 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePIGEON: VLM-Driven Object Navigation via Points of Interest Selection
Nov 17, 2025
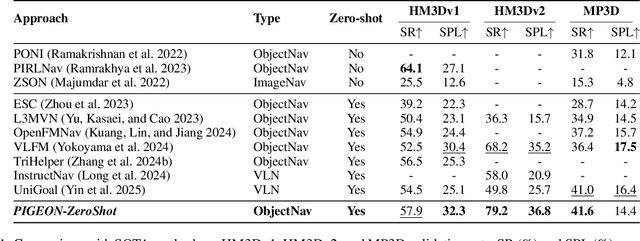

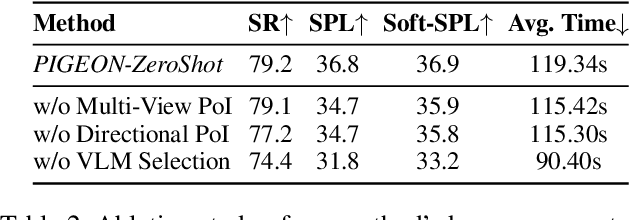
Navigating to a specified object in an unknown environment is a fundamental yet challenging capability of embodied intelligence. However, current methods struggle to balance decision frequency with intelligence, resulting in decisions lacking foresight or discontinuous actions. In this work, we propose PIGEON: Point of Interest Guided Exploration for Object Navigation with VLM, maintaining a lightweight and semantically aligned snapshot memory during exploration as semantic input for the exploration strategy. We use a large Visual-Language Model (VLM), named PIGEON-VL, to select Points of Interest (PoI) formed during exploration and then employ a lower-level planner for action output, increasing the decision frequency. Additionally, this PoI-based decision-making enables the generation of Reinforcement Learning with Verifiable Reward (RLVR) data suitable for simulators. Experiments on classic object navigation benchmarks demonstrate that our zero-shot transfer method achieves state-of-the-art performance, while RLVR further enhances the model's semantic guidance capabilities, enabling deep reasoning during real-time navigation.
Mobile-Agent-RAG: Driving Smart Multi-Agent Coordination with Contextual Knowledge Empowerment for Long-Horizon Mobile Automation
Nov 15, 2025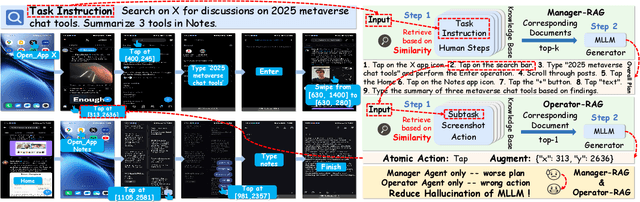
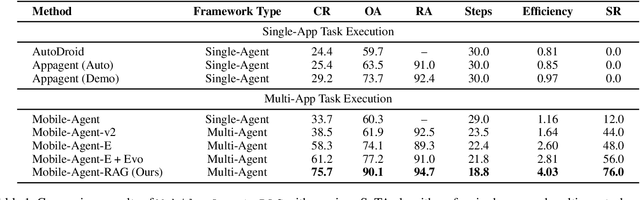
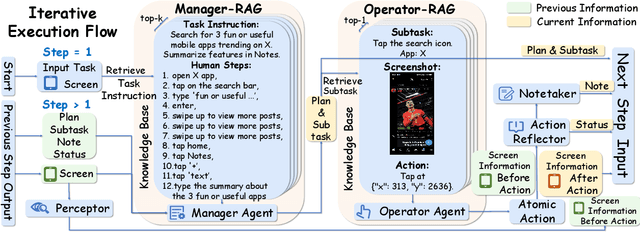
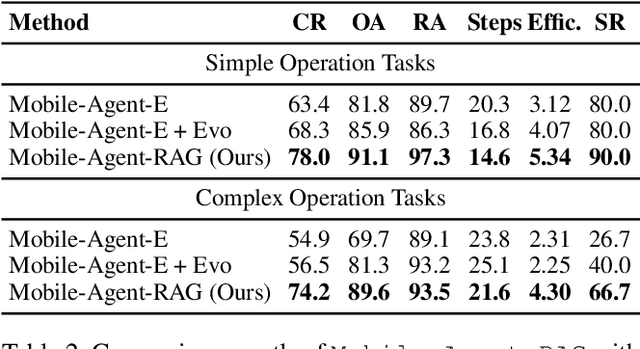
Mobile agents show immense potential, yet current state-of-the-art (SoTA) agents exhibit inadequate success rates on real-world, long-horizon, cross-application tasks. We attribute this bottleneck to the agents' excessive reliance on static, internal knowledge within MLLMs, which leads to two critical failure points: 1) strategic hallucinations in high-level planning and 2) operational errors during low-level execution on user interfaces (UI). The core insight of this paper is that high-level planning and low-level UI operations require fundamentally distinct types of knowledge. Planning demands high-level, strategy-oriented experiences, whereas operations necessitate low-level, precise instructions closely tied to specific app UIs. Motivated by these insights, we propose Mobile-Agent-RAG, a novel hierarchical multi-agent framework that innovatively integrates dual-level retrieval augmentation. At the planning stage, we introduce Manager-RAG to reduce strategic hallucinations by retrieving human-validated comprehensive task plans that provide high-level guidance. At the execution stage, we develop Operator-RAG to improve execution accuracy by retrieving the most precise low-level guidance for accurate atomic actions, aligned with the current app and subtask. To accurately deliver these knowledge types, we construct two specialized retrieval-oriented knowledge bases. Furthermore, we introduce Mobile-Eval-RAG, a challenging benchmark for evaluating such agents on realistic multi-app, long-horizon tasks. Extensive experiments demonstrate that Mobile-Agent-RAG significantly outperforms SoTA baselines, improving task completion rate by 11.0% and step efficiency by 10.2%, establishing a robust paradigm for context-aware, reliable multi-agent mobile automation.
Non-Rigid Structure-from-Motion via Differential Geometry with Recoverable Conformal Scale
Oct 02, 2025Non-rigid structure-from-motion (NRSfM), a promising technique for addressing the mapping challenges in monocular visual deformable simultaneous localization and mapping (SLAM), has attracted growing attention. We introduce a novel method, called Con-NRSfM, for NRSfM under conformal deformations, encompassing isometric deformations as a subset. Our approach performs point-wise reconstruction using 2D selected image warps optimized through a graph-based framework. Unlike existing methods that rely on strict assumptions, such as locally planar surfaces or locally linear deformations, and fail to recover the conformal scale, our method eliminates these constraints and accurately computes the local conformal scale. Additionally, our framework decouples constraints on depth and conformal scale, which are inseparable in other approaches, enabling more precise depth estimation. To address the sensitivity of the formulated problem, we employ a parallel separable iterative optimization strategy. Furthermore, a self-supervised learning framework, utilizing an encoder-decoder network, is incorporated to generate dense 3D point clouds with texture. Simulation and experimental results using both synthetic and real datasets demonstrate that our method surpasses existing approaches in terms of reconstruction accuracy and robustness. The code for the proposed method will be made publicly available on the project website: https://sites.google.com/view/con-nrsfm.
OwlCap: Harmonizing Motion-Detail for Video Captioning via HMD-270K and Caption Set Equivalence Reward
Aug 27, 2025
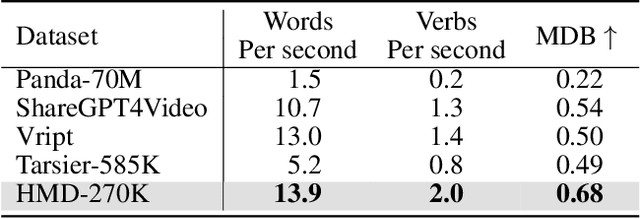
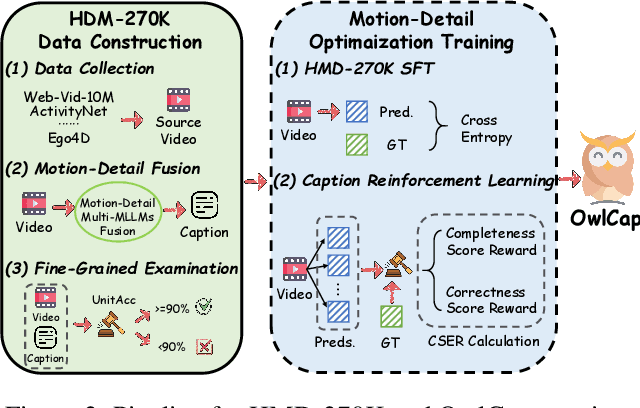
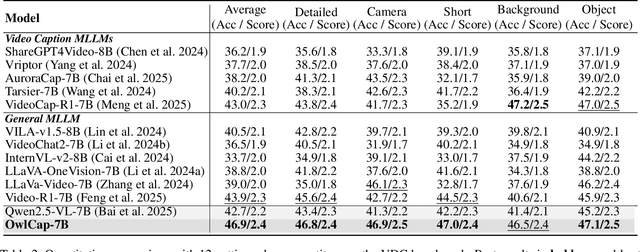
Video captioning aims to generate comprehensive and coherent descriptions of the video content, contributing to the advancement of both video understanding and generation. However, existing methods often suffer from motion-detail imbalance, as models tend to overemphasize one aspect while neglecting the other. This imbalance results in incomplete captions, which in turn leads to a lack of consistency in video understanding and generation. To address this issue, we propose solutions from two aspects: 1) Data aspect: We constructed the Harmonizing Motion-Detail 270K (HMD-270K) dataset through a two-stage pipeline: Motion-Detail Fusion (MDF) and Fine-Grained Examination (FGE). 2) Optimization aspect: We introduce the Caption Set Equivalence Reward (CSER) based on Group Relative Policy Optimization (GRPO). CSER enhances completeness and accuracy in capturing both motion and details through unit-to-set matching and bidirectional validation. Based on the HMD-270K supervised fine-tuning and GRPO post-training with CSER, we developed OwlCap, a powerful video captioning multi-modal large language model (MLLM) with motion-detail balance. Experimental results demonstrate that OwlCap achieves significant improvements compared to baseline models on two benchmarks: the detail-focused VDC (+4.2 Acc) and the motion-focused DREAM-1K (+4.6 F1). The HMD-270K dataset and OwlCap model will be publicly released to facilitate video captioning research community advancements.
Dynamic-I2V: Exploring Image-to-Video Generaion Models via Multimodal LLM
May 26, 2025



Recent advancements in image-to-video (I2V) generation have shown promising performance in conventional scenarios. However, these methods still encounter significant challenges when dealing with complex scenes that require a deep understanding of nuanced motion and intricate object-action relationships. To address these challenges, we present Dynamic-I2V, an innovative framework that integrates Multimodal Large Language Models (MLLMs) to jointly encode visual and textual conditions for a diffusion transformer (DiT) architecture. By leveraging the advanced multimodal understanding capabilities of MLLMs, our model significantly improves motion controllability and temporal coherence in synthesized videos. The inherent multimodality of Dynamic-I2V further enables flexible support for diverse conditional inputs, extending its applicability to various downstream generation tasks. Through systematic analysis, we identify a critical limitation in current I2V benchmarks: a significant bias towards favoring low-dynamic videos, stemming from an inadequate balance between motion complexity and visual quality metrics. To resolve this evaluation gap, we propose DIVE - a novel assessment benchmark specifically designed for comprehensive dynamic quality measurement in I2V generation. In conclusion, extensive quantitative and qualitative experiments confirm that Dynamic-I2V attains state-of-the-art performance in image-to-video generation, particularly revealing significant improvements of 42.5%, 7.9%, and 11.8% in dynamic range, controllability, and quality, respectively, as assessed by the DIVE metric in comparison to existing methods.
SPP-SBL: Space-Power Prior Sparse Bayesian Learning for Block Sparse Recovery
May 13, 2025The recovery of block-sparse signals with unknown structural patterns remains a fundamental challenge in structured sparse signal reconstruction. By proposing a variance transformation framework, this paper unifies existing pattern-based block sparse Bayesian learning methods, and introduces a novel space power prior based on undirected graph models to adaptively capture the unknown patterns of block-sparse signals. By combining the EM algorithm with high-order equation root-solving, we develop a new structured sparse Bayesian learning method, SPP-SBL, which effectively addresses the open problem of space coupling parameter estimation in pattern-based methods. We further demonstrate that learning the relative values of space coupling parameters is key to capturing unknown block-sparse patterns and improving recovery accuracy. Experiments validate that SPP-SBL successfully recovers various challenging structured sparse signals (e.g., chain-structured signals and multi-pattern sparse signals) and real-world multi-modal structured sparse signals (images, audio), showing significant advantages in recovery accuracy across multiple metrics.
Improved Visual-Spatial Reasoning via R1-Zero-Like Training
Apr 01, 2025Increasing attention has been placed on improving the reasoning capacities of multi-modal large language models (MLLMs). As the cornerstone for AI agents that function in the physical realm, video-based visual-spatial intelligence (VSI) emerges as one of the most pivotal reasoning capabilities of MLLMs. This work conducts a first, in-depth study on improving the visual-spatial reasoning of MLLMs via R1-Zero-like training. Technically, we first identify that the visual-spatial reasoning capacities of small- to medium-sized Qwen2-VL models cannot be activated via Chain of Thought (CoT) prompts. We then incorporate GRPO training for improved visual-spatial reasoning, using the carefully curated VSI-100k dataset, following DeepSeek-R1-Zero. During the investigation, we identify the necessity to keep the KL penalty (even with a small value) in GRPO. With just 120 GPU hours, our vsGRPO-2B model, fine-tuned from Qwen2-VL-2B, can outperform the base model by 12.1% and surpass GPT-4o. Moreover, our vsGRPO-7B model, fine-tuned from Qwen2-VL-7B, achieves performance comparable to that of the best open-source model LLaVA-NeXT-Video-72B. Additionally, we compare vsGRPO to supervised fine-tuning and direct preference optimization baselines and observe strong performance superiority. The code and dataset will be available soon.
H2VU-Benchmark: A Comprehensive Benchmark for Hierarchical Holistic Video Understanding
Mar 31, 2025With the rapid development of multimodal models, the demand for assessing video understanding capabilities has been steadily increasing. However, existing benchmarks for evaluating video understanding exhibit significant limitations in coverage, task diversity, and scene adaptability. These shortcomings hinder the accurate assessment of models' comprehensive video understanding capabilities. To tackle this challenge, we propose a hierarchical and holistic video understanding (H2VU) benchmark designed to evaluate both general video and online streaming video comprehension. This benchmark contributes three key features: Extended video duration: Spanning videos from brief 3-second clips to comprehensive 1.5-hour recordings, thereby bridging the temporal gaps found in current benchmarks. Comprehensive assessment tasks: Beyond traditional perceptual and reasoning tasks, we have introduced modules for countercommonsense comprehension and trajectory state tracking. These additions test the models' deep understanding capabilities beyond mere prior knowledge. Enriched video data: To keep pace with the rapid evolution of current AI agents, we have expanded first-person streaming video datasets. This expansion allows for the exploration of multimodal models' performance in understanding streaming videos from a first-person perspective. Extensive results from H2VU reveal that existing multimodal large language models (MLLMs) possess substantial potential for improvement in our newly proposed evaluation tasks. We expect that H2VU will facilitate advancements in video understanding research by offering a comprehensive and in-depth analysis of MLLMs.
Layton: Latent Consistency Tokenizer for 1024-pixel Image Reconstruction and Generation by 256 Tokens
Mar 12, 2025



Image tokenization has significantly advanced visual generation and multimodal modeling, particularly when paired with autoregressive models. However, current methods face challenges in balancing efficiency and fidelity: high-resolution image reconstruction either requires an excessive number of tokens or compromises critical details through token reduction. To resolve this, we propose Latent Consistency Tokenizer (Layton) that bridges discrete visual tokens with the compact latent space of pre-trained Latent Diffusion Models (LDMs), enabling efficient representation of 1024x1024 images using only 256 tokens-a 16 times compression over VQGAN. Layton integrates a transformer encoder, a quantized codebook, and a latent consistency decoder. Direct application of LDM as the decoder results in color and brightness discrepancies. Thus, we convert it to latent consistency decoder, reducing multi-step sampling to 1-2 steps for direct pixel-level supervision. Experiments demonstrate Layton's superiority in high-fidelity reconstruction, with 10.8 reconstruction Frechet Inception Distance on MSCOCO-2017 5K benchmark for 1024x1024 image reconstruction. We also extend Layton to a text-to-image generation model, LaytonGen, working in autoregression. It achieves 0.73 score on GenEval benchmark, surpassing current state-of-the-art methods. Project homepage: https://github.com/OPPO-Mente-Lab/Layton
HEIE: MLLM-Based Hierarchical Explainable AIGC Image Implausibility Evaluator
Nov 26, 2024



AIGC images are prevalent across various fields, yet they frequently suffer from quality issues like artifacts and unnatural textures. Specialized models aim to predict defect region heatmaps but face two primary challenges: (1) lack of explainability, failing to provide reasons and analyses for subtle defects, and (2) inability to leverage common sense and logical reasoning, leading to poor generalization. Multimodal large language models (MLLMs) promise better comprehension and reasoning but face their own challenges: (1) difficulty in fine-grained defect localization due to the limitations in capturing tiny details; and (2) constraints in providing pixel-wise outputs necessary for precise heatmap generation. To address these challenges, we propose HEIE: a novel MLLM-Based Hierarchical Explainable image Implausibility Evaluator. We introduce the CoT-Driven Explainable Trinity Evaluator, which integrates heatmaps, scores, and explanation outputs, using CoT to decompose complex tasks into subtasks of increasing difficulty and enhance interpretability. Our Adaptive Hierarchical Implausibility Mapper synergizes low-level image features with high-level mapper tokens from LLMs, enabling precise local-to-global hierarchical heatmap predictions through an uncertainty-based adaptive token approach. Moreover, we propose a new dataset: Expl-AIGI-Eval, designed to facilitate interpretable implausibility evaluation of AIGC images. Our method demonstrates state-of-the-art performance through extensive experiments.