 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJEPA-MSAC: A Joint-Embedding Predictive Architecture for Multimodal Sensing-Assisted Communications
Mar 31, 2026Future wireless systems increasingly require predictive and transferable representations that can support multiple physical-layer (PHY) tasks under dynamic environments. However, most existing supervised learning-based methods are designed for a single task, which leads to high adaptation cost. To address this issue, we propose a joint-embedding predictive architecture for multimodal sensing-assisted communications (JEPA-MSAC), a self-supervised multimodal predictive representation learning framework for wireless environments. The proposed framework first maps multimodal sensing and communication measurements into a unified token space, and then pretrains a shared backbone using temporal block-masked JEPA to learn a predictive latent space that captures environment dynamics and cross-modal dependencies. After pretraining, the backbone is frozen and reused as a general future-feature generator, on top of which lightweight task heads are trained for localization, beam prediction, and received signal strength indicator (RSSI) prediction. Extensive experiments show the latent state supports accurate multi-task prediction with low adaptation cost. Additionally, ablation studies reveal its scaling behavior and the impact of key pretraining setups.
High-fidelity 3D Gaussian Inpainting: preserving multi-view consistency and photorealistic details
Jul 24, 2025Recent advancements in multi-view 3D reconstruction and novel-view synthesis, particularly through Neural Radiance Fields (NeRF) and 3D Gaussian Splatting (3DGS), have greatly enhanced the fidelity and efficiency of 3D content creation. However, inpainting 3D scenes remains a challenging task due to the inherent irregularity of 3D structures and the critical need for maintaining multi-view consistency. In this work, we propose a novel 3D Gaussian inpainting framework that reconstructs complete 3D scenes by leveraging sparse inpainted views. Our framework incorporates an automatic Mask Refinement Process and region-wise Uncertainty-guided Optimization. Specifically, we refine the inpainting mask using a series of operations, including Gaussian scene filtering and back-projection, enabling more accurate localization of occluded regions and realistic boundary restoration. Furthermore, our Uncertainty-guided Fine-grained Optimization strategy, which estimates the importance of each region across multi-view images during training, alleviates multi-view inconsistencies and enhances the fidelity of fine details in the inpainted results. Comprehensive experiments conducted on diverse datasets demonstrate that our approach outperforms existing state-of-the-art methods in both visual quality and view consistency.
Multiple Object Tracking in Video SAR: A Benchmark and Tracking Baseline
Jun 13, 2025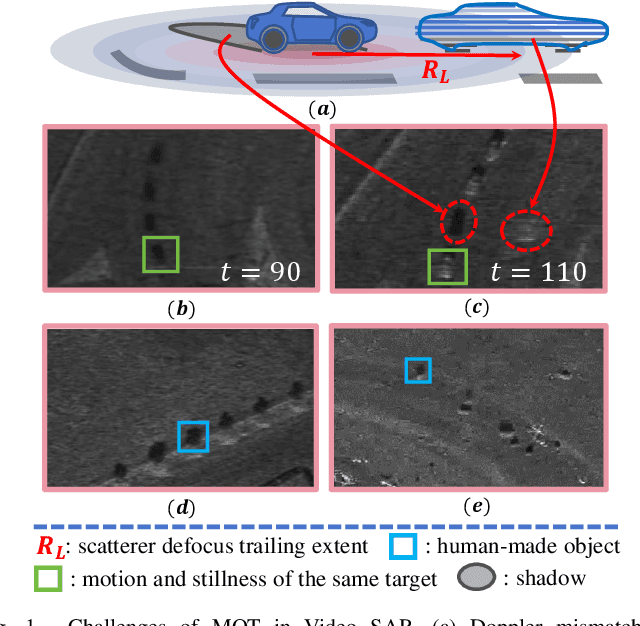
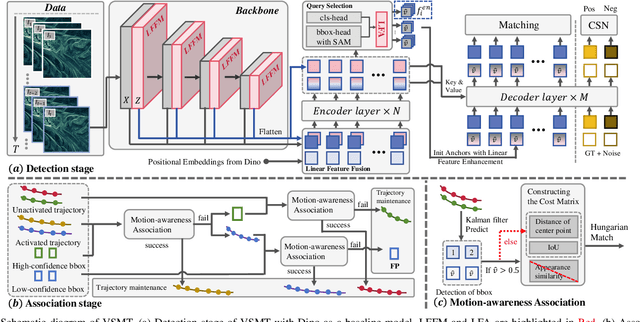
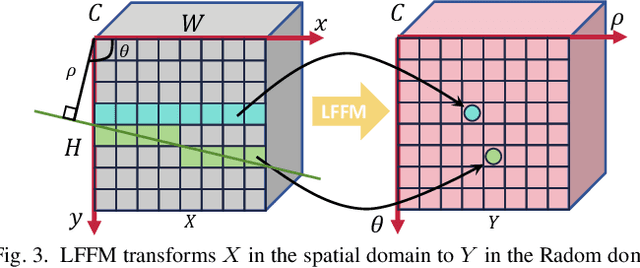
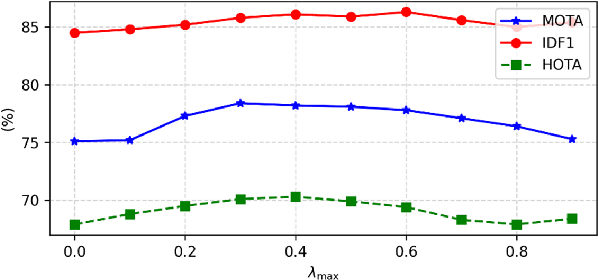
In the context of multi-object tracking using video synthetic aperture radar (Video SAR), Doppler shifts induced by target motion result in artifacts that are easily mistaken for shadows caused by static occlusions. Moreover, appearance changes of the target caused by Doppler mismatch may lead to association failures and disrupt trajectory continuity. A major limitation in this field is the lack of public benchmark datasets for standardized algorithm evaluation. To address the above challenges, we collected and annotated 45 video SAR sequences containing moving targets, and named the Video SAR MOT Benchmark (VSMB). Specifically, to mitigate the effects of trailing and defocusing in moving targets, we introduce a line feature enhancement mechanism that emphasizes the positive role of motion shadows and reduces false alarms induced by static occlusions. In addition, to mitigate the adverse effects of target appearance variations, we propose a motion-aware clue discarding mechanism that substantially improves tracking robustness in Video SAR. The proposed model achieves state-of-the-art performance on the VSMB, and the dataset and model are released at https://github.com/softwarePupil/VSMB.
Towards Better Robustness: Progressively Joint Pose-3DGS Learning for Arbitrarily Long Videos
Jan 25, 2025



3D Gaussian Splatting (3DGS) has emerged as a powerful representation due to its efficiency and high-fidelity rendering. However, 3DGS training requires a known camera pose for each input view, typically obtained by Structure-from-Motion (SfM) pipelines. Pioneering works have attempted to relax this restriction but still face difficulties when handling long sequences with complex camera trajectories. In this work, we propose Rob-GS, a robust framework to progressively estimate camera poses and optimize 3DGS for arbitrarily long video sequences. Leveraging the inherent continuity of videos, we design an adjacent pose tracking method to ensure stable pose estimation between consecutive frames. To handle arbitrarily long inputs, we adopt a "divide and conquer" scheme that adaptively splits the video sequence into several segments and optimizes them separately. Extensive experiments on the Tanks and Temples dataset and our collected real-world dataset show that our Rob-GS outperforms the state-of-the-arts.
Enhancing Virtual Try-On with Synthetic Pairs and Error-Aware Noise Scheduling
Jan 08, 2025



Given an isolated garment image in a canonical product view and a separate image of a person, the virtual try-on task aims to generate a new image of the person wearing the target garment. Prior virtual try-on works face two major challenges in achieving this goal: a) the paired (human, garment) training data has limited availability; b) generating textures on the human that perfectly match that of the prompted garment is difficult, often resulting in distorted text and faded textures. Our work explores ways to tackle these issues through both synthetic data as well as model refinement. We introduce a garment extraction model that generates (human, synthetic garment) pairs from a single image of a clothed individual. The synthetic pairs can then be used to augment the training of virtual try-on. We also propose an Error-Aware Refinement-based Schr\"odinger Bridge (EARSB) that surgically targets localized generation errors for correcting the output of a base virtual try-on model. To identify likely errors, we propose a weakly-supervised error classifier that localizes regions for refinement, subsequently augmenting the Schr\"odinger Bridge's noise schedule with its confidence heatmap. Experiments on VITON-HD and DressCode-Upper demonstrate that our synthetic data augmentation enhances the performance of prior work, while EARSB improves the overall image quality. In user studies, our model is preferred by the users in an average of 59% of cases.
Multiple-Exit Tuning: Towards Inference-Efficient Adaptation for Vision Transformer
Sep 21, 2024Parameter-efficient transfer learning (PETL) has shown great potential in adapting a vision transformer (ViT) pre-trained on large-scale datasets to various downstream tasks. Existing studies primarily focus on minimizing the number of learnable parameters. Although these methods are storage-efficient, they allocate excessive computational resources to easy samples, leading to inefficient inference. To address this issue, we introduce an inference-efficient tuning method termed multiple-exit tuning (MET). MET integrates multiple exits into the pre-trained ViT backbone. Since the predictions in ViT are made by a linear classifier, each exit is equipped with a linear prediction head. In inference stage, easy samples will exit at early exits and only hard enough samples will flow to the last exit, thus saving the computational cost for easy samples. MET consists of exit-specific adapters (E-adapters) and graph regularization. E-adapters are designed to extract suitable representations for different exits. To ensure parameter efficiency, all E-adapters share the same down-projection and up-projection matrices. As the performances of linear classifiers are influenced by the relationship among samples, we employ graph regularization to improve the representations fed into the classifiers at early exits. Finally, we conduct extensive experiments to verify the performance of MET. Experimental results show that MET has an obvious advantage over the state-of-the-art methods in terms of both accuracy and inference efficiency.
PanoFree: Tuning-Free Holistic Multi-view Image Generation with Cross-view Self-Guidance
Aug 04, 2024



Immersive scene generation, notably panorama creation, benefits significantly from the adaptation of large pre-trained text-to-image (T2I) models for multi-view image generation. Due to the high cost of acquiring multi-view images, tuning-free generation is preferred. However, existing methods are either limited to simple correspondences or require extensive fine-tuning to capture complex ones. We present PanoFree, a novel method for tuning-free multi-view image generation that supports an extensive array of correspondences. PanoFree sequentially generates multi-view images using iterative warping and inpainting, addressing the key issues of inconsistency and artifacts from error accumulation without the need for fine-tuning. It improves error accumulation by enhancing cross-view awareness and refines the warping and inpainting processes via cross-view guidance, risky area estimation and erasing, and symmetric bidirectional guided generation for loop closure, alongside guidance-based semantic and density control for scene structure preservation. In experiments on Planar, 360{\deg}, and Full Spherical Panoramas, PanoFree demonstrates significant error reduction, improves global consistency, and boosts image quality without extra fine-tuning. Compared to existing methods, PanoFree is up to 5x more efficient in time and 3x more efficient in GPU memory usage, and maintains superior diversity of results (2x better in our user study). PanoFree offers a viable alternative to costly fine-tuning or the use of additional pre-trained models. Project website at https://panofree.github.io/.
UniHuman: A Unified Model for Editing Human Images in the Wild
Dec 22, 2023

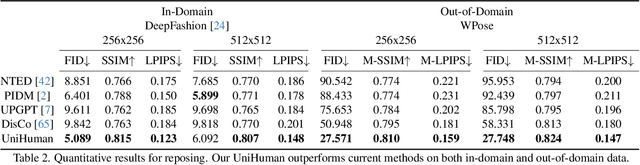

Human image editing includes tasks like changing a person's pose, their clothing, or editing the image according to a text prompt. However, prior work often tackles these tasks separately, overlooking the benefit of mutual reinforcement from learning them jointly. In this paper, we propose UniHuman, a unified model that addresses multiple facets of human image editing in real-world settings. To enhance the model's generation quality and generalization capacity, we leverage guidance from human visual encoders and introduce a lightweight pose-warping module that can exploit different pose representations, accommodating unseen textures and patterns. Furthermore, to bridge the disparity between existing human editing benchmarks with real-world data, we curated 400K high-quality human image-text pairs for training and collected 2K human images for out-of-domain testing, both encompassing diverse clothing styles, backgrounds, and age groups. Experiments on both in-domain and out-of-domain test sets demonstrate that UniHuman outperforms task-specific models by a significant margin. In user studies, UniHuman is preferred by the users in an average of 77% of cases.
Fine-grained Text and Image Guided Point Cloud Completion with CLIP Model
Aug 17, 2023



This paper focuses on the recently popular task of point cloud completion guided by multimodal information. Although existing methods have achieved excellent performance by fusing auxiliary images, there are still some deficiencies, including the poor generalization ability of the model and insufficient fine-grained semantic information for extracted features. In this work, we propose a novel multimodal fusion network for point cloud completion, which can simultaneously fuse visual and textual information to predict the semantic and geometric characteristics of incomplete shapes effectively. Specifically, to overcome the lack of prior information caused by the small-scale dataset, we employ a pre-trained vision-language model that is trained with a large amount of image-text pairs. Therefore, the textual and visual encoders of this large-scale model have stronger generalization ability. Then, we propose a multi-stage feature fusion strategy to fuse the textual and visual features into the backbone network progressively. Meanwhile, to further explore the effectiveness of fine-grained text descriptions for point cloud completion, we also build a text corpus with fine-grained descriptions, which can provide richer geometric details for 3D shapes. The rich text descriptions can be used for training and evaluating our network. Extensive quantitative and qualitative experiments demonstrate the superior performance of our method compared to state-of-the-art point cloud completion networks.
Leaf Cultivar Identification via Prototype-enhanced Learning
May 05, 2023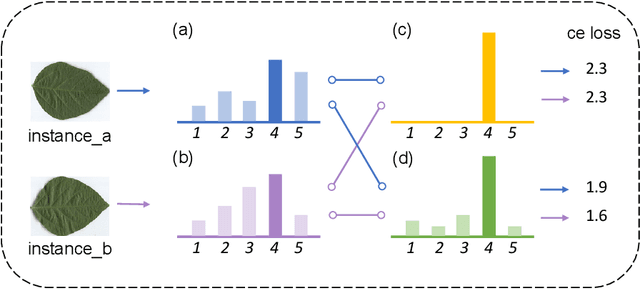
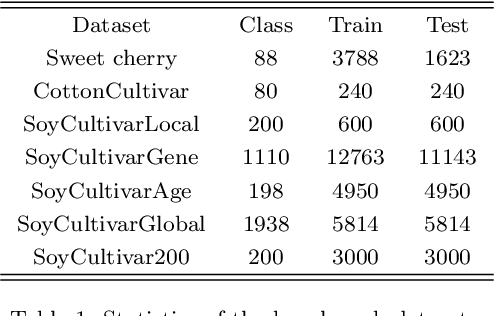
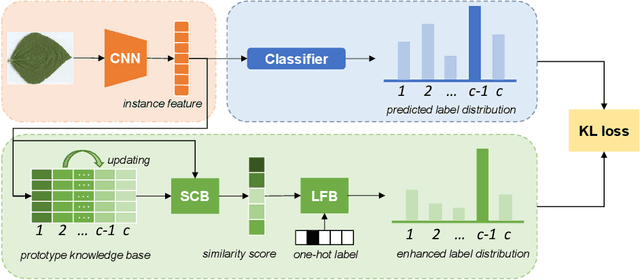
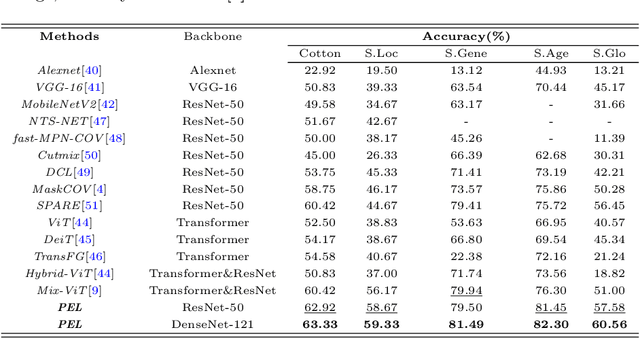
Plant leaf identification is crucial for biodiversity protection and conservation and has gradually attracted the attention of academia in recent years. Due to the high similarity among different varieties, leaf cultivar recognition is also considered to be an ultra-fine-grained visual classification (UFGVC) task, which is facing a huge challenge. In practice, an instance may be related to multiple varieties to varying degrees, especially in the UFGVC datasets. However, deep learning methods trained on one-hot labels fail to reflect patterns shared across categories and thus perform poorly on this task. To address this issue, we generate soft targets integrated with inter-class similarity information. Specifically, we continuously update the prototypical features for each category and then capture the similarity scores between instances and prototypes accordingly. Original one-hot labels and the similarity scores are incorporated to yield enhanced labels. Prototype-enhanced soft labels not only contain original one-hot label information, but also introduce rich inter-category semantic association information, thus providing more effective supervision for deep model training. Extensive experimental results on public datasets show that our method can significantly improve the performance on the UFGVC task of leaf cultivar identification.