 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiple Object Tracking in Video SAR: A Benchmark and Tracking Baseline
Jun 13, 2025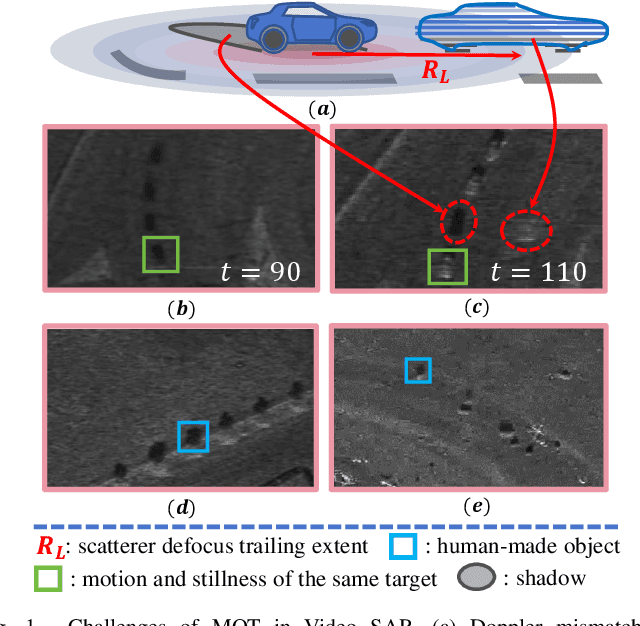
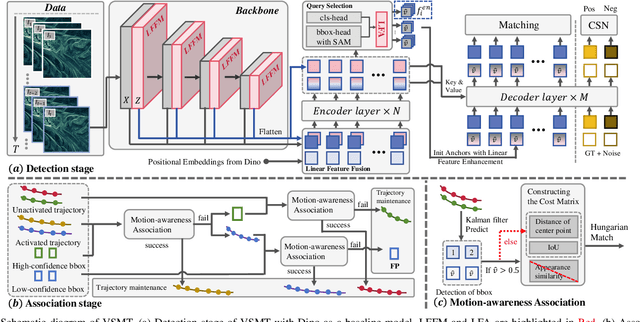
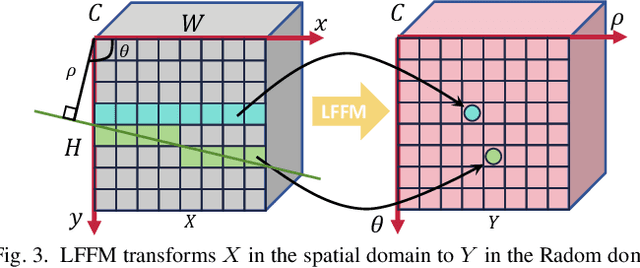
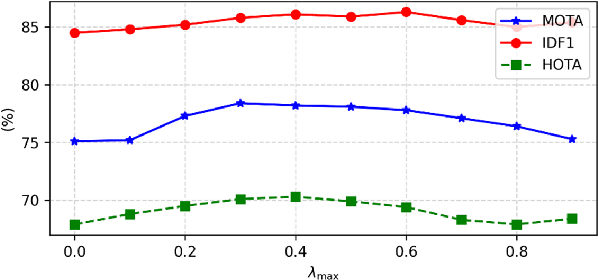
In the context of multi-object tracking using video synthetic aperture radar (Video SAR), Doppler shifts induced by target motion result in artifacts that are easily mistaken for shadows caused by static occlusions. Moreover, appearance changes of the target caused by Doppler mismatch may lead to association failures and disrupt trajectory continuity. A major limitation in this field is the lack of public benchmark datasets for standardized algorithm evaluation. To address the above challenges, we collected and annotated 45 video SAR sequences containing moving targets, and named the Video SAR MOT Benchmark (VSMB). Specifically, to mitigate the effects of trailing and defocusing in moving targets, we introduce a line feature enhancement mechanism that emphasizes the positive role of motion shadows and reduces false alarms induced by static occlusions. In addition, to mitigate the adverse effects of target appearance variations, we propose a motion-aware clue discarding mechanism that substantially improves tracking robustness in Video SAR. The proposed model achieves state-of-the-art performance on the VSMB, and the dataset and model are released at https://github.com/softwarePupil/VSMB.
NodeRAG: Structuring Graph-based RAG with Heterogeneous Nodes
Apr 15, 2025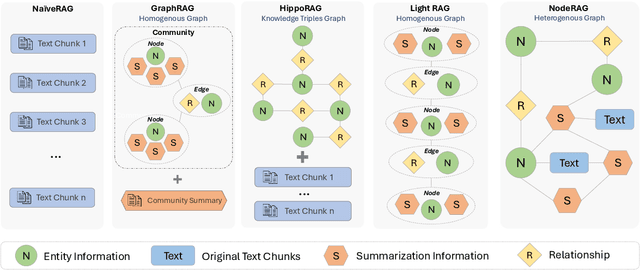
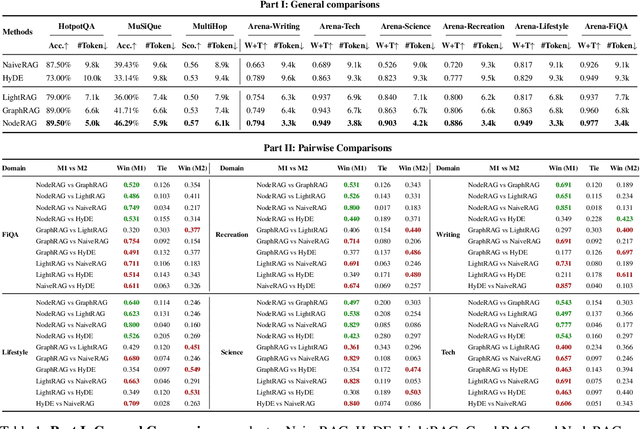
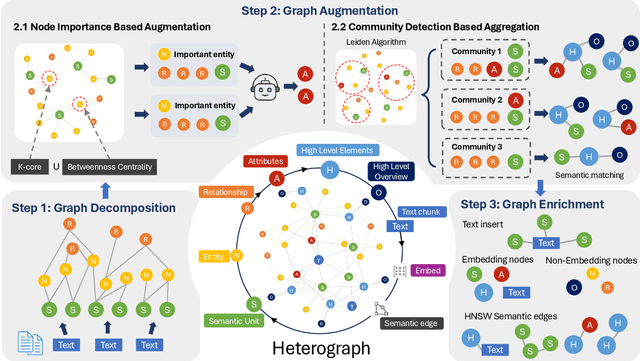
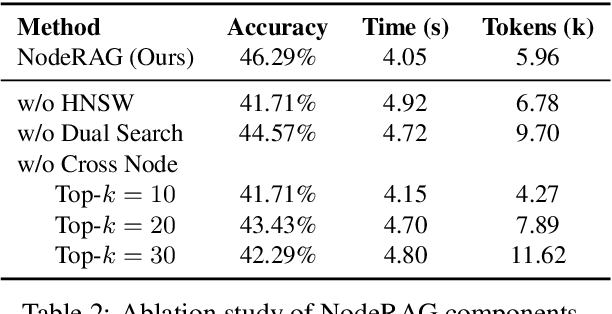
Retrieval-augmented generation (RAG) empowers large language models to access external and private corpus, enabling factually consistent responses in specific domains. By exploiting the inherent structure of the corpus, graph-based RAG methods further enrich this process by building a knowledge graph index and leveraging the structural nature of graphs. However, current graph-based RAG approaches seldom prioritize the design of graph structures. Inadequately designed graph not only impede the seamless integration of diverse graph algorithms but also result in workflow inconsistencies and degraded performance. To further unleash the potential of graph for RAG, we propose NodeRAG, a graph-centric framework introducing heterogeneous graph structures that enable the seamless and holistic integration of graph-based methodologies into the RAG workflow. By aligning closely with the capabilities of LLMs, this framework ensures a fully cohesive and efficient end-to-end process. Through extensive experiments, we demonstrate that NodeRAG exhibits performance advantages over previous methods, including GraphRAG and LightRAG, not only in indexing time, query time, and storage efficiency but also in delivering superior question-answering performance on multi-hop benchmarks and open-ended head-to-head evaluations with minimal retrieval tokens. Our GitHub repository could be seen at https://github.com/Terry-Xu-666/NodeRAG.
HEIE: MLLM-Based Hierarchical Explainable AIGC Image Implausibility Evaluator
Nov 26, 2024



AIGC images are prevalent across various fields, yet they frequently suffer from quality issues like artifacts and unnatural textures. Specialized models aim to predict defect region heatmaps but face two primary challenges: (1) lack of explainability, failing to provide reasons and analyses for subtle defects, and (2) inability to leverage common sense and logical reasoning, leading to poor generalization. Multimodal large language models (MLLMs) promise better comprehension and reasoning but face their own challenges: (1) difficulty in fine-grained defect localization due to the limitations in capturing tiny details; and (2) constraints in providing pixel-wise outputs necessary for precise heatmap generation. To address these challenges, we propose HEIE: a novel MLLM-Based Hierarchical Explainable image Implausibility Evaluator. We introduce the CoT-Driven Explainable Trinity Evaluator, which integrates heatmaps, scores, and explanation outputs, using CoT to decompose complex tasks into subtasks of increasing difficulty and enhance interpretability. Our Adaptive Hierarchical Implausibility Mapper synergizes low-level image features with high-level mapper tokens from LLMs, enabling precise local-to-global hierarchical heatmap predictions through an uncertainty-based adaptive token approach. Moreover, we propose a new dataset: Expl-AIGI-Eval, designed to facilitate interpretable implausibility evaluation of AIGC images. Our method demonstrates state-of-the-art performance through extensive experiments.
LLMI3D: Empowering LLM with 3D Perception from a Single 2D Image
Aug 14, 2024

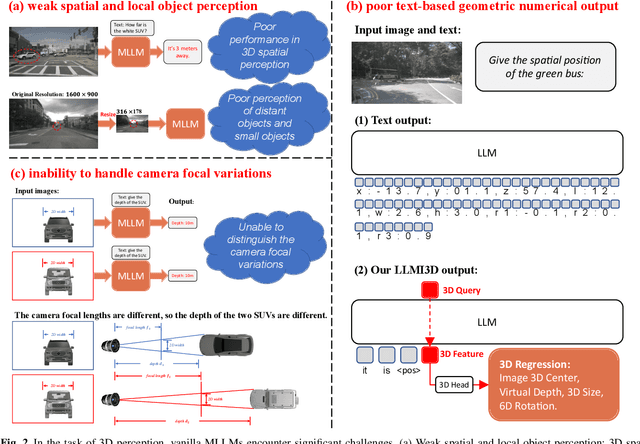

Recent advancements in autonomous driving, augmented reality, robotics, and embodied intelligence have necessitated 3D perception algorithms. However, current 3D perception methods, particularly small models, struggle with processing logical reasoning, question-answering, and handling open scenario categories. On the other hand, generative multimodal large language models (MLLMs) excel in general capacity but underperform in 3D tasks, due to weak spatial and local object perception, poor text-based geometric numerical output, and inability to handle camera focal variations. To address these challenges, we propose the following solutions: Spatial-Enhanced Local Feature Mining for better spatial feature extraction, 3D Query Token-Derived Info Decoding for precise geometric regression, and Geometry Projection-Based 3D Reasoning for handling camera focal length variations. We employ parameter-efficient fine-tuning for a pre-trained MLLM and develop LLMI3D, a powerful 3D perception MLLM. Additionally, we have constructed the IG3D dataset, which provides fine-grained descriptions and question-answer annotations. Extensive experiments demonstrate that our LLMI3D achieves state-of-the-art performance, significantly outperforming existing methods.
CIRCLE: Convolutional Implicit Reconstruction and Completion for Large-scale Indoor Scene
Nov 25, 2021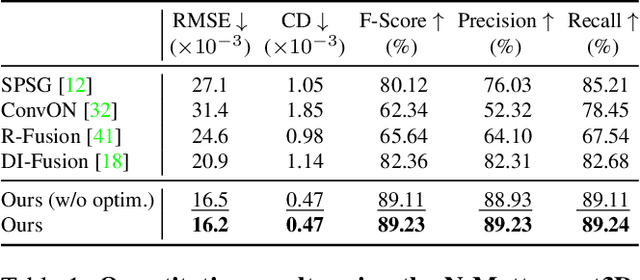
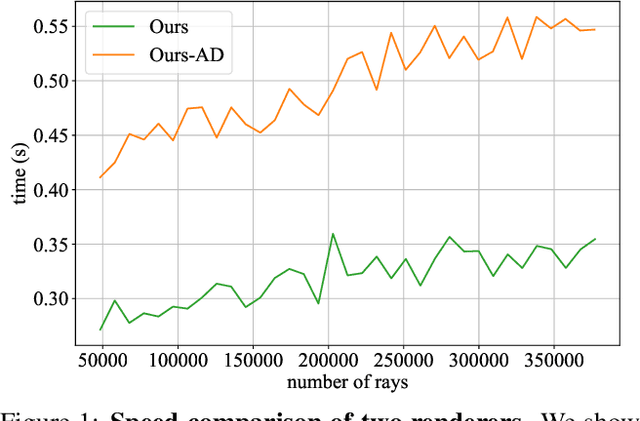
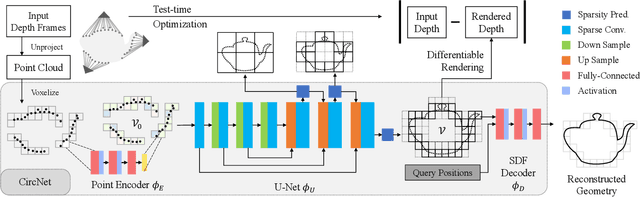
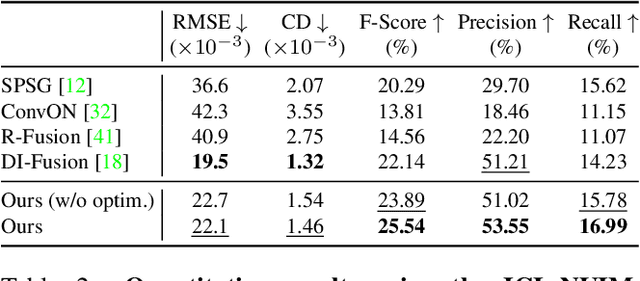
We present CIRCLE, a framework for large-scale scene completion and geometric refinement based on local implicit signed distance functions. It is based on an end-to-end sparse convolutional network, CircNet, that jointly models local geometric details and global scene structural contexts, allowing it to preserve fine-grained object detail while recovering missing regions commonly arising in traditional 3D scene data. A novel differentiable rendering module enables test-time refinement for better reconstruction quality. Extensive experiments on both real-world and synthetic datasets show that our concise framework is efficient and effective, achieving better reconstruction quality than the closest competitor while being 10-50x faster.