 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLegalSearchLM: Rethinking Legal Case Retrieval as Legal Elements Generation
May 28, 2025



Legal Case Retrieval (LCR), which retrieves relevant cases from a query case, is a fundamental task for legal professionals in research and decision-making. However, existing studies on LCR face two major limitations. First, they are evaluated on relatively small-scale retrieval corpora (e.g., 100-55K cases) and use a narrow range of criminal query types, which cannot sufficiently reflect the complexity of real-world legal retrieval scenarios. Second, their reliance on embedding-based or lexical matching methods often results in limited representations and legally irrelevant matches. To address these issues, we present: (1) LEGAR BENCH, the first large-scale Korean LCR benchmark, covering 411 diverse crime types in queries over 1.2M legal cases; and (2) LegalSearchLM, a retrieval model that performs legal element reasoning over the query case and directly generates content grounded in the target cases through constrained decoding. Experimental results show that LegalSearchLM outperforms baselines by 6-20% on LEGAR BENCH, achieving state-of-the-art performance. It also demonstrates strong generalization to out-of-domain cases, outperforming naive generative models trained on in-domain data by 15%.
FREESON: Retriever-Free Retrieval-Augmented Reasoning via Corpus-Traversing MCTS
May 22, 2025Large Reasoning Models (LRMs) have demonstrated remarkable capabilities in multi-step reasoning and calling search engines at appropriate steps. However, existing retrieval-augmented reasoning approaches rely on separate retrieval models, limiting the LRM's role in retrieval to deciding when to retrieve and how to query. This separation not only increases hardware and operational costs but also leads to errors in the retrieval process due to the representation bottleneck, a phenomenon where the retriever's embedding space is not expressive enough to meet the generator's requirements. To address this, we shift our perspective from sequence-to-sequence matching to locating the answer-containing paths within the corpus, and propose a novel framework called FREESON (Retriever-FREE Retrieval-Augmented ReaSONing). This framework enables LRMs to retrieve relevant knowledge on their own by acting as both a generator and retriever. To achieve this, we introduce a variant of the MCTS algorithm specialized for the retrieval task, which we call CT-MCTS (Corpus-Traversing Monte Carlo Tree Search). In this algorithm, LRMs traverse through the corpus toward answer-containing regions. Our results on five open-domain QA benchmarks, including single-hop and multi-hop questions, show that FREESON achieves an average improvement of 14.4% in EM and F1 over four multi-step reasoning models with a separate retriever, and it also performs comparably to the strongest baseline, surpassing it by 3% on PopQA and 2WikiMultihopQA.
The BiGGen Bench: A Principled Benchmark for Fine-grained Evaluation of Language Models with Language Models
Jun 09, 2024



As language models (LMs) become capable of handling a wide range of tasks, their evaluation is becoming as challenging as their development. Most generation benchmarks currently assess LMs using abstract evaluation criteria like helpfulness and harmlessness, which often lack the flexibility and granularity of human assessment. Additionally, these benchmarks tend to focus disproportionately on specific capabilities such as instruction following, leading to coverage bias. To overcome these limitations, we introduce the BiGGen Bench, a principled generation benchmark designed to thoroughly evaluate nine distinct capabilities of LMs across 77 diverse tasks. A key feature of the BiGGen Bench is its use of instance-specific evaluation criteria, closely mirroring the nuanced discernment of human evaluation. We apply this benchmark to assess 103 frontier LMs using five evaluator LMs. Our code, data, and evaluation results are all publicly available at https://github.com/prometheus-eval/prometheus-eval/tree/main/BiGGen-Bench.
How Well Do Large Language Models Truly Ground?
Nov 15, 2023



Reliance on the inherent knowledge of Large Language Models (LLMs) can cause issues such as hallucinations, lack of control, and difficulties in integrating variable knowledge. To mitigate this, LLMs can be probed to generate responses by grounding on external context, often given as input (knowledge-augmented models). Yet, previous research is often confined to a narrow view of the term "grounding", often only focusing on whether the response contains the correct answer or not, which does not ensure the reliability of the entire response. To address this limitation, we introduce a strict definition of grounding: a model is considered truly grounded when its responses (1) fully utilize necessary knowledge from the provided context, and (2) don't exceed the knowledge within the contexts. We introduce a new dataset and a grounding metric to assess this new definition and perform experiments across 13 LLMs of different sizes and training methods to provide insights into the factors that influence grounding performance. Our findings contribute to a better understanding of how to improve grounding capabilities and suggest an area of improvement toward more reliable and controllable LLM applications.
Continually Updating Generative Retrieval on Dynamic Corpora
May 27, 2023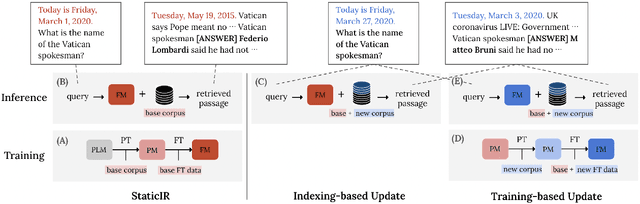



Generative retrieval has recently been gaining a lot of attention from the research community for its simplicity, high performance, and the ability to fully leverage the power of deep autoregressive models. However, prior work on generative retrieval has mostly investigated on static benchmarks, while realistic retrieval applications often involve dynamic environments where knowledge is temporal and accumulated over time. In this paper, we introduce a new benchmark called STREAMINGIR, dedicated to quantifying the generalizability of retrieval methods to dynamically changing corpora derived from StreamingQA, that simulates realistic retrieval use cases. On this benchmark, we conduct an in-depth comparative evaluation of bi-encoder and generative retrieval in terms of performance as well as efficiency under varying degree of supervision. Our results suggest that generative retrieval shows (1) detrimental performance when only supervised data is used for fine-tuning, (2) superior performance over bi-encoders when only unsupervised data is available, and (3) lower performance to bi-encoders when both unsupervised and supervised data is used due to catastrophic forgetting; nevertheless, we show that parameter-efficient measures can effectively mitigate the issue and result in competitive performance and efficiency with respect to the bi-encoder baseline. Our results open up a new potential for generative retrieval in practical dynamic environments. Our work will be open-sourced.