 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreaking the Assistant Mold: Modeling Behavioral Variation in LLM Based Procedural Character Generation
Jan 06, 2026Procedural content generation has enabled vast virtual worlds through levels, maps, and quests, but large-scale character generation remains underexplored. We identify two alignment-induced biases in existing methods: a positive moral bias, where characters uniformly adopt agreeable stances (e.g. always saying lying is bad), and a helpful assistant bias, where characters invariably answer questions directly (e.g. never refusing or deflecting). While such tendencies suit instruction-following systems, they suppress dramatic tension and yield predictable characters, stemming from maximum likelihood training and assistant fine-tuning. To address this, we introduce PersonaWeaver, a framework that disentangles world-building (roles, demographics) from behavioral-building (moral stances, interactional styles), yielding characters with more diverse reactions and moral stances, as well as second-order diversity in stylistic markers like length, tone, and punctuation. Code: https://github.com/mqraitem/Persona-Weaver
CHAMMI-75: pre-training multi-channel models with heterogeneous microscopy images
Dec 23, 2025Quantifying cell morphology using images and machine learning has proven to be a powerful tool to study the response of cells to treatments. However, models used to quantify cellular morphology are typically trained with a single microscopy imaging type. This results in specialized models that cannot be reused across biological studies because the technical specifications do not match (e.g., different number of channels), or because the target experimental conditions are out of distribution. Here, we present CHAMMI-75, an open access dataset of heterogeneous, multi-channel microscopy images from 75 diverse biological studies. We curated this resource from publicly available sources to investigate cellular morphology models that are channel-adaptive and can process any microscopy image type. Our experiments show that training with CHAMMI-75 can improve performance in multi-channel bioimaging tasks primarily because of its high diversity in microscopy modalities. This work paves the way to create the next generation of cellular morphology models for biological studies.
Mull-Tokens: Modality-Agnostic Latent Thinking
Dec 11, 2025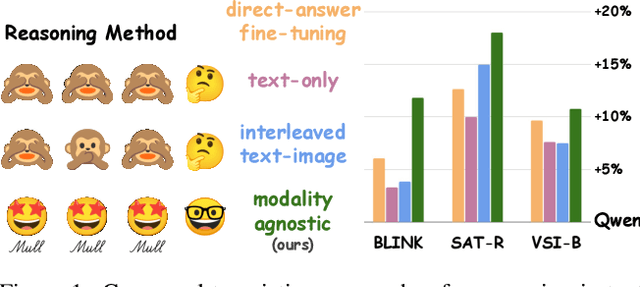
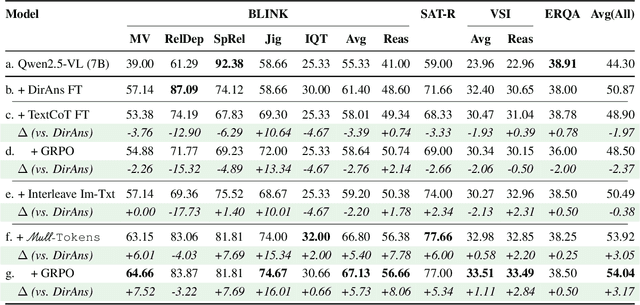
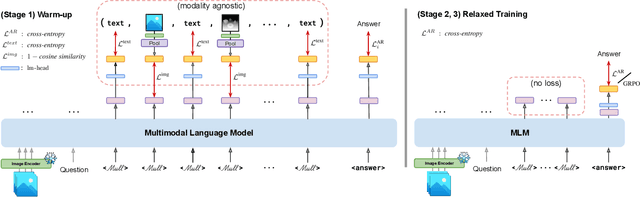
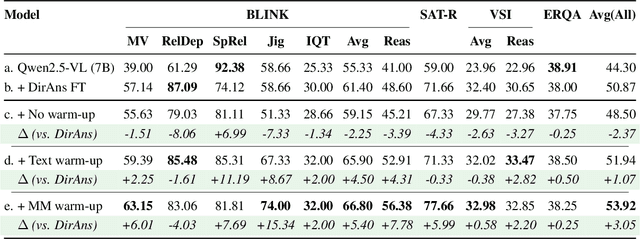
Reasoning goes beyond language; the real world requires reasoning about space, time, affordances, and much more that words alone cannot convey. Existing multimodal models exploring the potential of reasoning with images are brittle and do not scale. They rely on calling specialist tools, costly generation of images, or handcrafted reasoning data to switch between text and image thoughts. Instead, we offer a simpler alternative -- Mull-Tokens -- modality-agnostic latent tokens pre-trained to hold intermediate information in either image or text modalities to let the model think free-form towards the correct answer. We investigate best practices to train Mull-Tokens inspired by latent reasoning frameworks. We first train Mull-Tokens using supervision from interleaved text-image traces, and then fine-tune without any supervision by only using the final answers. Across four challenging spatial reasoning benchmarks involving tasks such as solving puzzles and taking different perspectives, we demonstrate that Mull-Tokens improve upon several baselines utilizing text-only reasoning or interleaved image-text reasoning, achieving a +3% average improvement and up to +16% on a puzzle solving reasoning-heavy split compared to our strongest baseline. Adding to conversations around challenges in grounding textual and visual reasoning, Mull-Tokens offers a simple solution to abstractly think in multiple modalities.
BabyVLM-V2: Toward Developmentally Grounded Pretraining and Benchmarking of Vision Foundation Models
Dec 11, 2025Early children's developmental trajectories set up a natural goal for sample-efficient pretraining of vision foundation models. We introduce BabyVLM-V2, a developmentally grounded framework for infant-inspired vision-language modeling that extensively improves upon BabyVLM-V1 through a longitudinal, multifaceted pretraining set, a versatile model, and, most importantly, DevCV Toolbox for cognitive evaluation. The pretraining set maximizes coverage while minimizing curation of a longitudinal, infant-centric audiovisual corpus, yielding video-utterance, image-utterance, and multi-turn conversational data that mirror infant experiences. DevCV Toolbox adapts all vision-related measures of the recently released NIH Baby Toolbox into a benchmark suite of ten multimodal tasks, covering spatial reasoning, memory, and vocabulary understanding aligned with early children's capabilities. Experimental results show that a compact model pretrained from scratch can achieve competitive performance on DevCV Toolbox, outperforming GPT-4o on some tasks. We hope the principled, unified BabyVLM-V2 framework will accelerate research in developmentally plausible pretraining of vision foundation models.
Real, Fake, or Manipulated? Detecting Machine-Influenced Text
Sep 18, 2025Large Language Model (LLMs) can be used to write or modify documents, presenting a challenge for understanding the intent behind their use. For example, benign uses may involve using LLM on a human-written document to improve its grammar or to translate it into another language. However, a document entirely produced by a LLM may be more likely to be used to spread misinformation than simple translation (\eg, from use by malicious actors or simply by hallucinating). Prior works in Machine Generated Text (MGT) detection mostly focus on simply identifying whether a document was human or machine written, ignoring these fine-grained uses. In this paper, we introduce a HiErarchical, length-RObust machine-influenced text detector (HERO), which learns to separate text samples of varying lengths from four primary types: human-written, machine-generated, machine-polished, and machine-translated. HERO accomplishes this by combining predictions from length-specialist models that have been trained with Subcategory Guidance. Specifically, for categories that are easily confused (\eg, different source languages), our Subcategory Guidance module encourages separation of the fine-grained categories, boosting performance. Extensive experiments across five LLMs and six domains demonstrate the benefits of our HERO, outperforming the state-of-the-art by 2.5-3 mAP on average.
Walk and Read Less: Improving the Efficiency of Vision-and-Language Navigation via Tuning-Free Multimodal Token Pruning
Sep 18, 2025Large models achieve strong performance on Vision-and-Language Navigation (VLN) tasks, but are costly to run in resource-limited environments. Token pruning offers appealing tradeoffs for efficiency with minimal performance loss by reducing model input size, but prior work overlooks VLN-specific challenges. For example, information loss from pruning can effectively increase computational cost due to longer walks. Thus, the inability to identify uninformative tokens undermines the supposed efficiency gains from pruning. To address this, we propose Navigation-Aware Pruning (NAP), which uses navigation-specific traits to simplify the pruning process by pre-filtering tokens into foreground and background. For example, image views are filtered based on whether the agent can navigate in that direction. We also extract navigation-relevant instructions using a Large Language Model. After filtering, we focus pruning on background tokens, minimizing information loss. To further help avoid increases in navigation length, we discourage backtracking by removing low-importance navigation nodes. Experiments on standard VLN benchmarks show NAP significantly outperforms prior work, preserving higher success rates while saving more than 50% FLOPS.
Right Side Up? Disentangling Orientation Understanding in MLLMs with Fine-grained Multi-axis Perception Tasks
May 29, 2025Object orientation understanding represents a fundamental challenge in visual perception critical for applications like robotic manipulation and augmented reality. Current vision-language benchmarks fail to isolate this capability, often conflating it with positional relationships and general scene understanding. We introduce DORI (Discriminative Orientation Reasoning Intelligence), a comprehensive benchmark establishing object orientation perception as a primary evaluation target. DORI assesses four dimensions of orientation comprehension: frontal alignment, rotational transformations, relative directional relationships, and canonical orientation understanding. Through carefully curated tasks from 11 datasets spanning 67 object categories across synthetic and real-world scenarios, DORI provides insights on how multi-modal systems understand object orientations. Our evaluation of 15 state-of-the-art vision-language models reveals critical limitations: even the best models achieve only 54.2% accuracy on coarse tasks and 33.0% on granular orientation judgments, with performance deteriorating for tasks requiring reference frame shifts or compound rotations. These findings demonstrate the need for dedicated orientation representation mechanisms, as models show systematic inability to perform precise angular estimations, track orientation changes across viewpoints, and understand compound rotations - suggesting limitations in their internal 3D spatial representations. As the first diagnostic framework specifically designed for orientation awareness in multimodal systems, DORI offers implications for improving robotic control, 3D scene reconstruction, and human-AI interaction in physical environments. DORI data: https://huggingface.co/datasets/appledora/DORI-Benchmark
ChA-MAEViT: Unifying Channel-Aware Masked Autoencoders and Multi-Channel Vision Transformers for Improved Cross-Channel Learning
Mar 25, 2025Prior work using Masked Autoencoders (MAEs) typically relies on random patch masking based on the assumption that images have significant redundancies across different channels, allowing for the reconstruction of masked content using cross-channel correlations. However, this assumption does not hold in Multi-Channel Imaging (MCI), where channels may provide complementary information with minimal feature overlap. Thus, these MAEs primarily learn local structures within individual channels from patch reconstruction, failing to fully leverage cross-channel interactions and limiting their MCI effectiveness. In this paper, we present ChA-MAEViT, an MAE-based method that enhances feature learning across MCI channels via four key strategies: (1) dynamic channel-patch masking, which compels the model to reconstruct missing channels in addition to masked patches, thereby enhancing cross-channel dependencies and improving robustness to varying channel configurations; (2) memory tokens, which serve as long-term memory aids to promote information sharing across channels, addressing the challenges of reconstructing structurally diverse channels; (3) hybrid token fusion module, which merges fine-grained patch tokens with a global class token to capture richer representations; and (4) Channel-Aware Decoder, a lightweight decoder utilizes channel tokens to effectively reconstruct image patches. Experiments on satellite and microscopy datasets, CHAMMI, JUMP-CP, and So2Sat, show that ChA-MAEViT significantly outperforms state-of-the-art MCI-ViTs by 3.0-21.5%, highlighting the importance of cross-channel interactions in MCI.
Web Artifact Attacks Disrupt Vision Language Models
Mar 17, 2025Vision-language models (VLMs) (e.g., CLIP, LLaVA) are trained on large-scale, lightly curated web datasets, leading them to learn unintended correlations between semantic concepts and unrelated visual signals. These associations degrade model accuracy by causing predictions to rely on incidental patterns rather than genuine visual understanding. Prior work has weaponized these correlations as an attack vector to manipulate model predictions, such as inserting a deceiving class text onto the image in a typographic attack. These attacks succeed due to VLMs' text-heavy bias-a result of captions that echo visible words rather than describing content. However, this attack has focused solely on text that matches the target class exactly, overlooking a broader range of correlations, including non-matching text and graphical symbols, which arise from the abundance of branding content in web-scale data. To address this gap, we introduce artifact-based attacks: a novel class of manipulations that mislead models using both non-matching text and graphical elements. Unlike typographic attacks, these artifacts are not predefined, making them harder to defend against but also more challenging to find. We address this by framing artifact attacks as a search problem and demonstrate their effectiveness across five datasets, with some artifacts reinforcing each other to reach 100% attack success rates. These attacks transfer across models with up to 90% effectiveness, making it possible to attack unseen models. To defend against these attacks, we extend prior work's artifact aware prompting to the graphical setting. We see a moderate reduction of success rates of up to 15% relative to standard prompts, suggesting a promising direction for enhancing model robustness.
Enhancing Virtual Try-On with Synthetic Pairs and Error-Aware Noise Scheduling
Jan 08, 2025



Given an isolated garment image in a canonical product view and a separate image of a person, the virtual try-on task aims to generate a new image of the person wearing the target garment. Prior virtual try-on works face two major challenges in achieving this goal: a) the paired (human, garment) training data has limited availability; b) generating textures on the human that perfectly match that of the prompted garment is difficult, often resulting in distorted text and faded textures. Our work explores ways to tackle these issues through both synthetic data as well as model refinement. We introduce a garment extraction model that generates (human, synthetic garment) pairs from a single image of a clothed individual. The synthetic pairs can then be used to augment the training of virtual try-on. We also propose an Error-Aware Refinement-based Schr\"odinger Bridge (EARSB) that surgically targets localized generation errors for correcting the output of a base virtual try-on model. To identify likely errors, we propose a weakly-supervised error classifier that localizes regions for refinement, subsequently augmenting the Schr\"odinger Bridge's noise schedule with its confidence heatmap. Experiments on VITON-HD and DressCode-Upper demonstrate that our synthetic data augmentation enhances the performance of prior work, while EARSB improves the overall image quality. In user studies, our model is preferred by the users in an average of 59% of cases.