 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM Agents for Bargaining with Utility-based Feedback
May 29, 2025Bargaining, a critical aspect of real-world interactions, presents challenges for large language models (LLMs) due to limitations in strategic depth and adaptation to complex human factors. Existing benchmarks often fail to capture this real-world complexity. To address this and enhance LLM capabilities in realistic bargaining, we introduce a comprehensive framework centered on utility-based feedback. Our contributions are threefold: (1) BargainArena, a novel benchmark dataset with six intricate scenarios (e.g., deceptive practices, monopolies) to facilitate diverse strategy modeling; (2) human-aligned, economically-grounded evaluation metrics inspired by utility theory, incorporating agent utility and negotiation power, which implicitly reflect and promote opponent-aware reasoning (OAR); and (3) a structured feedback mechanism enabling LLMs to iteratively refine their bargaining strategies. This mechanism can positively collaborate with in-context learning (ICL) prompts, including those explicitly designed to foster OAR. Experimental results show that LLMs often exhibit negotiation strategies misaligned with human preferences, and that our structured feedback mechanism significantly improves their performance, yielding deeper strategic and opponent-aware reasoning.
AdaSTaR: Adaptive Data Sampling for Training Self-Taught Reasoners
May 22, 2025Self-Taught Reasoners (STaR), synonymously known as Rejection sampling Fine-Tuning (RFT), is an integral part of the training pipeline of self-improving reasoning Language Models (LMs). The self-improving mechanism often employs random observation (data) sampling. However, this results in trained observation imbalance; inefficiently over-training on solved examples while under-training on challenging ones. In response, we introduce Adaptive STaR (AdaSTaR), a novel algorithm that rectifies this by integrating two adaptive sampling principles: (1) Adaptive Sampling for Diversity: promoting balanced training across observations, and (2) Adaptive Sampling for Curriculum: dynamically adjusting data difficulty to match the model's evolving strength. Across six benchmarks, AdaSTaR achieves best test accuracy in all instances (6/6) and reduces training FLOPs by an average of 58.6% against an extensive list of baselines. These improvements in performance and efficiency generalize to different pre-trained LMs and larger models, paving the way for more efficient and effective self-improving LMs.
Guiding Reasoning in Small Language Models with LLM Assistance
Apr 14, 2025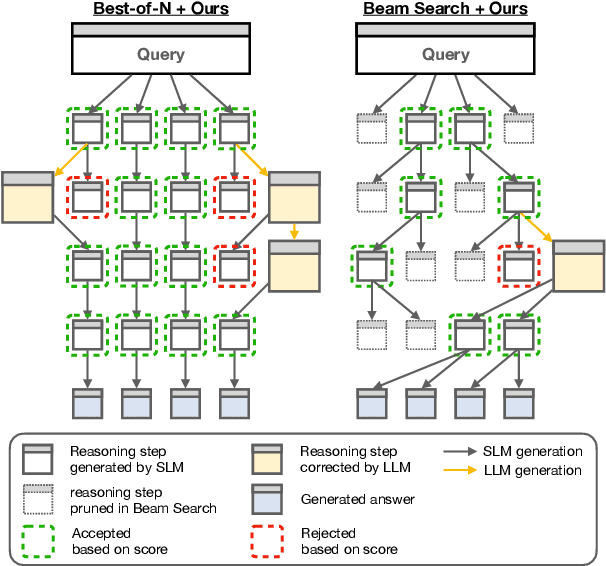
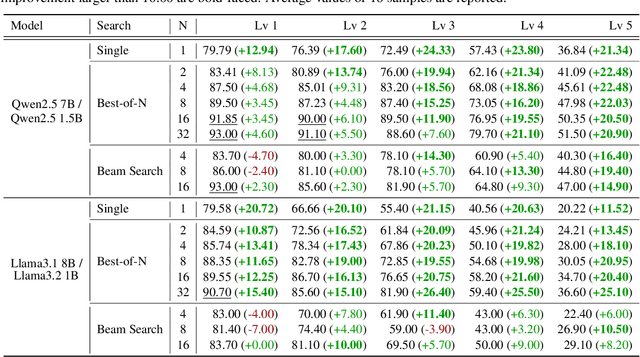
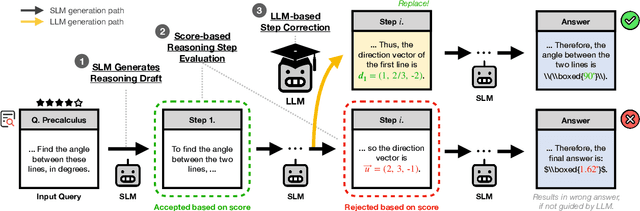

The limited reasoning capabilities of small language models (SLMs) cast doubt on their suitability for tasks demanding deep, multi-step logical deduction. This paper introduces a framework called Small Reasons, Large Hints (SMART), which selectively augments SLM reasoning with targeted guidance from large language models (LLMs). Inspired by the concept of cognitive scaffolding, SMART employs a score-based evaluation to identify uncertain reasoning steps and injects corrective LLM-generated reasoning only when necessary. By framing structured reasoning as an optimal policy search, our approach steers the reasoning trajectory toward correct solutions without exhaustive sampling. Our experiments on mathematical reasoning datasets demonstrate that targeted external scaffolding significantly improves performance, paving the way for collaborative use of both SLM and LLM to tackle complex reasoning tasks that are currently unsolvable by SLMs alone.
MMR: A Large-scale Benchmark Dataset for Multi-target and Multi-granularity Reasoning Segmentation
Mar 18, 2025The fusion of Large Language Models with vision models is pioneering new possibilities in user-interactive vision-language tasks. A notable application is reasoning segmentation, where models generate pixel-level segmentation masks by comprehending implicit meanings in human instructions. However, seamless human-AI interaction demands more than just object-level recognition; it requires understanding both objects and the functions of their detailed parts, particularly in multi-target scenarios. For example, when instructing a robot to \textit{turn on the TV"}, there could be various ways to accomplish this command. Recognizing multiple objects capable of turning on the TV, such as the TV itself or a remote control (multi-target), provides more flexible options and aids in finding the optimized scenario. Furthermore, understanding specific parts of these objects, like the TV's button or the remote's button (part-level), is important for completing the action. Unfortunately, current reasoning segmentation datasets predominantly focus on a single target object-level reasoning, which limits the detailed recognition of an object's parts in multi-target contexts. To address this gap, we construct a large-scale dataset called Multi-target and Multi-granularity Reasoning (MMR). MMR comprises 194K complex and implicit instructions that consider multi-target, object-level, and part-level aspects, based on pre-existing image-mask sets. This dataset supports diverse and context-aware interactions by hierarchically providing object and part information. Moreover, we propose a straightforward yet effective framework for multi-target, object-level, and part-level reasoning segmentation. Experimental results on MMR show that the proposed method can reason effectively in multi-target and multi-granularity scenarios, while the existing reasoning segmentation model still has room for improvement.
$C^2$: Scalable Auto-Feedback for LLM-based Chart Generation
Oct 24, 2024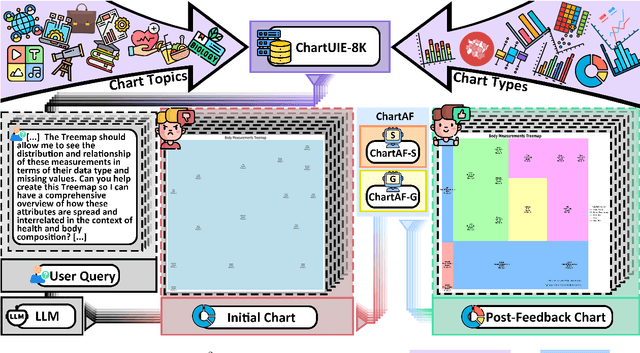

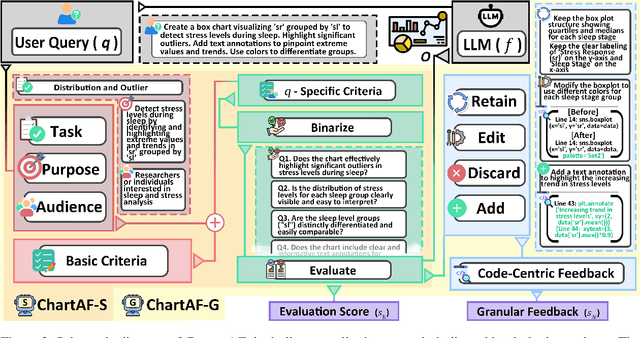

Generating high-quality charts with Large Language Models presents significant challenges due to limited data and the high cost of scaling through human curation. Instruction, data, and code triplets are scarce and expensive to manually curate as their creation demands technical expertise. To address this scalability issue, we introduce a reference-free automatic feedback generator, which eliminates the need for costly human intervention. Our novel framework, $C^2$, consists of (1) an automatic feedback provider (ChartAF) and (2) a diverse, reference-free dataset (ChartUIE-8K). Quantitative results are compelling: in our first experiment, 74% of respondents strongly preferred, and 10% preferred, the results after feedback. The second post-feedback experiment demonstrates that ChartAF outperforms nine baselines. Moreover, ChartUIE-8K significantly improves data diversity by increasing queries, datasets, and chart types by 5982%, 1936%, and 91%, respectively, over benchmarks. Finally, an LLM user study revealed that 94% of participants preferred ChartUIE-8K's queries, with 93% deeming them aligned with real-world use cases. Core contributions are available as open-source at an anonymized project site, with ample qualitative examples.
REBEL: Rule-based and Experience-enhanced Learning with LLMs for Initial Task Allocation in Multi-Human Multi-Robot Teams
Sep 24, 2024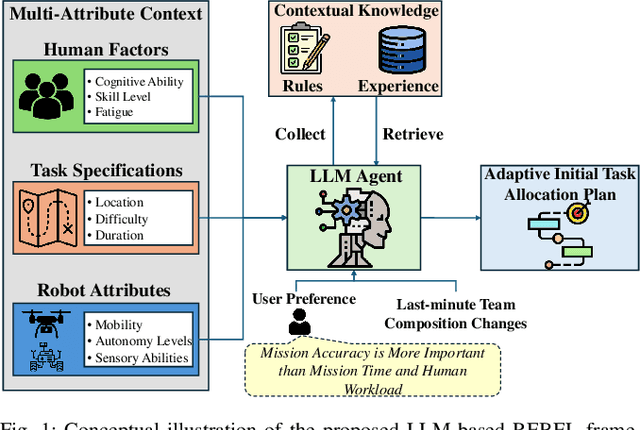
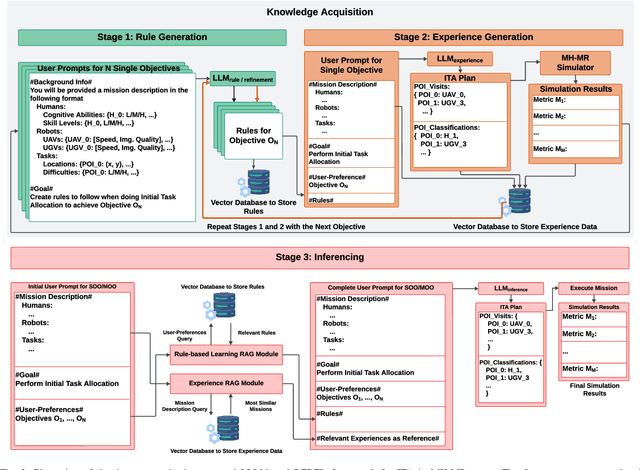
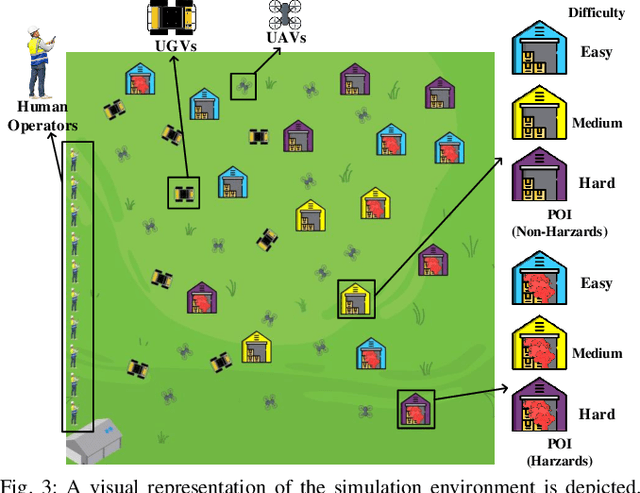
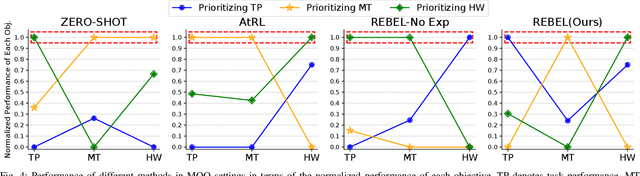
Multi-human multi-robot teams combine the complementary strengths of humans and robots to tackle complex tasks across diverse applications. However, the inherent heterogeneity of these teams presents significant challenges in initial task allocation (ITA), which involves assigning the most suitable tasks to each team member based on their individual capabilities before task execution. While current learning-based methods have shown promising results, they are often computationally expensive to train, and lack the flexibility to incorporate user preferences in multi-objective optimization and adapt to last-minute changes in real-world dynamic environments. To address these issues, we propose REBEL, an LLM-based ITA framework that integrates rule-based and experience-enhanced learning. By leveraging Retrieval-Augmented Generation, REBEL dynamically retrieves relevant rules and past experiences, enhancing reasoning efficiency. Additionally, REBEL can complement pre-trained RL-based ITA policies, improving situational awareness and overall team performance. Extensive experiments validate the effectiveness of our approach across various settings. More details are available at https://sites.google.com/view/ita-rebel .
Adaptive Task Allocation in Multi-Human Multi-Robot Teams under Team Heterogeneity and Dynamic Information Uncertainty
Sep 20, 2024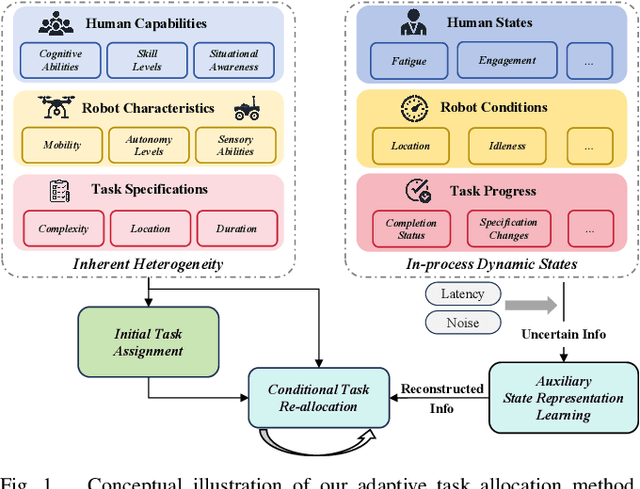
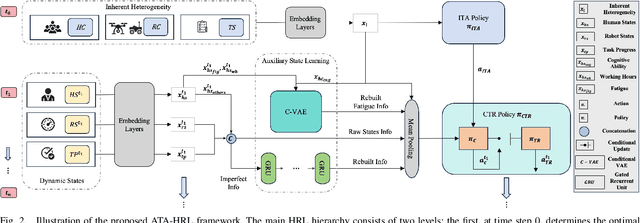

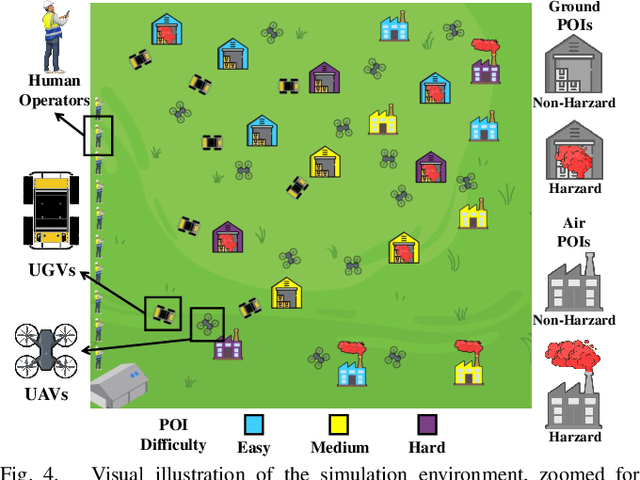
Task allocation in multi-human multi-robot (MH-MR) teams presents significant challenges due to the inherent heterogeneity of team members, the dynamics of task execution, and the information uncertainty of operational states. Existing approaches often fail to address these challenges simultaneously, resulting in suboptimal performance. To tackle this, we propose ATA-HRL, an adaptive task allocation framework using hierarchical reinforcement learning (HRL), which incorporates initial task allocation (ITA) that leverages team heterogeneity and conditional task reallocation in response to dynamic operational states. Additionally, we introduce an auxiliary state representation learning task to manage information uncertainty and enhance task execution. Through an extensive case study in large-scale environmental monitoring tasks, we demonstrate the benefits of our approach.
PrefMMT: Modeling Human Preferences in Preference-based Reinforcement Learning with Multimodal Transformers
Sep 20, 2024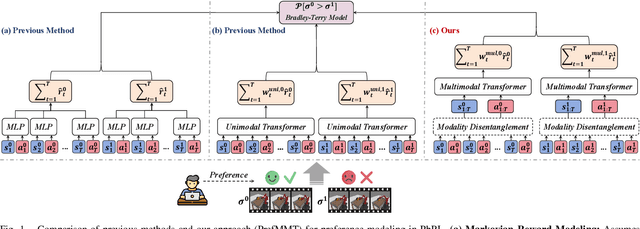
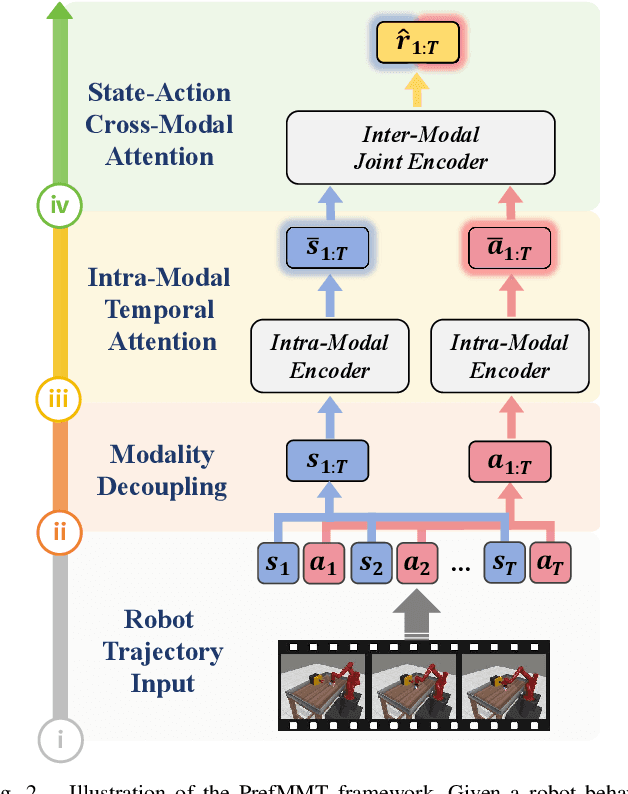
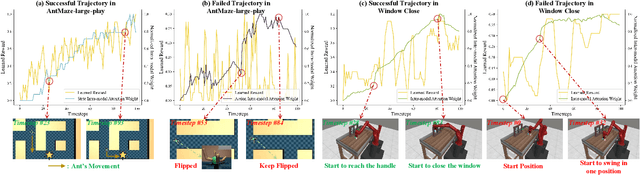
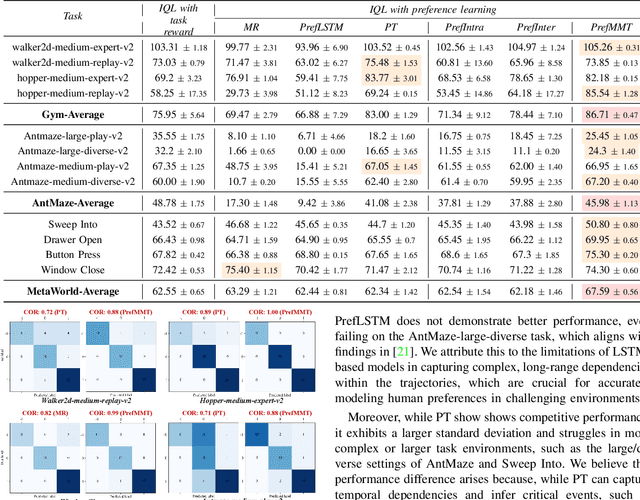
Preference-based reinforcement learning (PbRL) shows promise in aligning robot behaviors with human preferences, but its success depends heavily on the accurate modeling of human preferences through reward models. Most methods adopt Markovian assumptions for preference modeling (PM), which overlook the temporal dependencies within robot behavior trajectories that impact human evaluations. While recent works have utilized sequence modeling to mitigate this by learning sequential non-Markovian rewards, they ignore the multimodal nature of robot trajectories, which consist of elements from two distinctive modalities: state and action. As a result, they often struggle to capture the complex interplay between these modalities that significantly shapes human preferences. In this paper, we propose a multimodal sequence modeling approach for PM by disentangling state and action modalities. We introduce a multimodal transformer network, named PrefMMT, which hierarchically leverages intra-modal temporal dependencies and inter-modal state-action interactions to capture complex preference patterns. We demonstrate that PrefMMT consistently outperforms state-of-the-art PM baselines on locomotion tasks from the D4RL benchmark and manipulation tasks from the Meta-World benchmark.
Towards Fast Multilingual LLM Inference: Speculative Decoding and Specialized Drafters
Jun 24, 2024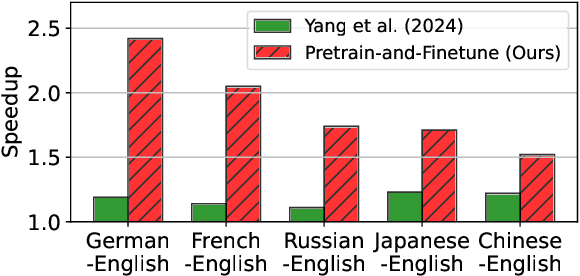



Large language models (LLMs) have revolutionized natural language processing and broadened their applicability across diverse commercial applications. However, the deployment of these models is constrained by high inference time in multilingual settings. To mitigate this challenge, this paper explores a training recipe of an assistant model in speculative decoding, which are leveraged to draft and-then its future tokens are verified by the target LLM. We show that language-specific draft models, optimized through a targeted pretrain-and-finetune strategy, substantially brings a speedup of inference time compared to the previous methods. We validate these models across various languages in inference time, out-of-domain speedup, and GPT-4o evaluation.
Block Transformer: Global-to-Local Language Modeling for Fast Inference
Jun 04, 2024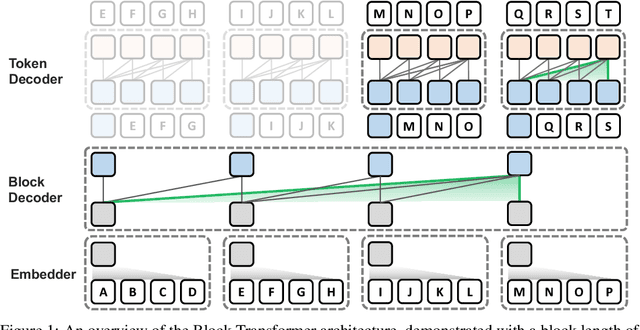
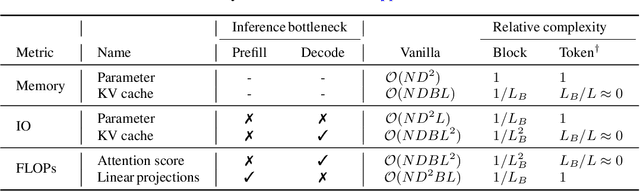
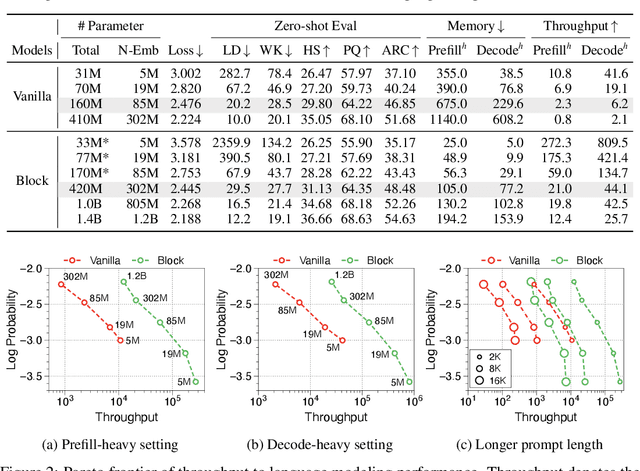
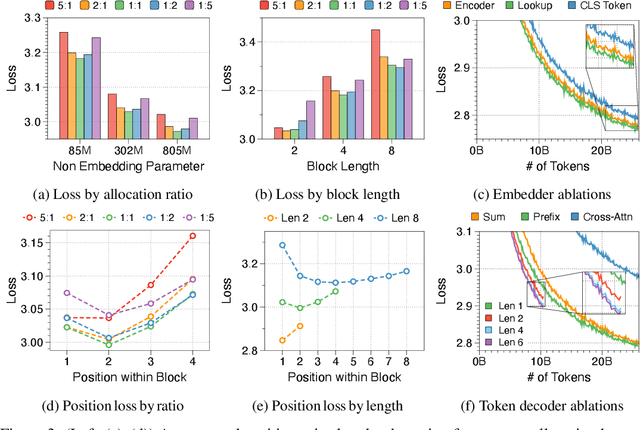
This paper presents the Block Transformer architecture which adopts hierarchical global-to-local modeling to autoregressive transformers to mitigate the inference bottlenecks of self-attention. To apply self-attention, the key-value (KV) cache of all previous sequences must be retrieved from memory at every decoding step. Thereby, this KV cache IO becomes a significant bottleneck in batch inference. We notice that these costs stem from applying self-attention on the global context, therefore we isolate the expensive bottlenecks of global modeling to lower layers and apply fast local modeling in upper layers. To mitigate the remaining costs in the lower layers, we aggregate input tokens into fixed size blocks and then apply self-attention at this coarse level. Context information is aggregated into a single embedding to enable upper layers to decode the next block of tokens, without global attention. Free of global attention bottlenecks, the upper layers can fully utilize the compute hardware to maximize inference throughput. By leveraging global and local modules, the Block Transformer architecture demonstrates 10-20x gains in inference throughput compared to vanilla transformers with equivalent perplexity. Our work introduces a new approach to optimize language model inference through novel application of global-to-local modeling. Code is available at https://github.com/itsnamgyu/block-transformer.