal Network (RPN) and class-aware RPN in a complementary manner. Additionally, we suggest to improve the representation network through semi-supervised contrastive learning by leveraging unlabeled data. Finally, we adopt a simple and efficient mini-batch K-means clustering method for novel class discovery. We conduct extensive experiments on the NCDL benchmark, and the results demonstrate that the proposed DRM approach significantly outperforms previous methods, establishing a new state-of-the-art.
A Survey for Foundation Models in Autonomous Driving
Feb 02, 2024The advent of foundation models has revolutionized the fields of natural language processing and computer vision, paving the way for their application in autonomous driving (AD). This survey presents a comprehensive review of more than 40 research papers, demonstrating the role of foundation models in enhancing AD. Large language models contribute to planning and simulation in AD, particularly through their proficiency in reasoning, code generation and translation. In parallel, vision foundation models are increasingly adapted for critical tasks such as 3D object detection and tracking, as well as creating realistic driving scenarios for simulation and testing. Multi-modal foundation models, integrating diverse inputs, exhibit exceptional visual understanding and spatial reasoning, crucial for end-to-end AD. This survey not only provides a structured taxonomy, categorizing foundation models based on their modalities and functionalities within the AD domain but also delves into the methods employed in current research. It identifies the gaps between existing foundation models and cutting-edge AD approaches, thereby charting future research directions and proposing a roadmap for bridging these gaps.
u-LLaVA: Unifying Multi-Modal Tasks via Large Language Model
Nov 09, 2023
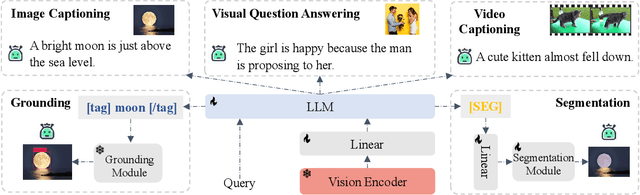
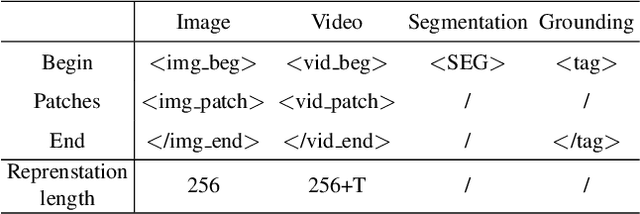

Recent advances such as LLaVA and Mini-GPT4 have successfully integrated visual information into LLMs, yielding inspiring outcomes and giving rise to a new generation of multi-modal LLMs, or MLLMs. Nevertheless, these methods struggle with hallucinations and the mutual interference between tasks. To tackle these problems, we propose an efficient and accurate approach to adapt to downstream tasks by utilizing LLM as a bridge to connect multiple expert models, namely u-LLaVA. Firstly, we incorporate the modality alignment module and multi-task modules into LLM. Then, we reorganize or rebuild multi-type public datasets to enable efficient modality alignment and instruction following. Finally, task-specific information is extracted from the trained LLM and provided to different modules for solving downstream tasks. The overall framework is simple, effective, and achieves state-of-the-art performance across multiple benchmarks. We also release our model, the generated data, and the code base publicly available.
Inject Semantic Concepts into Image Tagging for Open-Set Recognition
Oct 23, 2023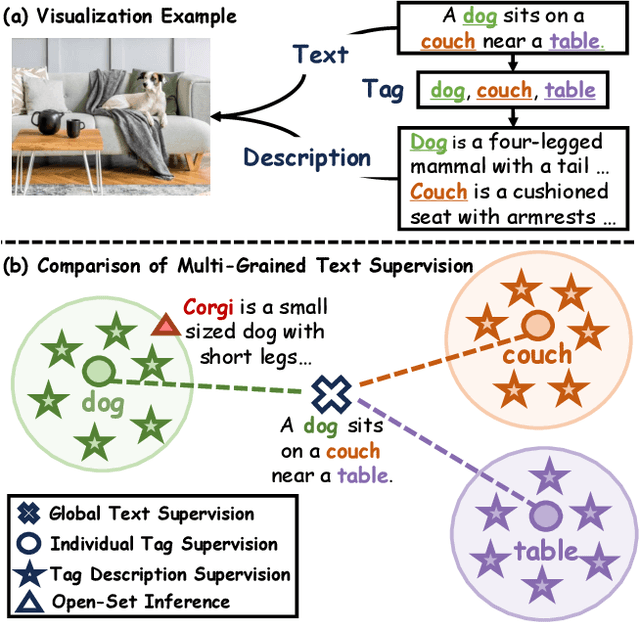
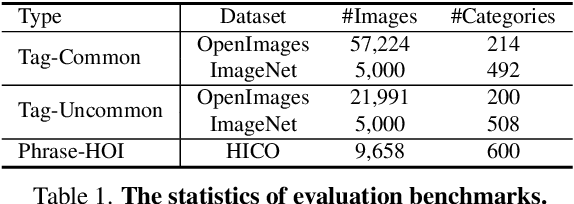
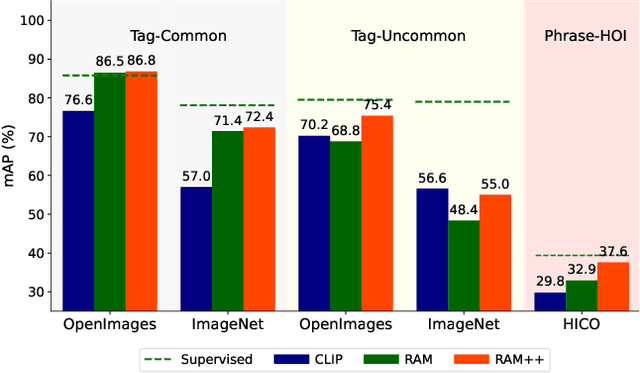
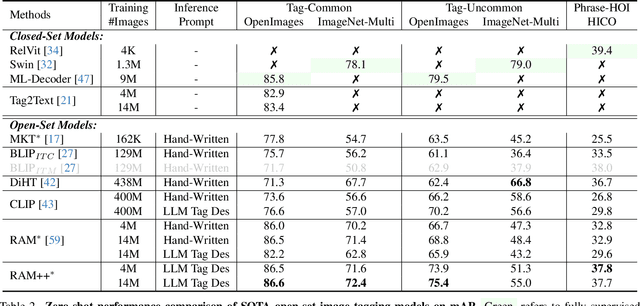
In this paper, we introduce the Recognize Anything Plus Model~(RAM++), a fundamental image recognition model with strong open-set recognition capabilities, by injecting semantic concepts into image tagging training framework. Previous approaches are either image tagging models constrained by limited semantics, or vision-language models with shallow interaction for suboptimal performance in multi-tag recognition. In contrast, RAM++ integrates image-text alignment and image-tagging within a unified fine-grained interaction framework based on image-tags-text triplets. This design enables RAM++ not only excel in identifying predefined categories, but also significantly augment the recognition ability in open-set categories. Moreover, RAM++ employs large language models~(LLMs) to generate diverse visual tag descriptions, pioneering the integration of LLM's knowledge into image tagging training. This approach empowers RAM++ to integrate visual description concepts for open-set recognition during inference. Evaluations on comprehensive image recognition benchmarks demonstrate RAM++ exceeds existing state-of-the-art (SOTA) fundamental image recognition models on most aspects. Specifically, for predefined common-used tag categories, RAM++ showcases 10.2 mAP and 15.4 mAP enhancements over CLIP on OpenImages and ImageNet. For open-set categories beyond predefined, RAM++ records improvements of 5 mAP and 6.4 mAP over CLIP and RAM respectively on OpenImages. For diverse human-object interaction phrases, RAM++ achieves 7.8 mAP and 4.7 mAP improvements on the HICO benchmark. Code, datasets and pre-trained models are available at \url{https://github.com/xinyu1205/recognize-anything}.
Prototype Fission: Closing Set for Robust Open-set Semi-supervised Learning
Aug 29, 2023



Semi-supervised Learning (SSL) has been proven vulnerable to out-of-distribution (OOD) samples in realistic large-scale unsupervised datasets due to over-confident pseudo-labeling OODs as in-distribution (ID). A key underlying problem is class-wise latent space spreading from closed seen space to open unseen space, and the bias is further magnified in SSL's self-training loops. To close the ID distribution set so that OODs are better rejected for safe SSL, we propose Prototype Fission(PF) to divide class-wise latent spaces into compact sub-spaces by automatic fine-grained latent space mining, driven by coarse-grained labels only. Specifically, we form multiple unique learnable sub-class prototypes for each class, optimized towards both diversity and consistency. The Diversity Modeling term encourages samples to be clustered by one of the multiple sub-class prototypes, while the Consistency Modeling term clusters all samples of the same class to a global prototype. Instead of "opening set", i.e., modeling OOD distribution, Prototype Fission "closes set" and makes it hard for OOD samples to fit in sub-class latent space. Therefore, PF is compatible with existing methods for further performance gains. Extensive experiments validate the effectiveness of our method in open-set SSL settings in terms of successfully forming sub-classes, discriminating OODs from IDs and improving overall accuracy. Codes will be released.
CLIP Brings Better Features to Visual Aesthetics Learners
Jul 28, 2023The success of pre-training approaches on a variety of downstream tasks has revitalized the field of computer vision. Image aesthetics assessment (IAA) is one of the ideal application scenarios for such methods due to subjective and expensive labeling procedure. In this work, an unified and flexible two-phase \textbf{C}LIP-based \textbf{S}emi-supervised \textbf{K}nowledge \textbf{D}istillation paradigm is proposed, namely \textbf{\textit{CSKD}}. Specifically, we first integrate and leverage a multi-source unlabeled dataset to align rich features between a given visual encoder and an off-the-shelf CLIP image encoder via feature alignment loss. Notably, the given visual encoder is not limited by size or structure and, once well-trained, it can seamlessly serve as a better visual aesthetic learner for both student and teacher. In the second phase, the unlabeled data is also utilized in semi-supervised IAA learning to further boost student model performance when applied in latency-sensitive production scenarios. By analyzing the attention distance and entropy before and after feature alignment, we notice an alleviation of feature collapse issue, which in turn showcase the necessity of feature alignment instead of training directly based on CLIP image encoder. Extensive experiments indicate the superiority of CSKD, which achieves state-of-the-art performance on multiple widely used IAA benchmarks.
Recognize Anything: A Strong Image Tagging Model
Jun 09, 2023



We present the Recognize Anything Model (RAM): a strong foundation model for image tagging. RAM makes a substantial step for large models in computer vision, demonstrating the zero-shot ability to recognize any common category with high accuracy. RAM introduces a new paradigm for image tagging, leveraging large-scale image-text pairs for training instead of manual annotations. The development of RAM comprises four key steps. Firstly, annotation-free image tags are obtained at scale through automatic text semantic parsing. Subsequently, a preliminary model is trained for automatic annotation by unifying the caption and tagging tasks, supervised by the original texts and parsed tags, respectively. Thirdly, a data engine is employed to generate additional annotations and clean incorrect ones. Lastly, the model is retrained with the processed data and fine-tuned using a smaller but higher-quality dataset. We evaluate the tagging capabilities of RAM on numerous benchmarks and observe impressive zero-shot performance, significantly outperforming CLIP and BLIP. Remarkably, RAM even surpasses the fully supervised manners and exhibits competitive performance with the Google tagging API. We are releasing the RAM at \url{https://recognize-anything.github.io/} to foster the advancements of large models in computer vision.
Box-Level Active Detection
Mar 23, 2023Active learning selects informative samples for annotation within budget, which has proven efficient recently on object detection. However, the widely used active detection benchmarks conduct image-level evaluation, which is unrealistic in human workload estimation and biased towards crowded images. Furthermore, existing methods still perform image-level annotation, but equally scoring all targets within the same image incurs waste of budget and redundant labels. Having revealed above problems and limitations, we introduce a box-level active detection framework that controls a box-based budget per cycle, prioritizes informative targets and avoids redundancy for fair comparison and efficient application. Under the proposed box-level setting, we devise a novel pipeline, namely Complementary Pseudo Active Strategy (ComPAS). It exploits both human annotations and the model intelligence in a complementary fashion: an efficient input-end committee queries labels for informative objects only; meantime well-learned targets are identified by the model and compensated with pseudo-labels. ComPAS consistently outperforms 10 competitors under 4 settings in a unified codebase. With supervision from labeled data only, it achieves 100% supervised performance of VOC0712 with merely 19% box annotations. On the COCO dataset, it yields up to 4.3% mAP improvement over the second-best method. ComPAS also supports training with the unlabeled pool, where it surpasses 90% COCO supervised performance with 85% label reduction. Our source code is publicly available at https://github.com/lyumengyao/blad.
Knowledge Distillation from Single to Multi Labels: an Empirical Study
Mar 15, 2023



Knowledge distillation (KD) has been extensively studied in single-label image classification. However, its efficacy for multi-label classification remains relatively unexplored. In this study, we firstly investigate the effectiveness of classical KD techniques, including logit-based and feature-based methods, for multi-label classification. Our findings indicate that the logit-based method is not well-suited for multi-label classification, as the teacher fails to provide inter-category similarity information or regularization effect on student model's training. Moreover, we observe that feature-based methods struggle to convey compact information of multiple labels simultaneously. Given these limitations, we propose that a suitable dark knowledge should incorporate class-wise information and be highly correlated with the final classification results. To address these issues, we introduce a novel distillation method based on Class Activation Maps (CAMs), which is both effective and straightforward to implement. Across a wide range of settings, CAMs-based distillation consistently outperforms other methods.
Tag2Text: Guiding Vision-Language Model via Image Tagging
Mar 10, 2023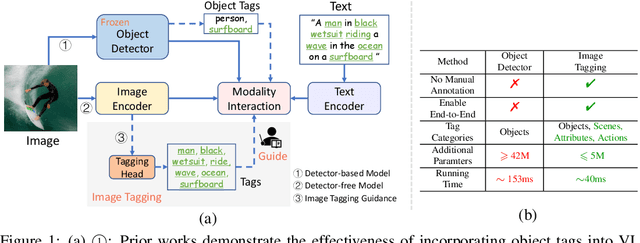
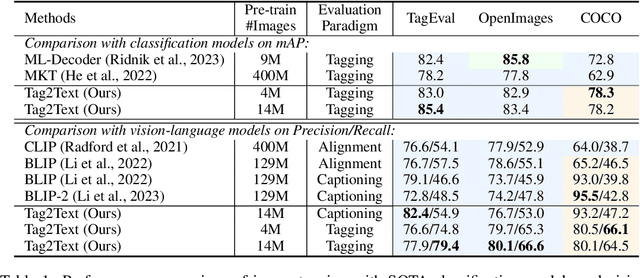

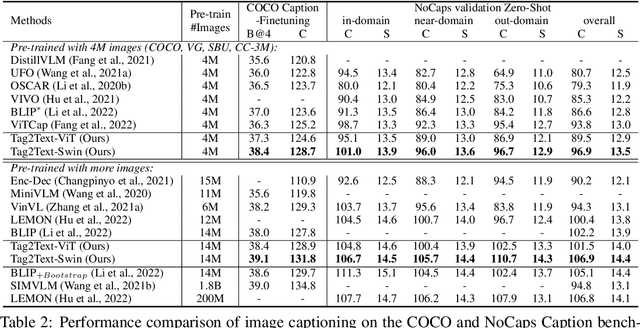
This paper presents Tag2Text, a vision language pre-training (VLP) framework, which introduces image tagging into vision-language models to guide the learning of visual-linguistic features. In contrast to prior works which utilize object tags either manually labeled or automatically detected with a limited detector, our approach utilizes tags parsed from its paired text to learn an image tagger and meanwhile provides guidance to vision-language models. Given that, Tag2Text can utilize large-scale annotation-free image tags in accordance with image-text pairs, and provides more diverse tag categories beyond objects. As a result, Tag2Text achieves a superior image tag recognition ability by exploiting fine-grained text information. Moreover, by leveraging tagging guidance, Tag2Text effectively enhances the performance of vision-language models on both generation-based and alignment-based tasks. Across a wide range of downstream benchmarks, Tag2Text achieves state-of-the-art or competitive results with similar model sizes and data scales, demonstrating the efficacy of the proposed tagging guidance.