 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Sensors Fail: Temporal Sequence Models for Robust PPO under Sensor Drift
Mar 04, 2026Real-world reinforcement learning systems must operate under distributional drift in their observation streams, yet most policy architectures implicitly assume fully observed and noise-free states. We study robustness of Proximal Policy Optimization (PPO) under temporally persistent sensor failures that induce partial observability and representation shift. To respond to this drift, we augment PPO with temporal sequence models, including Transformers and State Space Models (SSMs), to enable policies to infer missing information from history and maintain performance. Under a stochastic sensor failure process, we prove a high-probability bound on infinite-horizon reward degradation that quantifies how robustness depends on policy smoothness and failure persistence. Empirically, on MuJoCo continuous-control benchmarks with severe sensor dropout, we show Transformer-based sequence policies substantially outperform MLP, RNN, and SSM baselines in robustness, maintaining high returns even when large fractions of sensors are unavailable. These results demonstrate that temporal sequence reasoning provides a principled and practical mechanism for reliable operation under observation drift caused by sensor unreliability.
TxAgent: An AI Agent for Therapeutic Reasoning Across a Universe of Tools
Mar 14, 2025Precision therapeutics require multimodal adaptive models that generate personalized treatment recommendations. We introduce TxAgent, an AI agent that leverages multi-step reasoning and real-time biomedical knowledge retrieval across a toolbox of 211 tools to analyze drug interactions, contraindications, and patient-specific treatment strategies. TxAgent evaluates how drugs interact at molecular, pharmacokinetic, and clinical levels, identifies contraindications based on patient comorbidities and concurrent medications, and tailors treatment strategies to individual patient characteristics. It retrieves and synthesizes evidence from multiple biomedical sources, assesses interactions between drugs and patient conditions, and refines treatment recommendations through iterative reasoning. It selects tools based on task objectives and executes structured function calls to solve therapeutic tasks that require clinical reasoning and cross-source validation. The ToolUniverse consolidates 211 tools from trusted sources, including all US FDA-approved drugs since 1939 and validated clinical insights from Open Targets. TxAgent outperforms leading LLMs, tool-use models, and reasoning agents across five new benchmarks: DrugPC, BrandPC, GenericPC, TreatmentPC, and DescriptionPC, covering 3,168 drug reasoning tasks and 456 personalized treatment scenarios. It achieves 92.1% accuracy in open-ended drug reasoning tasks, surpassing GPT-4o and outperforming DeepSeek-R1 (671B) in structured multi-step reasoning. TxAgent generalizes across drug name variants and descriptions. By integrating multi-step inference, real-time knowledge grounding, and tool-assisted decision-making, TxAgent ensures that treatment recommendations align with established clinical guidelines and real-world evidence, reducing the risk of adverse events and improving therapeutic decision-making.
Is Large-Scale Pretraining the Secret to Good Domain Generalization?
Dec 03, 2024Multi-Source Domain Generalization (DG) is the task of training on multiple source domains and achieving high classification performance on unseen target domains. Recent methods combine robust features from web-scale pretrained backbones with new features learned from source data, and this has dramatically improved benchmark results. However, it remains unclear if DG finetuning methods are becoming better over time, or if improved benchmark performance is simply an artifact of stronger pre-training. Prior studies have shown that perceptual similarity to pre-training data correlates with zero-shot performance, but we find the effect limited in the DG setting. Instead, we posit that having perceptually similar data in pretraining is not enough; and that it is how well these data were learned that determines performance. This leads us to introduce the Alignment Hypothesis, which states that the final DG performance will be high if and only if alignment of image and class label text embeddings is high. Our experiments confirm the Alignment Hypothesis is true, and we use it as an analysis tool of existing DG methods evaluated on DomainBed datasets by splitting evaluation data into In-pretraining (IP) and Out-of-pretraining (OOP). We show that all evaluated DG methods struggle on DomainBed-OOP, while recent methods excel on DomainBed-IP. Put together, our findings highlight the need for DG methods which can generalize beyond pretraining alignment.
Zero-Shot Embeddings Inform Learning and Forgetting with Vision-Language Encoders
Jul 22, 2024Despite the proliferation of large vision-language foundation models, estimation of the learning and forgetting outcomes following fine-tuning of these models remains largely unexplored. Inspired by work highlighting the significance of the modality gap in contrastive dual-encoders, we propose the Inter-Intra Modal Measure (IIMM). Combining terms quantifying the similarity between image embeddings and the similarity between incorrect image and label embedding pairs, the IIMM functions as a strong predictor of performance changes with fine-tuning. Our extensive empirical analysis across four state-of-the-art vision-language models (CLIP, SigLIP, CoCa, EVA-02-CLIP) and five fine-tuning techniques (full fine-tuning, BitFit, attention-weight tuning, LoRA, CLIP-Adapter) demonstrates a strong, statistically significant linear relationship: fine-tuning on tasks with higher IIMM scores produces greater in-domain performance gains but also induces more severe out-of-domain performance degradation, with some parameter-efficient fine-tuning (PEFT) methods showing extreme forgetting. We compare our measure against transfer scores from state-of-the-art model selection methods and show that the IIMM is significantly more predictive of accuracy gains. With only a single forward pass of the target data, practitioners can leverage this key insight to heuristically evaluate the degree to which a model can be expected to improve following fine-tuning. Given additional knowledge about the model's performance on a few diverse tasks, this heuristic further evolves into a strong predictor of expected performance changes when training for new tasks.
UniTS: Building a Unified Time Series Model
Feb 29, 2024



Foundation models, especially LLMs, are profoundly transforming deep learning. Instead of training many task-specific models, we can adapt a single pretrained model to many tasks via fewshot prompting or fine-tuning. However, current foundation models apply to sequence data but not to time series, which present unique challenges due to the inherent diverse and multidomain time series datasets, diverging task specifications across forecasting, classification and other types of tasks, and the apparent need for task-specialized models. We developed UNITS, a unified time series model that supports a universal task specification, accommodating classification, forecasting, imputation, and anomaly detection tasks. This is achieved through a novel unified network backbone, which incorporates sequence and variable attention along with a dynamic linear operator and is trained as a unified model. Across 38 multi-domain datasets, UNITS demonstrates superior performance compared to task-specific models and repurposed natural language-based LLMs. UNITS exhibits remarkable zero-shot, few-shot, and prompt learning capabilities when evaluated on new data domains and tasks. The source code and datasets are available at https://github.com/mims-harvard/UniTS.
Quantified Task Misalignment to Inform PEFT: An Exploration of Domain Generalization and Catastrophic Forgetting in CLIP
Feb 14, 2024Foundations models are presented as generalists that often perform well over a myriad of tasks. Fine-tuning these models, even on limited data, provides an additional boost in task-specific performance but often at the cost of their wider generalization, an effect termed catastrophic forgetting. In this paper, we analyze the relation between task difficulty in the CLIP model and the performance of several simple parameter-efficient fine-tuning methods through the lens of domain generalization and catastrophic forgetting. We provide evidence that the silhouette score of the zero-shot image and text embeddings is a better measure of task difficulty than the average cosine similarity of correct image/label embeddings, and discuss observable relationships between task difficulty, fine-tuning method, domain generalization, and catastrophic forgetting. Additionally, the averaged results across tasks and performance measures demonstrate that a simplified method that trains only a subset of attention weights, which we call A-CLIP, yields a balance between domain generalization and catastrophic forgetting.
A Data Centric Approach for Unsupervised Domain Generalization via Retrieval from Web Scale Multimodal Data
Feb 06, 2024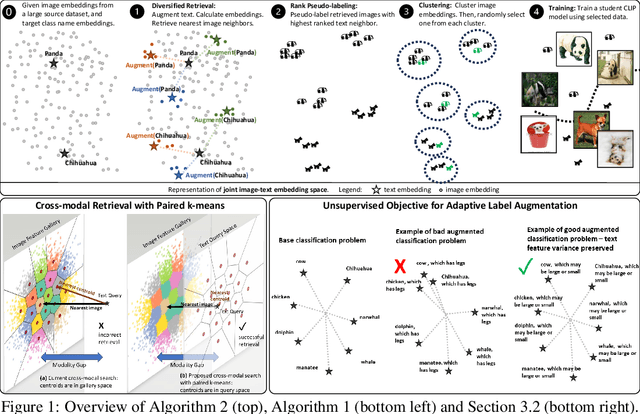
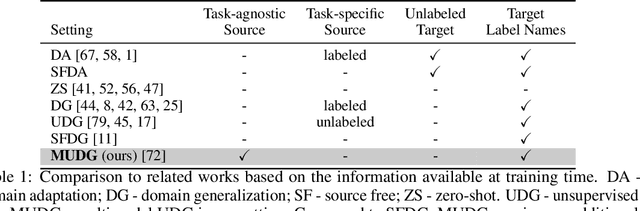
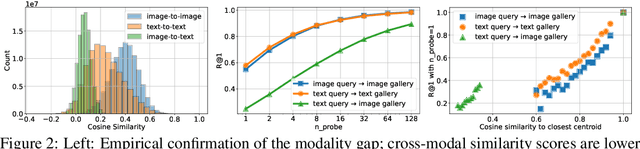
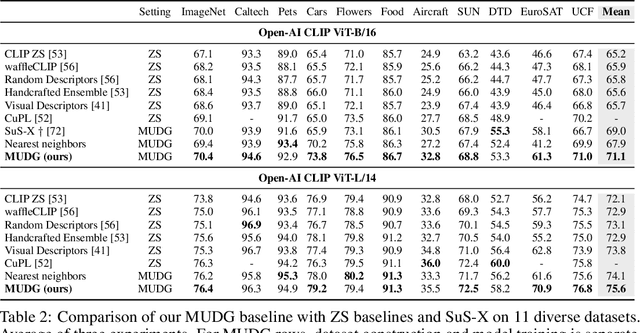
Domain generalization (DG) is an important problem that learns a model that can generalize to unseen test domains leveraging one or more source domains, under the assumption of shared label spaces. However, most DG methods assume access to abundant source data in the target label space, a requirement that proves overly stringent for numerous real-world applications, where acquiring the same label space as the target task is prohibitively expensive. For this setting, we tackle the multimodal version of the unsupervised domain generalization (UDG) problem, which uses a large task-agnostic unlabeled source dataset, such as LAION-2B during finetuning. Our framework does not explicitly assume any relationship between the source dataset and target task. Instead, it relies only on the premise that the source dataset can be efficiently searched in a joint vision-language space. For this multimodal UDG setting, we propose a novel method to build a small ($<$100K) subset of the source data in three simple steps: (1) diversified retrieval using label names as queries, (2) rank pseudo-labeling, and (3) clustering to find representative samples. To demonstrate the value of studying the multimodal UDG problem, we compare our results against state-of-the-art source-free DG and zero-shot (ZS) methods on their respective benchmarks and show up to 10% improvement in accuracy on 20 diverse target datasets. Additionally, our multi-stage dataset construction method achieves 3% improvement on average over nearest neighbors retrieval. Code is available: https://github.com/Chris210634/mudg
Image-Caption Encoding for Improving Zero-Shot Generalization
Feb 05, 2024Recent advances in vision-language models have combined contrastive approaches with generative methods to achieve state-of-the-art (SOTA) on downstream inference tasks like zero-shot image classification. However, a persistent issue of these models for image classification is their out-of-distribution (OOD) generalization capabilities. We first show that when an OOD data point is misclassified, the correct class can be typically found in the Top-K predicted classes. In order to steer the model prediction toward the correct class within the top predicted classes, we propose the Image-Caption Encoding (ICE) method, a straightforward approach that directly enforces consistency between the image-conditioned and caption-conditioned predictions at evaluation time only. Intuitively, we take advantage of unique properties of the generated captions to guide our local search for the correct class label within the Top-K predicted classes. We show that our method can be easily combined with other SOTA methods to enhance Top-1 OOD accuracies by 0.5% on average and up to 3% on challenging datasets. Our code: https://github.com/Chris210634/ice
Descriptor and Word Soups: Overcoming the Parameter Efficiency Accuracy Tradeoff for Out-of-Distribution Few-shot Learning
Nov 21, 2023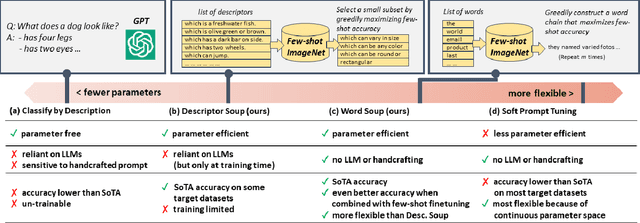
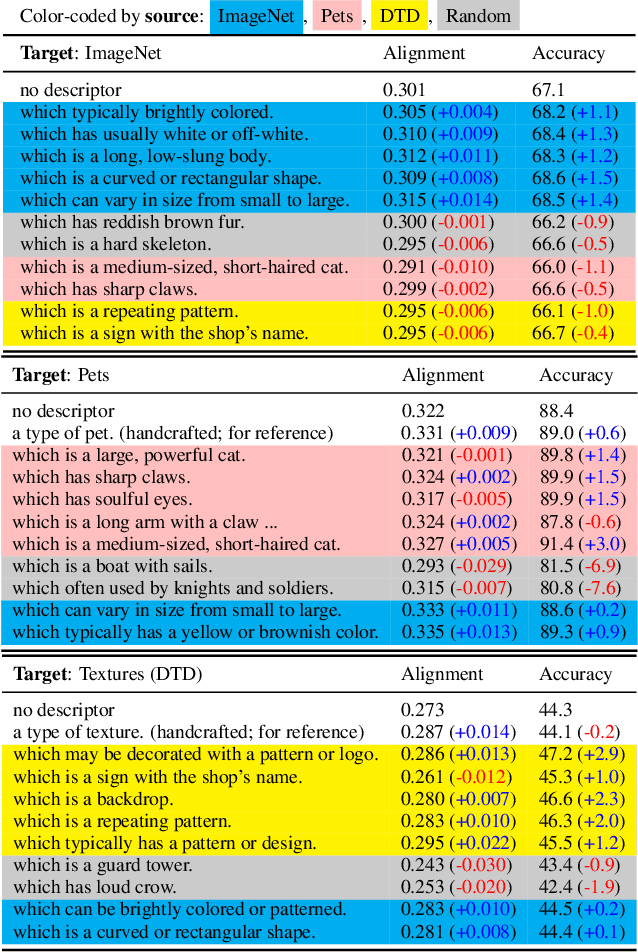

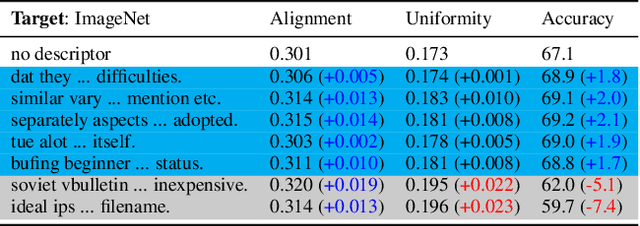
Over the past year, a large body of multimodal research has emerged around zero-shot evaluation using GPT descriptors. These studies boost the zero-shot accuracy of pretrained VL models with an ensemble of label-specific text generated by GPT. A recent study, WaffleCLIP, demonstrated that similar zero-shot accuracy can be achieved with an ensemble of random descriptors. However, both zero-shot methods are un-trainable and consequently sub-optimal when some few-shot out-of-distribution (OOD) training data is available. Inspired by these prior works, we present two more flexible methods called descriptor and word soups, which do not require an LLM at test time and can leverage training data to increase OOD target accuracy. Descriptor soup greedily selects a small set of textual descriptors using generic few-shot training data, then calculates robust class embeddings using the selected descriptors. Word soup greedily assembles a chain of words in a similar manner. Compared to existing few-shot soft prompt tuning methods, word soup requires fewer parameters by construction and less GPU memory, since it does not require backpropagation. Both soups outperform current published few-shot methods, even when combined with SoTA zero-shot methods, on cross-dataset and domain generalization benchmarks. Compared with SoTA prompt and descriptor ensembling methods, such as ProDA and WaffleCLIP, word soup achieves higher OOD accuracy with fewer ensemble members. Please checkout our code: github.com/Chris210634/word_soups
Robust Fine-Tuning of Vision-Language Models for Domain Generalization
Nov 03, 2023



Transfer learning enables the sharing of common knowledge among models for a variety of downstream tasks, but traditional methods suffer in limited training data settings and produce narrow models incapable of effectively generalizing under distribution shifts. Foundation models have recently demonstrated impressive zero-shot inference capabilities and robustness under distribution shifts. However, zero-shot evaluation for these models has been predominantly confined to benchmarks with simple distribution shifts, limiting our understanding of their effectiveness under the more realistic shifts found in practice. Moreover, common fine-tuning methods for these models have yet to be evaluated against vision models in few-shot scenarios where training data is limited. To address these gaps, we present a new recipe for few-shot fine-tuning of the popular vision-language foundation model CLIP and evaluate its performance on challenging benchmark datasets with realistic distribution shifts from the WILDS collection. Our experimentation demonstrates that, while zero-shot CLIP fails to match performance of trained vision models on more complex benchmarks, few-shot CLIP fine-tuning outperforms its vision-only counterparts in terms of in-distribution and out-of-distribution accuracy at all levels of training data availability. This provides a strong incentive for adoption of foundation models within few-shot learning applications operating with real-world data. Code is available at https://github.com/mit-ll/robust-vision-language-finetuning