 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecognize Anything: A Strong Image Tagging Model
Jun 09, 2023



We present the Recognize Anything Model (RAM): a strong foundation model for image tagging. RAM makes a substantial step for large models in computer vision, demonstrating the zero-shot ability to recognize any common category with high accuracy. RAM introduces a new paradigm for image tagging, leveraging large-scale image-text pairs for training instead of manual annotations. The development of RAM comprises four key steps. Firstly, annotation-free image tags are obtained at scale through automatic text semantic parsing. Subsequently, a preliminary model is trained for automatic annotation by unifying the caption and tagging tasks, supervised by the original texts and parsed tags, respectively. Thirdly, a data engine is employed to generate additional annotations and clean incorrect ones. Lastly, the model is retrained with the processed data and fine-tuned using a smaller but higher-quality dataset. We evaluate the tagging capabilities of RAM on numerous benchmarks and observe impressive zero-shot performance, significantly outperforming CLIP and BLIP. Remarkably, RAM even surpasses the fully supervised manners and exhibits competitive performance with the Google tagging API. We are releasing the RAM at \url{https://recognize-anything.github.io/} to foster the advancements of large models in computer vision.
Knowledge Distillation from Single to Multi Labels: an Empirical Study
Mar 15, 2023



Knowledge distillation (KD) has been extensively studied in single-label image classification. However, its efficacy for multi-label classification remains relatively unexplored. In this study, we firstly investigate the effectiveness of classical KD techniques, including logit-based and feature-based methods, for multi-label classification. Our findings indicate that the logit-based method is not well-suited for multi-label classification, as the teacher fails to provide inter-category similarity information or regularization effect on student model's training. Moreover, we observe that feature-based methods struggle to convey compact information of multiple labels simultaneously. Given these limitations, we propose that a suitable dark knowledge should incorporate class-wise information and be highly correlated with the final classification results. To address these issues, we introduce a novel distillation method based on Class Activation Maps (CAMs), which is both effective and straightforward to implement. Across a wide range of settings, CAMs-based distillation consistently outperforms other methods.
A Unified Two-Stage Group Semantics Propagation and Contrastive Learning Network for Co-Saliency Detection
Aug 13, 2022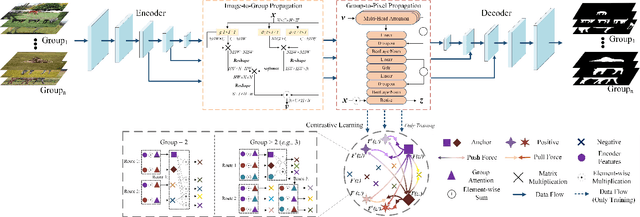
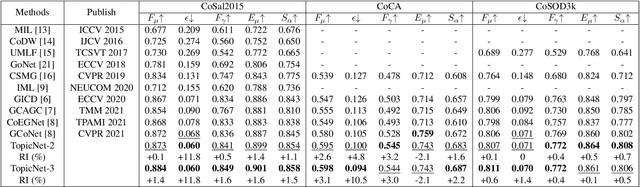


Co-saliency detection (CoSOD) aims at discovering the repetitive salient objects from multiple images. Two primary challenges are group semantics extraction and noise object suppression. In this paper, we present a unified Two-stage grOup semantics PropagatIon and Contrastive learning NETwork (TopicNet) for CoSOD. TopicNet can be decomposed into two substructures, including a two-stage group semantics propagation module (TGSP) to address the first challenge and a contrastive learning module (CLM) to address the second challenge. Concretely, for TGSP, we design an image-to-group propagation module (IGP) to capture the consensus representation of intra-group similar features and a group-to-pixel propagation module (GPP) to build the relevancy of consensus representation. For CLM, with the design of positive samples, the semantic consistency is enhanced. With the design of negative samples, the noise objects are suppressed. Experimental results on three prevailing benchmarks reveal that TopicNet outperforms other competitors in terms of various evaluation metrics.