 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Robustness of Reward Models for Language Model Alignment
May 12, 2025The Bradley-Terry (BT) model is widely practiced in reward modeling for reinforcement learning with human feedback (RLHF). Despite its effectiveness, reward models (RMs) trained with BT model loss are prone to over-optimization, losing generalizability to unseen input distributions. In this paper, we study the cause of over-optimization in RM training and its downstream effects on the RLHF procedure, accentuating the importance of distributional robustness of RMs in unseen data. First, we show that the excessive dispersion of hidden state norms is the main source of over-optimization. Then, we propose batch-wise sum-to-zero regularization (BSR) to enforce zero-centered reward sum per batch, constraining the rewards with extreme magnitudes. We assess the impact of BSR in improving robustness in RMs through four scenarios of over-optimization, where BSR consistently manifests better robustness. Subsequently, we compare the plain BT model and BSR on RLHF training and empirically show that robust RMs better align the policy to the gold preference model. Finally, we apply BSR to high-quality data and models, which surpasses state-of-the-art RMs in the 8B scale by adding more than 5% in complex preference prediction tasks. By conducting RLOO training with 8B RMs, AlpacaEval 2.0 reduces generation length by 40% while adding a 7% increase in win rate, further highlighting that robustness in RMs induces robustness in RLHF training. We release the code, data, and models: https://github.com/LinkedIn-XFACT/RM-Robustness.
AlphaPO -- Reward shape matters for LLM alignment
Jan 07, 2025Reinforcement Learning with Human Feedback (RLHF) and its variants have made huge strides toward the effective alignment of large language models (LLMs) to follow instructions and reflect human values. More recently, Direct Alignment Algorithms (DAAs) have emerged in which the reward modeling stage of RLHF is skipped by characterizing the reward directly as a function of the policy being learned. Examples include Direct Preference Optimization (DPO) and Simple Preference Optimization (SimPO). These methods often suffer from likelihood displacement, a phenomenon by which the probabilities of preferred responses are often reduced undesirably. In this paper, we argue that, for DAAs the reward (function) shape matters. We introduce AlphaPO, a new DAA method that leverages an $\alpha$-parameter to help change the shape of the reward function beyond the standard log reward. AlphaPO helps maintain fine-grained control over likelihood displacement and over-optimization. Compared to SimPO, one of the best performing DAAs, AlphaPO leads to about 7\% to 10\% relative improvement in alignment performance for the instruct versions of Mistral-7B and Llama3-8B. The analysis and results presented highlight the importance of the reward shape, and how one can systematically change it to affect training dynamics, as well as improve alignment performance.
Evaluating the Consistency of LLM Evaluators
Nov 30, 2024



Large language models (LLMs) have shown potential as general evaluators along with the evident benefits of speed and cost. While their correlation against human annotators has been widely studied, consistency as evaluators is still understudied, raising concerns about the reliability of LLM evaluators. In this paper, we conduct extensive studies on the two aspects of consistency in LLM evaluations, Self-Consistency (SC) and Inter-scale Consistency (IC), on different scoring scales and criterion granularity with open-source and proprietary models. Our comprehensive analysis demonstrates that strong proprietary models are not necessarily consistent evaluators, highlighting the importance of considering consistency in assessing the capability of LLM evaluators.
Cross-lingual Transfer of Reward Models in Multilingual Alignment
Oct 23, 2024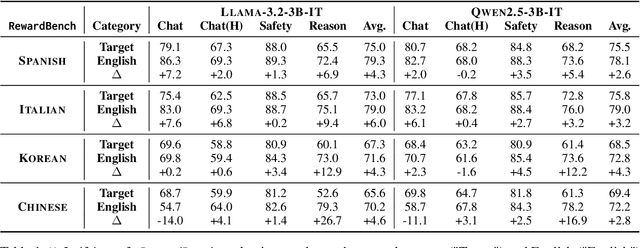
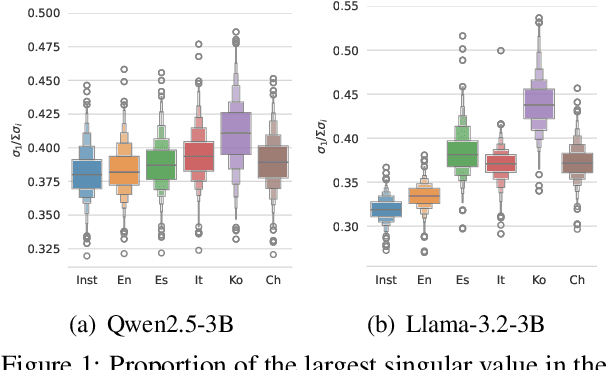
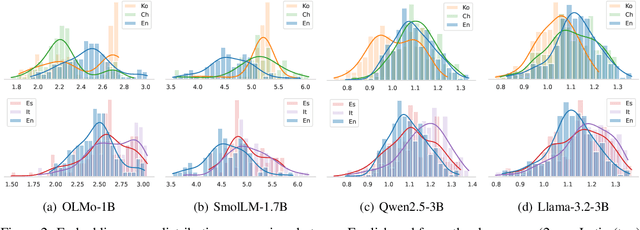

Reinforcement learning with human feedback (RLHF) is shown to largely benefit from precise reward models (RMs). However, recent studies in reward modeling schemes are skewed towards English, limiting the applicability of RLHF in multilingual alignments. In this work, we investigate the cross-lingual transfer of RMs trained in diverse languages, primarily from English. Our experimental results demonstrate the strong cross-lingual transfer of English RMs, exceeding target language RMs by 3~4% average increase in Multilingual RewardBench. Furthermore, we analyze the cross-lingual transfer of RMs through the representation shifts. Finally, we perform multilingual alignment to exemplify how cross-lingual transfer in RM propagates to enhanced multilingual instruction-following capability, along with extensive analyses on off-the-shelf RMs. We release the code, model, and data.
Margin-aware Preference Optimization for Aligning Diffusion Models without Reference
Jun 10, 2024Modern alignment techniques based on human preferences, such as RLHF and DPO, typically employ divergence regularization relative to the reference model to ensure training stability. However, this often limits the flexibility of models during alignment, especially when there is a clear distributional discrepancy between the preference data and the reference model. In this paper, we focus on the alignment of recent text-to-image diffusion models, such as Stable Diffusion XL (SDXL), and find that this "reference mismatch" is indeed a significant problem in aligning these models due to the unstructured nature of visual modalities: e.g., a preference for a particular stylistic aspect can easily induce such a discrepancy. Motivated by this observation, we propose a novel and memory-friendly preference alignment method for diffusion models that does not depend on any reference model, coined margin-aware preference optimization (MaPO). MaPO jointly maximizes the likelihood margin between the preferred and dispreferred image sets and the likelihood of the preferred sets, simultaneously learning general stylistic features and preferences. For evaluation, we introduce two new pairwise preference datasets, which comprise self-generated image pairs from SDXL, Pick-Style and Pick-Safety, simulating diverse scenarios of reference mismatch. Our experiments validate that MaPO can significantly improve alignment on Pick-Style and Pick-Safety and general preference alignment when used with Pick-a-Pic v2, surpassing the base SDXL and other existing methods. Our code, models, and datasets are publicly available via https://mapo-t2i.github.io
The BiGGen Bench: A Principled Benchmark for Fine-grained Evaluation of Language Models with Language Models
Jun 09, 2024



As language models (LMs) become capable of handling a wide range of tasks, their evaluation is becoming as challenging as their development. Most generation benchmarks currently assess LMs using abstract evaluation criteria like helpfulness and harmlessness, which often lack the flexibility and granularity of human assessment. Additionally, these benchmarks tend to focus disproportionately on specific capabilities such as instruction following, leading to coverage bias. To overcome these limitations, we introduce the BiGGen Bench, a principled generation benchmark designed to thoroughly evaluate nine distinct capabilities of LMs across 77 diverse tasks. A key feature of the BiGGen Bench is its use of instance-specific evaluation criteria, closely mirroring the nuanced discernment of human evaluation. We apply this benchmark to assess 103 frontier LMs using five evaluator LMs. Our code, data, and evaluation results are all publicly available at https://github.com/prometheus-eval/prometheus-eval/tree/main/BiGGen-Bench.
ORPO: Monolithic Preference Optimization without Reference Model
Mar 14, 2024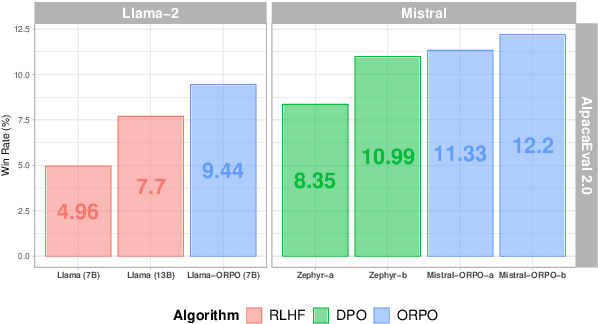
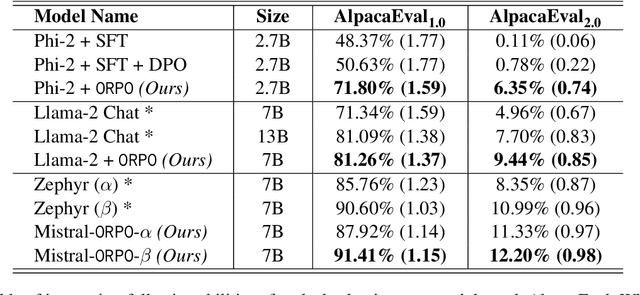
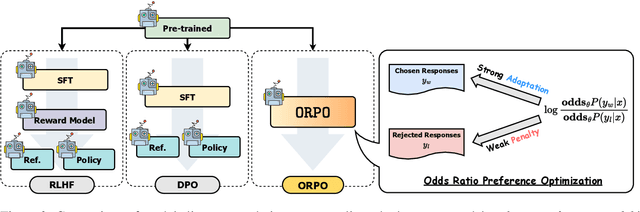
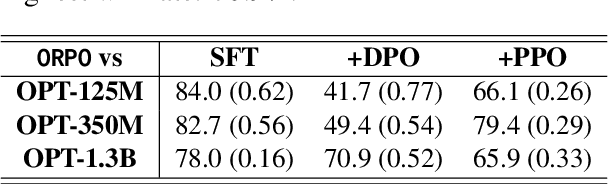
While recent preference alignment algorithms for language models have demonstrated promising results, supervised fine-tuning (SFT) remains imperative for achieving successful convergence. In this paper, we study the crucial role of SFT within the context of preference alignment, emphasizing that a minor penalty for the disfavored generation style is sufficient for preference-aligned SFT. Building on this foundation, we introduce a straightforward and innovative reference model-free monolithic odds ratio preference optimization algorithm, ORPO, eliminating the necessity for an additional preference alignment phase. We demonstrate, both empirically and theoretically, that the odds ratio is a sensible choice for contrasting favored and disfavored styles during SFT across the diverse sizes from 125M to 7B. Specifically, fine-tuning Phi-2 (2.7B), Llama-2 (7B), and Mistral (7B) with ORPO on the UltraFeedback alone surpasses the performance of state-of-the-art language models with more than 7B and 13B parameters: achieving up to 12.20% on $\text{AlpacaEval}_{2.0}$ (Figure 1), 66.19% on IFEval (instruction-level loose, Table 6), and 7.32 in MT-Bench (Figure 12). We release code and model checkpoints for Mistral-ORPO-$\alpha$ (7B) and Mistral-ORPO-$\beta$ (7B).
Robust Fine-Tuning of Vision-Language Models for Domain Generalization
Nov 03, 2023



Transfer learning enables the sharing of common knowledge among models for a variety of downstream tasks, but traditional methods suffer in limited training data settings and produce narrow models incapable of effectively generalizing under distribution shifts. Foundation models have recently demonstrated impressive zero-shot inference capabilities and robustness under distribution shifts. However, zero-shot evaluation for these models has been predominantly confined to benchmarks with simple distribution shifts, limiting our understanding of their effectiveness under the more realistic shifts found in practice. Moreover, common fine-tuning methods for these models have yet to be evaluated against vision models in few-shot scenarios where training data is limited. To address these gaps, we present a new recipe for few-shot fine-tuning of the popular vision-language foundation model CLIP and evaluate its performance on challenging benchmark datasets with realistic distribution shifts from the WILDS collection. Our experimentation demonstrates that, while zero-shot CLIP fails to match performance of trained vision models on more complex benchmarks, few-shot CLIP fine-tuning outperforms its vision-only counterparts in terms of in-distribution and out-of-distribution accuracy at all levels of training data availability. This provides a strong incentive for adoption of foundation models within few-shot learning applications operating with real-world data. Code is available at https://github.com/mit-ll/robust-vision-language-finetuning
Can Large Language Models Infer and Disagree Like Humans?
May 23, 2023Large Language Models (LLMs) have shown stellar achievements in solving a broad range of tasks. When generating text, it is common to sample tokens from these models: whether LLMs closely align with the human disagreement distribution has not been well-studied, especially within the scope of Natural Language Inference (NLI). In this paper, we evaluate the performance and alignment of LLM distribution with humans using two different techniques: Monte Carlo Reconstruction (MCR) and Log Probability Reconstruction (LPR). As a result, we show LLMs exhibit limited ability in solving NLI tasks and simultaneously fail to capture human disagreement distribution, raising concerns about their natural language understanding (NLU) ability and their representativeness of human users.