 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeveloping a Pragmatic Benchmark for Assessing Korean Legal Language Understanding in Large Language Models
Oct 11, 2024
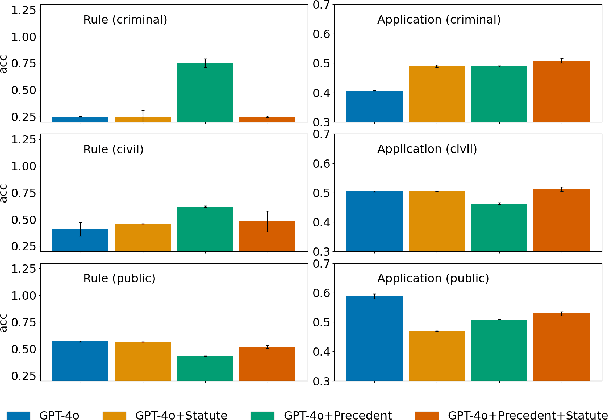
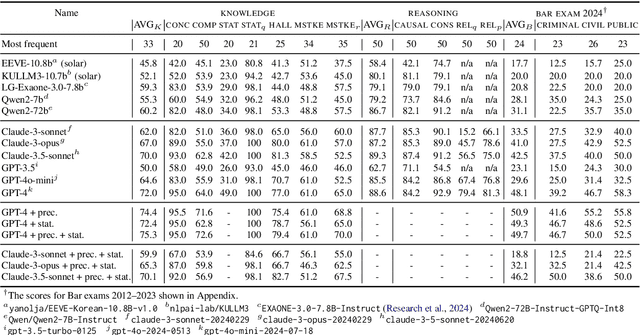
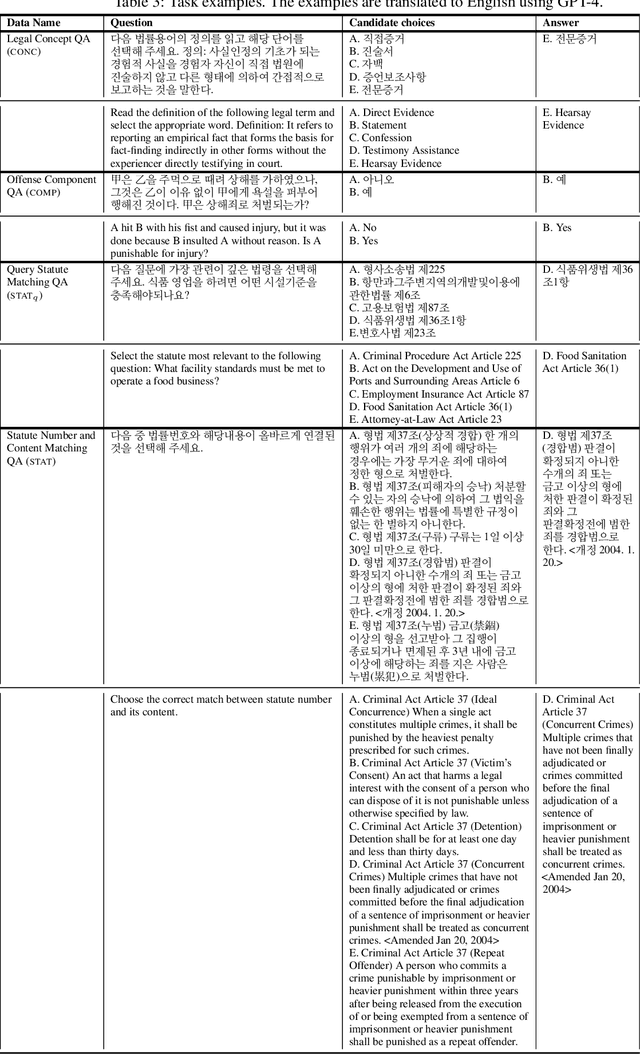
Large language models (LLMs) have demonstrated remarkable performance in the legal domain, with GPT-4 even passing the Uniform Bar Exam in the U.S. However their efficacy remains limited for non-standardized tasks and tasks in languages other than English. This underscores the need for careful evaluation of LLMs within each legal system before application. Here, we introduce KBL, a benchmark for assessing the Korean legal language understanding of LLMs, consisting of (1) 7 legal knowledge tasks (510 examples), (2) 4 legal reasoning tasks (288 examples), and (3) the Korean bar exam (4 domains, 53 tasks, 2,510 examples). First two datasets were developed in close collaboration with lawyers to evaluate LLMs in practical scenarios in a certified manner. Furthermore, considering legal practitioners' frequent use of extensive legal documents for research, we assess LLMs in both a closed book setting, where they rely solely on internal knowledge, and a retrieval-augmented generation (RAG) setting, using a corpus of Korean statutes and precedents. The results indicate substantial room and opportunities for improvement.
Winning Ticket in Noisy Image Classification
Feb 23, 2021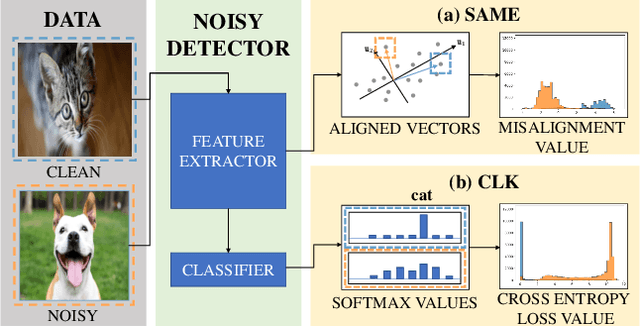

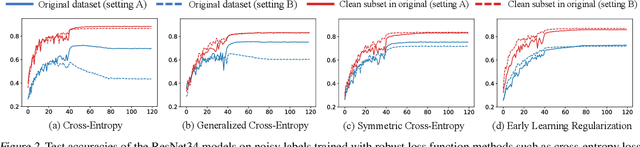
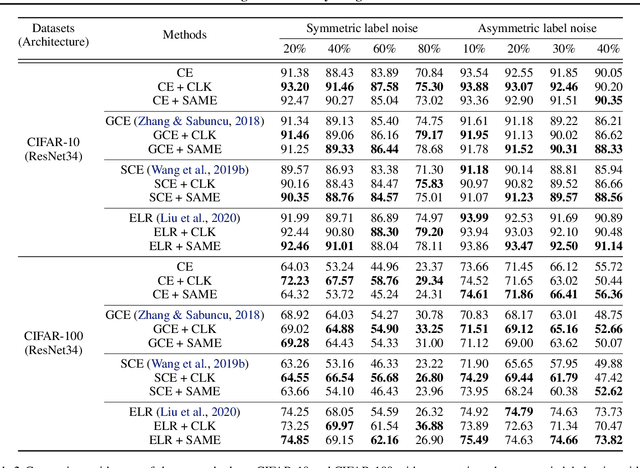
Modern deep neural networks (DNNs) become frail when the datasets contain noisy (incorrect) class labels. Many robust techniques have emerged via loss adjustment, robust loss function, and clean sample selection to mitigate this issue using the whole dataset. Here, we empirically observe that the dataset which contains only clean instances in original noisy datasets leads to better optima than the original dataset even with fewer data. Based on these results, we state the winning ticket hypothesis: regardless of robust methods, any DNNs reach the best performance when trained on the dataset possessing only clean samples from the original (winning ticket). We propose two simple yet effective strategies to identify winning tickets by looking at the loss landscape and latent features in DNNs. We conduct numerical experiments by collaborating the two proposed methods purifying data and existing robust methods for CIFAR-10 and CIFAR-100. The results support that our framework consistently and remarkably improves performance.