 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Data Centric Approach for Unsupervised Domain Generalization via Retrieval from Web Scale Multimodal Data
Feb 06, 2024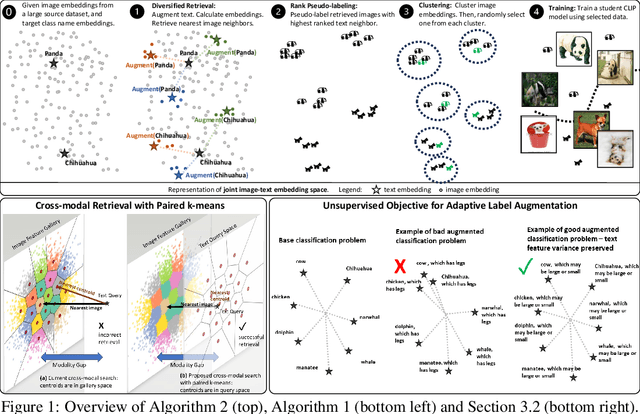
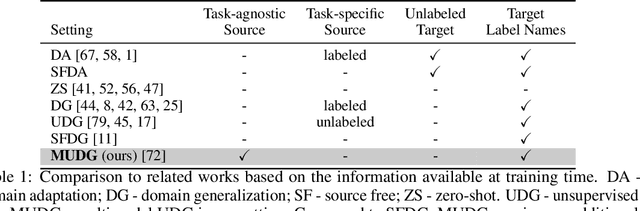
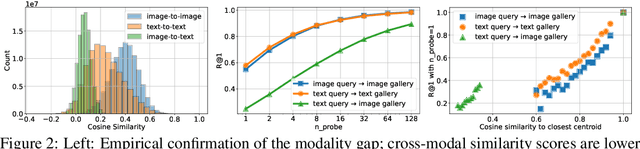
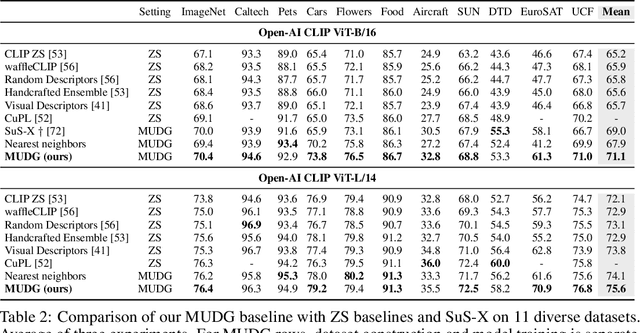
Domain generalization (DG) is an important problem that learns a model that can generalize to unseen test domains leveraging one or more source domains, under the assumption of shared label spaces. However, most DG methods assume access to abundant source data in the target label space, a requirement that proves overly stringent for numerous real-world applications, where acquiring the same label space as the target task is prohibitively expensive. For this setting, we tackle the multimodal version of the unsupervised domain generalization (UDG) problem, which uses a large task-agnostic unlabeled source dataset, such as LAION-2B during finetuning. Our framework does not explicitly assume any relationship between the source dataset and target task. Instead, it relies only on the premise that the source dataset can be efficiently searched in a joint vision-language space. For this multimodal UDG setting, we propose a novel method to build a small ($<$100K) subset of the source data in three simple steps: (1) diversified retrieval using label names as queries, (2) rank pseudo-labeling, and (3) clustering to find representative samples. To demonstrate the value of studying the multimodal UDG problem, we compare our results against state-of-the-art source-free DG and zero-shot (ZS) methods on their respective benchmarks and show up to 10% improvement in accuracy on 20 diverse target datasets. Additionally, our multi-stage dataset construction method achieves 3% improvement on average over nearest neighbors retrieval. Code is available: https://github.com/Chris210634/mudg
Image-Caption Encoding for Improving Zero-Shot Generalization
Feb 05, 2024Recent advances in vision-language models have combined contrastive approaches with generative methods to achieve state-of-the-art (SOTA) on downstream inference tasks like zero-shot image classification. However, a persistent issue of these models for image classification is their out-of-distribution (OOD) generalization capabilities. We first show that when an OOD data point is misclassified, the correct class can be typically found in the Top-K predicted classes. In order to steer the model prediction toward the correct class within the top predicted classes, we propose the Image-Caption Encoding (ICE) method, a straightforward approach that directly enforces consistency between the image-conditioned and caption-conditioned predictions at evaluation time only. Intuitively, we take advantage of unique properties of the generated captions to guide our local search for the correct class label within the Top-K predicted classes. We show that our method can be easily combined with other SOTA methods to enhance Top-1 OOD accuracies by 0.5% on average and up to 3% on challenging datasets. Our code: https://github.com/Chris210634/ice
Descriptor and Word Soups: Overcoming the Parameter Efficiency Accuracy Tradeoff for Out-of-Distribution Few-shot Learning
Nov 21, 2023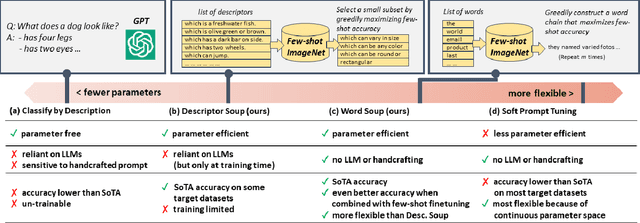
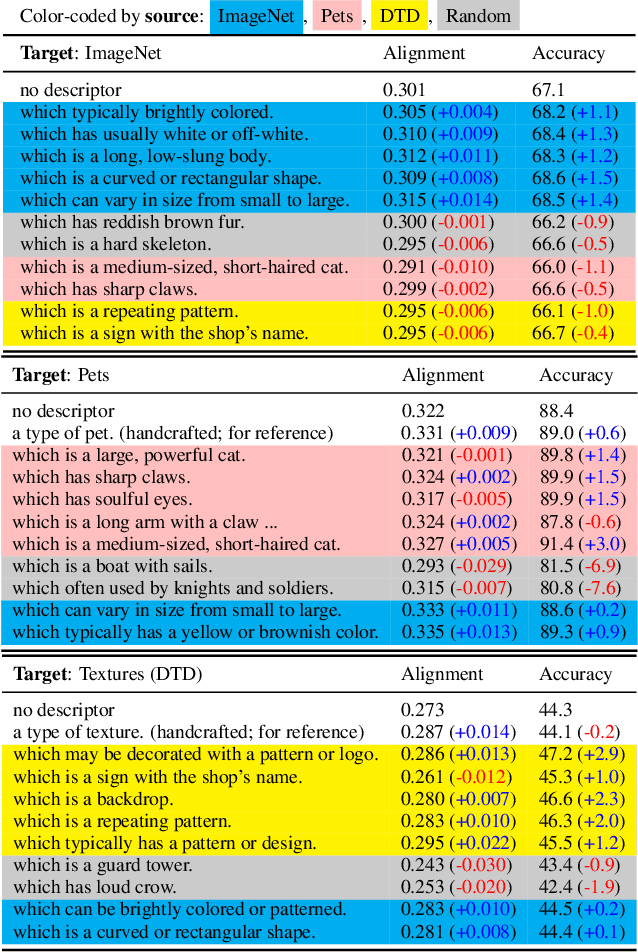

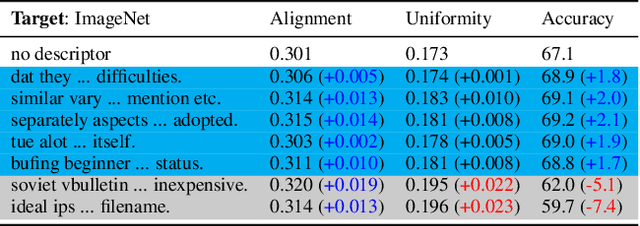
Over the past year, a large body of multimodal research has emerged around zero-shot evaluation using GPT descriptors. These studies boost the zero-shot accuracy of pretrained VL models with an ensemble of label-specific text generated by GPT. A recent study, WaffleCLIP, demonstrated that similar zero-shot accuracy can be achieved with an ensemble of random descriptors. However, both zero-shot methods are un-trainable and consequently sub-optimal when some few-shot out-of-distribution (OOD) training data is available. Inspired by these prior works, we present two more flexible methods called descriptor and word soups, which do not require an LLM at test time and can leverage training data to increase OOD target accuracy. Descriptor soup greedily selects a small set of textual descriptors using generic few-shot training data, then calculates robust class embeddings using the selected descriptors. Word soup greedily assembles a chain of words in a similar manner. Compared to existing few-shot soft prompt tuning methods, word soup requires fewer parameters by construction and less GPU memory, since it does not require backpropagation. Both soups outperform current published few-shot methods, even when combined with SoTA zero-shot methods, on cross-dataset and domain generalization benchmarks. Compared with SoTA prompt and descriptor ensembling methods, such as ProDA and WaffleCLIP, word soup achieves higher OOD accuracy with fewer ensemble members. Please checkout our code: github.com/Chris210634/word_soups
Supervised Metric Learning for Retrieval via Contextual Similarity Optimization
Oct 04, 2022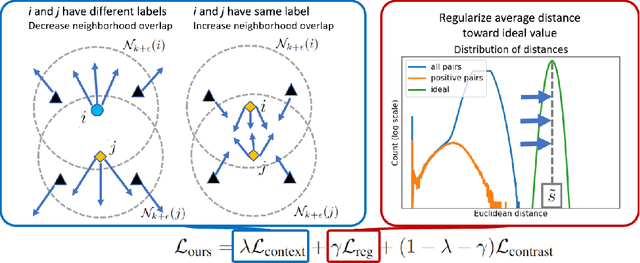
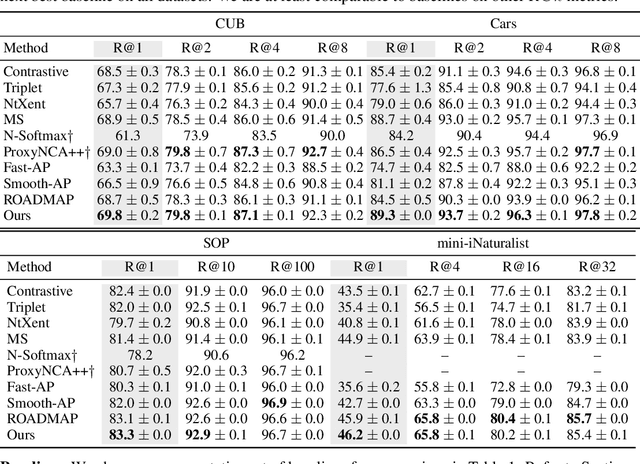
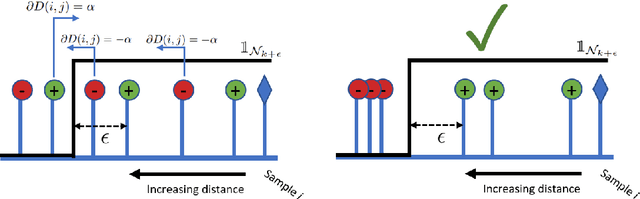
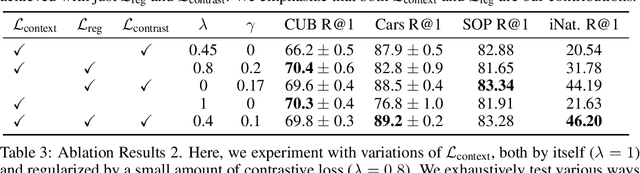
Existing deep metric learning approaches fall into three general categories: contrastive learning, average precision (AP) maximization, and classification. We propose a novel alternative approach, \emph{contextual similarity optimization}, inspired by work in unsupervised metric learning. Contextual similarity is a discrete similarity measure based on relationships between neighborhood sets, and is widely used in the unsupervised setting as pseudo-supervision. Inspired by this success, we propose a framework which optimizes \emph{a combination of contextual and cosine similarities}. Contextual similarity calculation involves several non-differentiable operations, including the heaviside function and intersection of sets. We show how to circumvent non-differentiability to explicitly optimize contextual similarity, and we further incorporate appropriate similarity regularization to yield our novel metric learning loss. The resulting loss function achieves state-of-the-art Recall @ 1 accuracy on standard supervised image retrieval benchmarks when combined with the standard contrastive loss. Code is released here: \url{https://github.com/Chris210634/metric-learning-using-contextual-similarity}
Pick up the PACE: Fast and Simple Domain Adaptation via Ensemble Pseudo-Labeling
May 26, 2022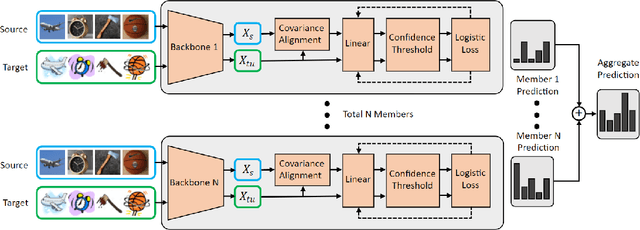
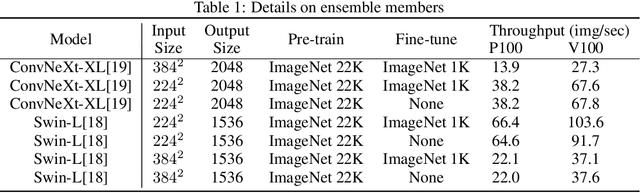
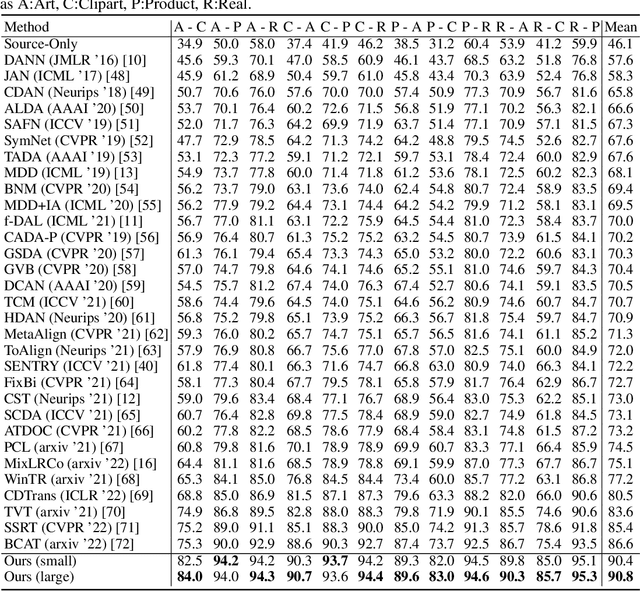
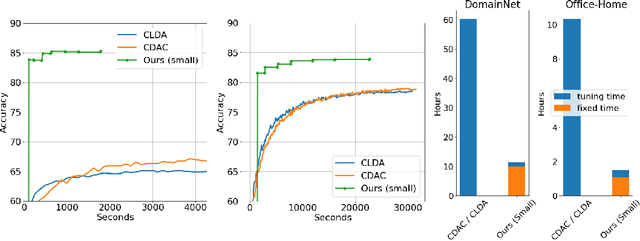
Domain Adaptation (DA) has received widespread attention from deep learning researchers in recent years because of its potential to improve test accuracy with out-of-distribution labeled data. Most state-of-the-art DA algorithms require an extensive amount of hyperparameter tuning and are computationally intensive due to the large batch sizes required. In this work, we propose a fast and simple DA method consisting of three stages: (1) domain alignment by covariance matching, (2) pseudo-labeling, and (3) ensembling. We call this method $\textbf{PACE}$, for $\textbf{P}$seudo-labels, $\textbf{A}$lignment of $\textbf{C}$ovariances, and $\textbf{E}$nsembles. PACE is trained on top of fixed features extracted from an ensemble of modern pretrained backbones. PACE exceeds previous state-of-the-art by $\textbf{5 - 10 \%}$ on most benchmark adaptation tasks without training a neural network. PACE reduces training time and hyperparameter tuning time by $82\%$ and $97\%$, respectively, when compared to state-of-the-art DA methods. Code is released here: https://github.com/Chris210634/PACE-Domain-Adaptation
Faster Convex Lipschitz Regression via 2-block ADMM
Nov 29, 2021
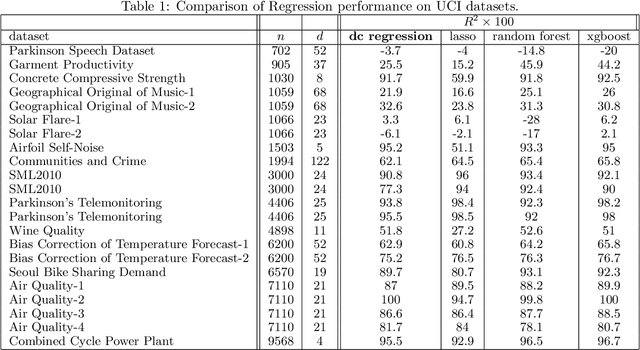
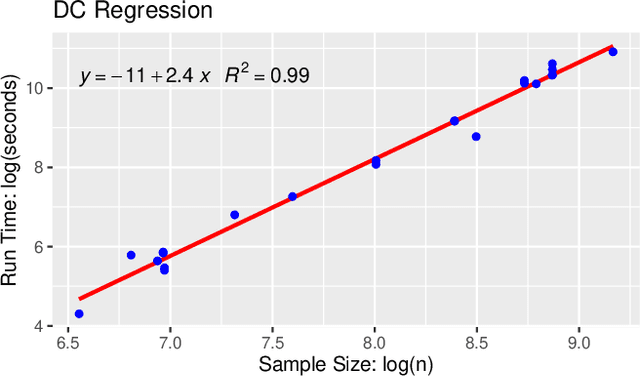
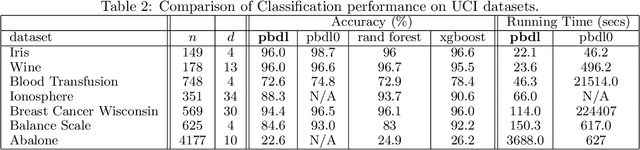
The task of approximating an arbitrary convex function arises in several learning problems such as convex regression, learning with a difference of convex (DC) functions, and approximating Bregman divergences. In this paper, we show how a broad class of convex function learning problems can be solved via a 2-block ADMM approach, where updates for each block can be computed in closed form. For the task of convex Lipschitz regression, we establish that our proposed algorithm converges with iteration complexity of $ O(n\sqrt{d}/\epsilon)$ for a dataset $ X \in \mathbb R^{n\times d}$ and $\epsilon > 0$. Combined with per-iteration computation complexity, our method converges with the rate $O(n^3 d^{1.5}/\epsilon+n^2 d^{2.5}/\epsilon+n d^3/\epsilon)$. This new rate improves the state of the art rate of $O(n^5d^2/\epsilon)$ available by interior point methods if $d = o( n^4)$. Further we provide similar solvers for DC regression and Bregman divergence learning. Unlike previous approaches, our method is amenable to the use of GPUs. We demonstrate on regression and metric learning experiments that our approach is up to 30 times faster than the existing method, and produces results that are comparable to state-of-the-art.