 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Data Centric Approach for Unsupervised Domain Generalization via Retrieval from Web Scale Multimodal Data
Paper and Code
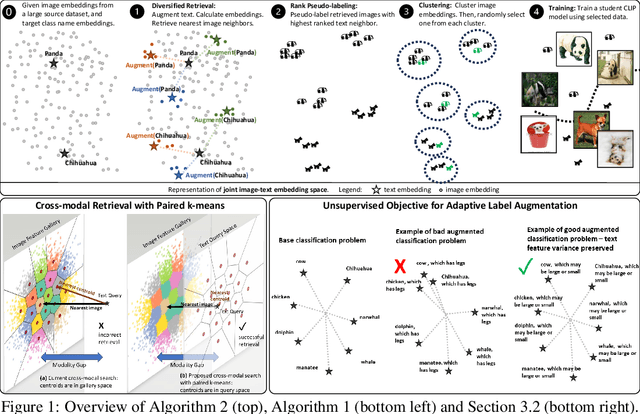
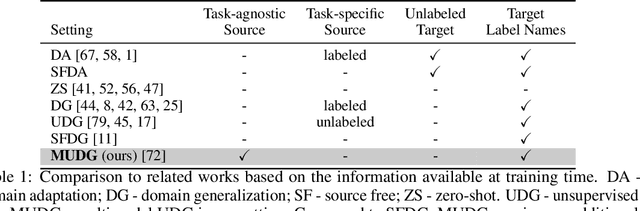
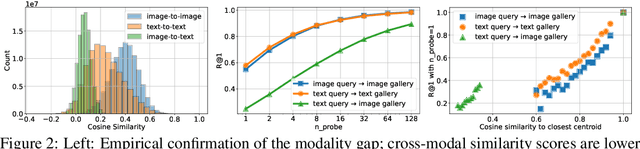
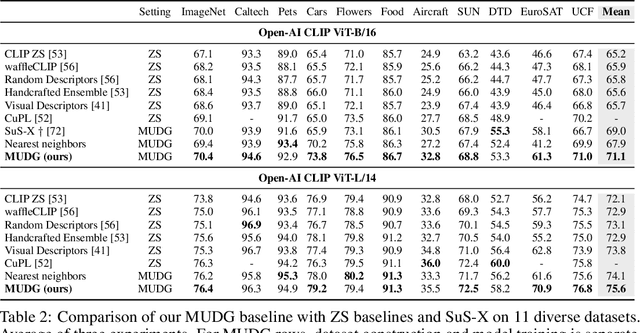
Domain generalization (DG) is an important problem that learns a model that can generalize to unseen test domains leveraging one or more source domains, under the assumption of shared label spaces. However, most DG methods assume access to abundant source data in the target label space, a requirement that proves overly stringent for numerous real-world applications, where acquiring the same label space as the target task is prohibitively expensive. For this setting, we tackle the multimodal version of the unsupervised domain generalization (UDG) problem, which uses a large task-agnostic unlabeled source dataset, such as LAION-2B during finetuning. Our framework does not explicitly assume any relationship between the source dataset and target task. Instead, it relies only on the premise that the source dataset can be efficiently searched in a joint vision-language space. For this multimodal UDG setting, we propose a novel method to build a small ($<$100K) subset of the source data in three simple steps: (1) diversified retrieval using label names as queries, (2) rank pseudo-labeling, and (3) clustering to find representative samples. To demonstrate the value of studying the multimodal UDG problem, we compare our results against state-of-the-art source-free DG and zero-shot (ZS) methods on their respective benchmarks and show up to 10% improvement in accuracy on 20 diverse target datasets. Additionally, our multi-stage dataset construction method achieves 3% improvement on average over nearest neighbors retrieval. Code is available: https://github.com/Chris210634/mudg