 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLayer-wise Swapping for Generalizable Multilingual Safety
Jan 30, 2026Despite the rapid advancements of Large Language Models (LLMs), safety risks remain a critical challenge for low-resource languages. Existing safety datasets are predominantly English centric, limiting progress in multilingual safety alignment. As a result, low resource expert models, finetuned on their respective instruction datasets, tend to exhibit higher unsafety rates compared to their high resource counterparts. In this work, we propose a safety aware layer swapping method that transfers safety alignment from an English safety expert to low resource language experts without additional training. To further enhance transfer ability, our method adaptively selects or blends modules based on their degree of specialization. Our approach preserves performance on general language understanding tasks while enhancing safety in the target languages. Experimental results show that the proposed method achieves comparable performance to the language expert on general benchmarks such as MMMLU, BELEBELE, and MGSM, while producing more aligned and less harmful responses on the MultiJail safety benchmark.
Korean Canonical Legal Benchmark: Toward Knowledge-Independent Evaluation of LLMs' Legal Reasoning Capabilities
Dec 31, 2025We introduce the Korean Canonical Legal Benchmark (KCL), a benchmark designed to assess language models' legal reasoning capabilities independently of domain-specific knowledge. KCL provides question-level supporting precedents, enabling a more faithful disentanglement of reasoning ability from parameterized knowledge. KCL consists of two components: (1) KCL-MCQA, multiple-choice problems of 283 questions with 1,103 aligned precedents, and (2) KCL-Essay, open-ended generation problems of 169 questions with 550 aligned precedents and 2,739 instance-level rubrics for automated evaluation. Our systematic evaluation of 30+ models shows large remaining gaps, particularly in KCL-Essay, and that reasoning-specialized models consistently outperform their general-purpose counterparts. We release all resources, including the benchmark dataset and evaluation code, at https://github.com/lbox-kr/kcl.
LegalSearchLM: Rethinking Legal Case Retrieval as Legal Elements Generation
May 28, 2025



Legal Case Retrieval (LCR), which retrieves relevant cases from a query case, is a fundamental task for legal professionals in research and decision-making. However, existing studies on LCR face two major limitations. First, they are evaluated on relatively small-scale retrieval corpora (e.g., 100-55K cases) and use a narrow range of criminal query types, which cannot sufficiently reflect the complexity of real-world legal retrieval scenarios. Second, their reliance on embedding-based or lexical matching methods often results in limited representations and legally irrelevant matches. To address these issues, we present: (1) LEGAR BENCH, the first large-scale Korean LCR benchmark, covering 411 diverse crime types in queries over 1.2M legal cases; and (2) LegalSearchLM, a retrieval model that performs legal element reasoning over the query case and directly generates content grounded in the target cases through constrained decoding. Experimental results show that LegalSearchLM outperforms baselines by 6-20% on LEGAR BENCH, achieving state-of-the-art performance. It also demonstrates strong generalization to out-of-domain cases, outperforming naive generative models trained on in-domain data by 15%.
Causal Retrieval with Semantic Consideration
Apr 07, 2025



Recent advancements in large language models (LLMs) have significantly enhanced the performance of conversational AI systems. To extend their capabilities to knowledge-intensive domains such as biomedical and legal fields, where the accuracy is critical, LLMs are often combined with information retrieval (IR) systems to generate responses based on retrieved documents. However, for IR systems to effectively support such applications, they must go beyond simple semantic matching and accurately capture diverse query intents, including causal relationships. Existing IR models primarily focus on retrieving documents based on surface-level semantic similarity, overlooking deeper relational structures such as causality. To address this, we propose CAWAI, a retrieval model that is trained with dual objectives: semantic and causal relations. Our extensive experiments demonstrate that CAWAI outperforms various models on diverse causal retrieval tasks especially under large-scale retrieval settings. We also show that CAWAI exhibits strong zero-shot generalization across scientific domain QA tasks.
LARGE: Legal Retrieval Augmented Generation Evaluation Tool
Apr 02, 2025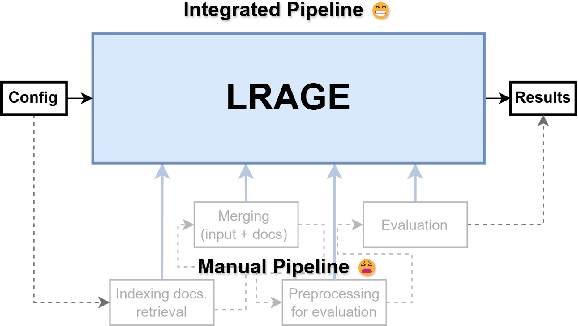



Recently, building retrieval-augmented generation (RAG) systems to enhance the capability of large language models (LLMs) has become a common practice. Especially in the legal domain, previous judicial decisions play a significant role under the doctrine of stare decisis which emphasizes the importance of making decisions based on (retrieved) prior documents. However, the overall performance of RAG system depends on many components: (1) retrieval corpora, (2) retrieval algorithms, (3) rerankers, (4) LLM backbones, and (5) evaluation metrics. Here we propose LRAGE, an open-source tool for holistic evaluation of RAG systems focusing on the legal domain. LRAGE provides GUI and CLI interfaces to facilitate seamless experiments and investigate how changes in the aforementioned five components affect the overall accuracy. We validated LRAGE using multilingual legal benches including Korean (KBL), English (LegalBench), and Chinese (LawBench) by demonstrating how the overall accuracy changes when varying the five components mentioned above. The source code is available at https://github.com/hoorangyee/LRAGE.
Taxation Perspectives from Large Language Models: A Case Study on Additional Tax Penalties
Mar 05, 2025


How capable are large language models (LLMs) in the domain of taxation? Although numerous studies have explored the legal domain in general, research dedicated to taxation remain scarce. Moreover, the datasets used in these studies are either simplified, failing to reflect the real-world complexities, or unavailable as open source. To address this gap, we introduce PLAT, a new benchmark designed to assess the ability of LLMs to predict the legitimacy of additional tax penalties. PLAT is constructed to evaluate LLMs' understanding of tax law, particularly in cases where resolving the issue requires more than just applying related statutes. Our experiments with six LLMs reveal that their baseline capabilities are limited, especially when dealing with conflicting issues that demand a comprehensive understanding. However, we found that enabling retrieval, self-reasoning, and discussion among multiple agents with specific role assignments, this limitation can be mitigated.
Vision-Encoders (Already) Know What They See: Mitigating Object Hallucination via Simple Fine-Grained CLIPScore
Feb 27, 2025



Recently, Large Vision-Language Models (LVLMs) show remarkable performance across various domains. However, these models suffer from object hallucination. This study revisits the previous claim that the primary cause of such hallucination lies in the limited representational capacity of the vision encoder. Our analysis reveals that the capacity of the vision encoder itself is already enough for detecting object hallucination. Based on this insight, we propose a Fine-grained CLIPScore (F-CLIPScore), a simple yet effective evaluation metric that enhances object-level granularity by incorporating text embeddings at the noun phrase level. Evaluations on the OHD-Caps benchmark show that F-CLIPScore significantly outperforms conventional CLIPScore in accuracy by a large margin of 39.6% without additional training. We further validate F-CLIPScore by showing that LVLM trained with the data filtered using F-CLIPScore exhibits reduced hallucination.
Developing a Pragmatic Benchmark for Assessing Korean Legal Language Understanding in Large Language Models
Oct 11, 2024
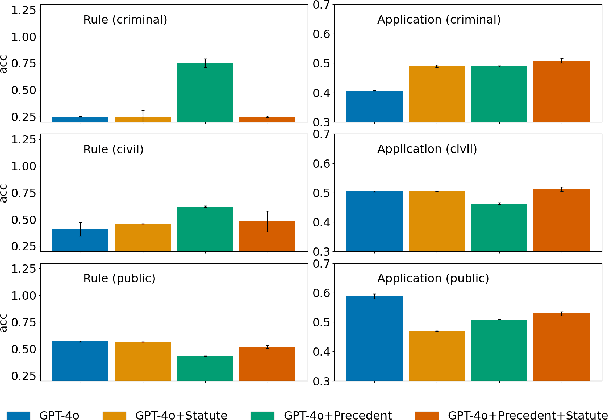
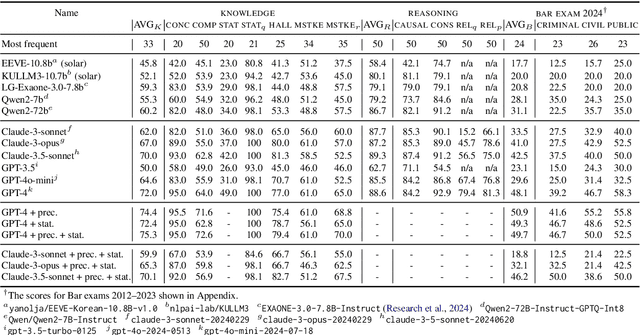
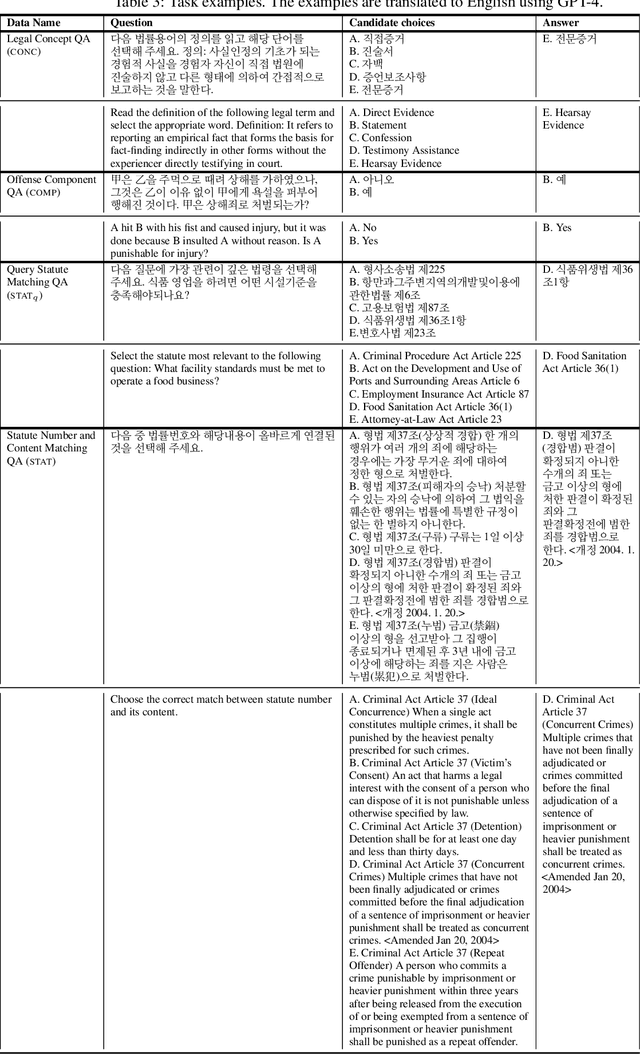
Large language models (LLMs) have demonstrated remarkable performance in the legal domain, with GPT-4 even passing the Uniform Bar Exam in the U.S. However their efficacy remains limited for non-standardized tasks and tasks in languages other than English. This underscores the need for careful evaluation of LLMs within each legal system before application. Here, we introduce KBL, a benchmark for assessing the Korean legal language understanding of LLMs, consisting of (1) 7 legal knowledge tasks (510 examples), (2) 4 legal reasoning tasks (288 examples), and (3) the Korean bar exam (4 domains, 53 tasks, 2,510 examples). First two datasets were developed in close collaboration with lawyers to evaluate LLMs in practical scenarios in a certified manner. Furthermore, considering legal practitioners' frequent use of extensive legal documents for research, we assess LLMs in both a closed book setting, where they rely solely on internal knowledge, and a retrieval-augmented generation (RAG) setting, using a corpus of Korean statutes and precedents. The results indicate substantial room and opportunities for improvement.
Does Alignment Tuning Really Break LLMs' Internal Confidence?
Aug 31, 2024

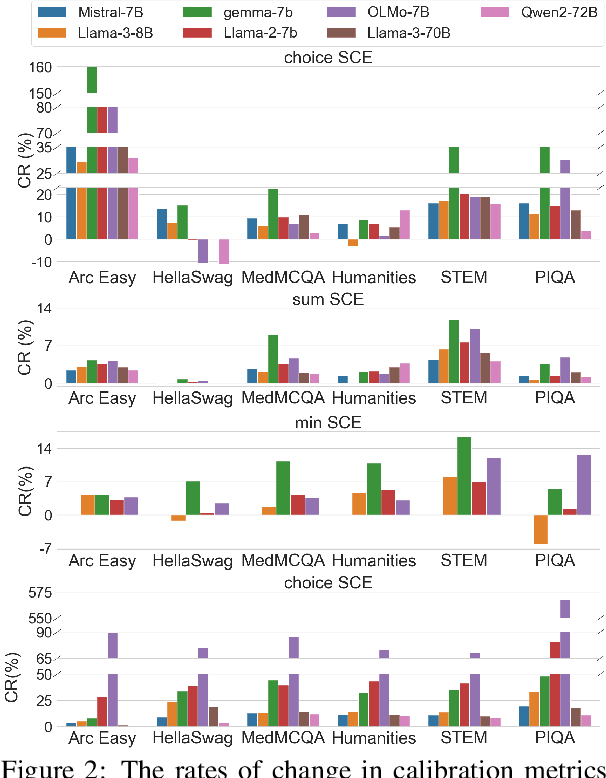
Large Language Models (LLMs) have shown remarkable progress, but their real-world application necessitates reliable calibration. This study conducts a comprehensive analysis of calibration degradation of LLMs across four dimensions: models, calibration metrics, tasks, and confidence extraction methods. Initial analysis showed that the relationship between alignment and calibration is not always a trade-off, but under stricter analysis conditions, we found the alignment process consistently harms calibration. This highlights the need for (1) a careful approach when measuring model confidences and calibration errors and (2) future research into algorithms that can help LLMs to achieve both instruction-following and calibration without sacrificing either.
On the Consideration of AI Openness: Can Good Intent Be Abused?
Mar 11, 2024



Openness is critical for the advancement of science. In particular, recent rapid progress in AI has been made possible only by various open-source models, datasets, and libraries. However, this openness also means that technologies can be freely used for socially harmful purposes. Can open-source models or datasets be used for malicious purposes? If so, how easy is it to adapt technology for such goals? Here, we conduct a case study in the legal domain, a realm where individual decisions can have profound social consequences. To this end, we build EVE, a dataset consisting of 200 examples of questions and corresponding answers about criminal activities based on 200 Korean precedents. We found that a widely accepted open-source LLM, which initially refuses to answer unethical questions, can be easily tuned with EVE to provide unethical and informative answers about criminal activities. This implies that although open-source technologies contribute to scientific progress, some care must be taken to mitigate possible malicious use cases. Warning: This paper contains contents that some may find unethical.