 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMassive Sound Embedding Benchmark (MSEB)
Feb 06, 2026Audio is a critical component of multimodal perception, and any truly intelligent system must demonstrate a wide range of auditory capabilities. These capabilities include transcription, classification, retrieval, reasoning, segmentation, clustering, reranking, and reconstruction. Fundamentally, each task involves transforming a raw audio signal into a meaningful 'embedding' - be it a single vector, a sequence of continuous or discrete representations, or another structured form - which then serves as the basis for generating the task's final response. To accelerate progress towards robust machine auditory intelligence, we present the Massive Sound Embedding Benchmark (MSEB): an extensible framework designed to evaluate the auditory components of any multimodal system. In its first release, MSEB offers a comprehensive suite of eight core tasks, with more planned for the future, supported by diverse datasets, including the new, large-scale Simple Voice Questions (SVQ) dataset. Our initial experiments establish clear performance headrooms, highlighting the significant opportunity to improve real-world multimodal experiences where audio is a core signal. We encourage the research community to use MSEB to assess their algorithms and contribute to its growth. The library is publicly hosted at github.
Towards Fast Inference: Exploring and Improving Blockwise Parallel Drafts
Apr 14, 2024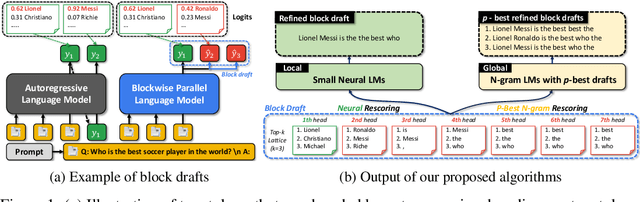

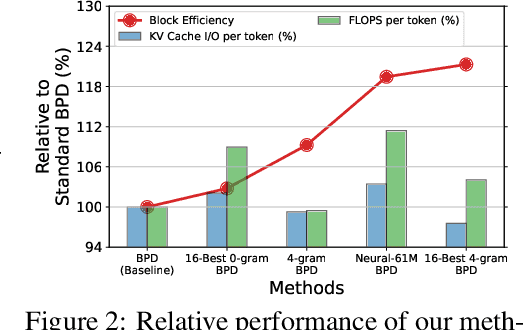
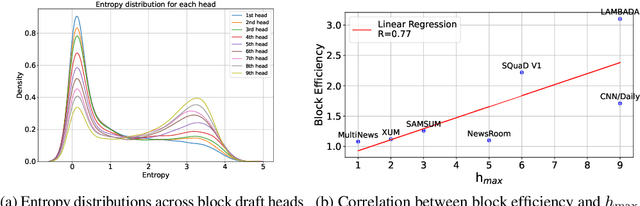
Despite the remarkable strides made by autoregressive language models, their potential is often hampered by the slow inference speeds inherent in sequential token generation. Blockwise parallel decoding (BPD) was proposed by Stern et al. (2018) as a way to improve inference speed of language models. In this paper, we make two contributions to understanding and improving BPD drafts. We first offer an analysis of the token distributions produced by the BPD prediction heads. Secondly, we use this analysis to inform algorithms to improve BPD inference speed by refining the BPD drafts using small n-gram or neural language models. We empirically show that these refined BPD drafts yield a higher average verified prefix length across tasks.
Self-supervised Adaptive Weighting for Cooperative Perception in V2V Communications
Dec 16, 2023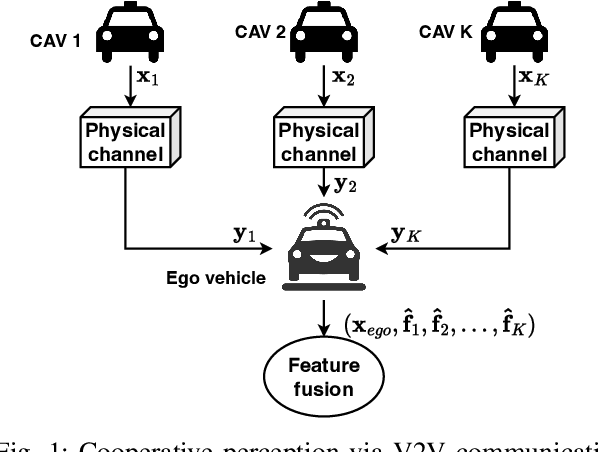
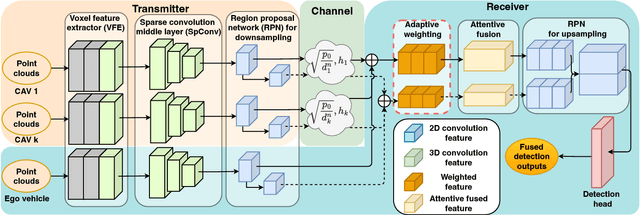
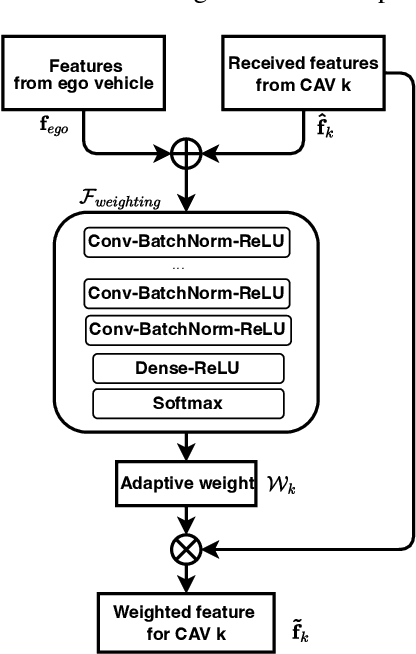
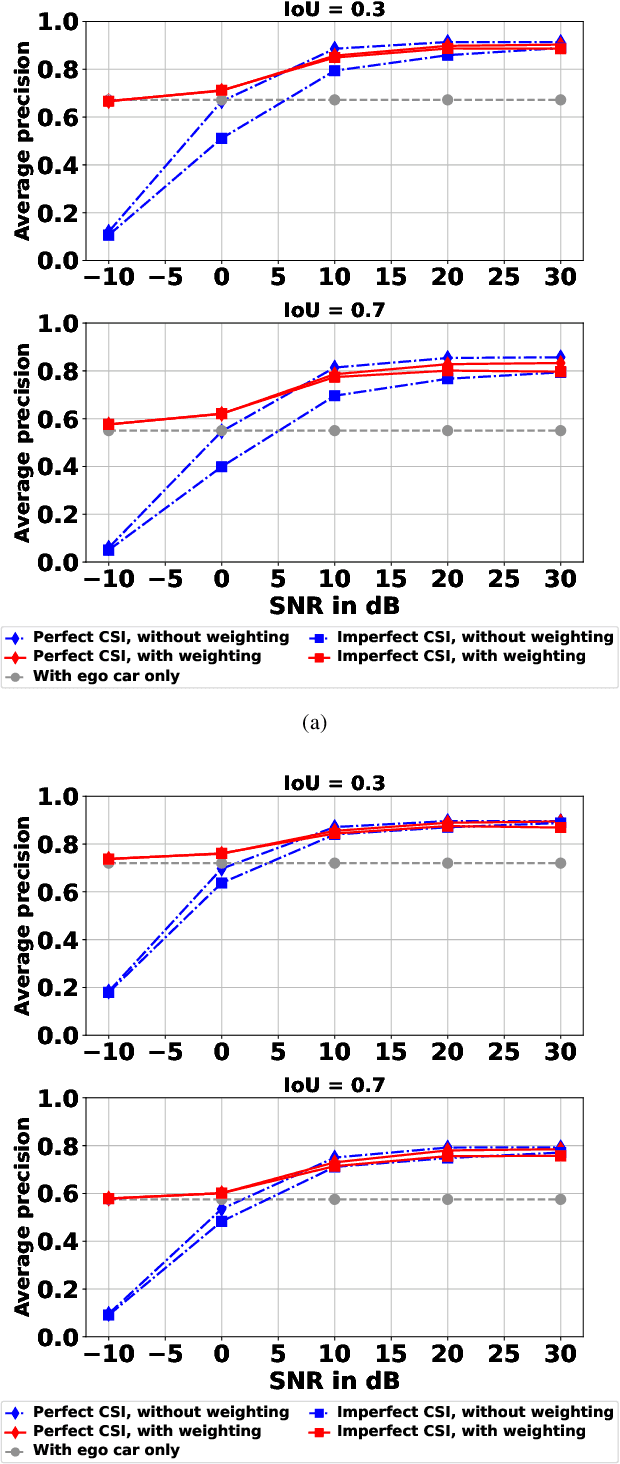
Perception of the driving environment is critical for collision avoidance and route planning to ensure driving safety. Cooperative perception has been widely studied as an effective approach to addressing the shortcomings of single-vehicle perception. However, the practical limitations of vehicle-to-vehicle (V2V) communications have not been adequately investigated. In particular, current cooperative fusion models rely on supervised models and do not address dynamic performance degradation caused by arbitrary channel impairments. In this paper, a self-supervised adaptive weighting model is proposed for intermediate fusion to mitigate the adverse effects of channel distortion. The performance of cooperative perception is investigated in different system settings. Rician fading and imperfect channel state information (CSI) are also considered. Numerical results demonstrate that the proposed adaptive weighting algorithm significantly outperforms the benchmarks without weighting. Visualization examples validate that the proposed weighting algorithm can flexibly adapt to various channel conditions. Moreover, the adaptive weighting algorithm demonstrates good generalization to untrained channels and test datasets from different domains.
Cooperative Perception with Learning-Based V2V communications
Nov 17, 2023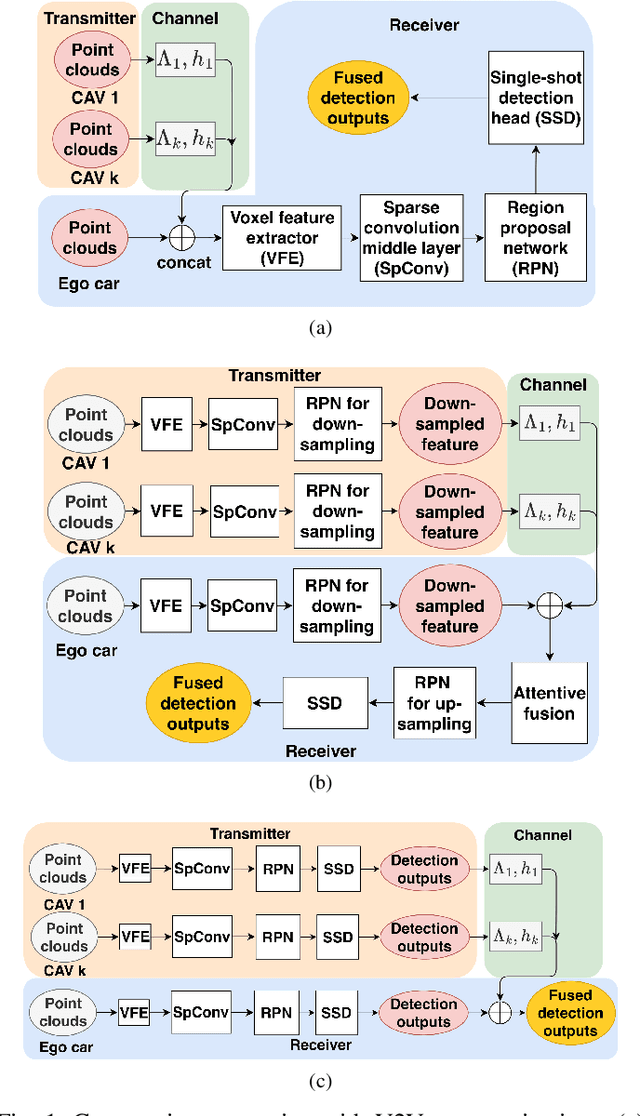
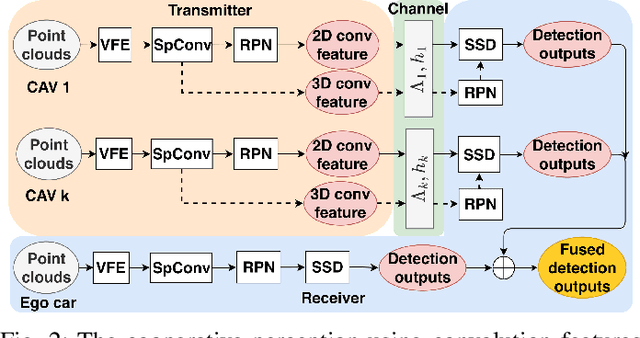
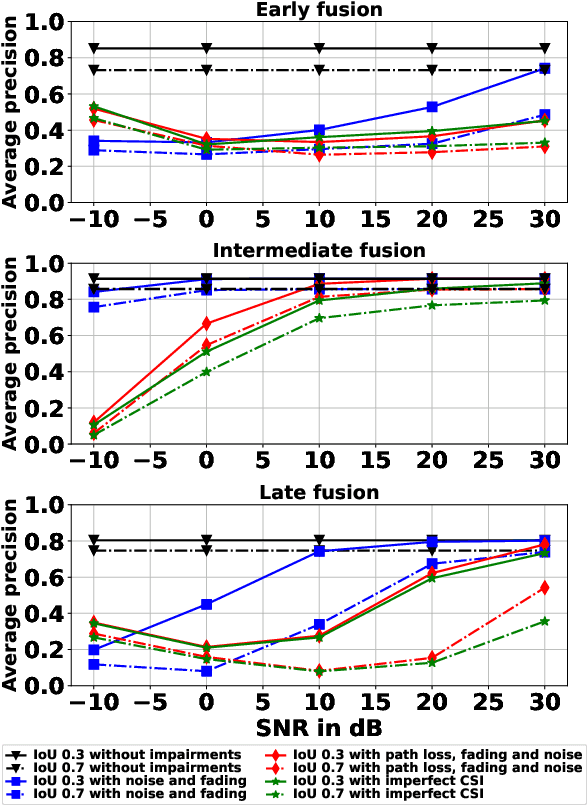
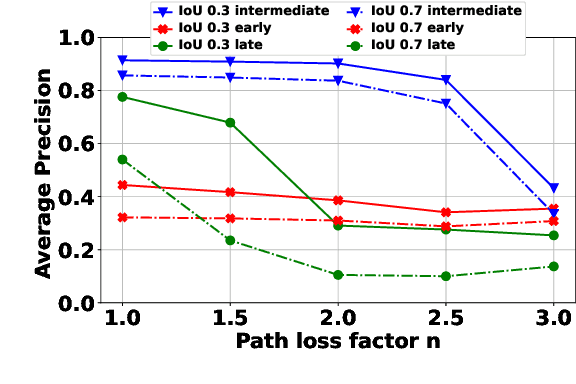
Cooperative perception has been widely used in autonomous driving to alleviate the inherent limitation of single automated vehicle perception. To enable cooperation, vehicle-to-vehicle (V2V) communication plays an indispensable role. This work analyzes the performance of cooperative perception accounting for communications channel impairments. Different fusion methods and channel impairments are evaluated. A new late fusion scheme is proposed to leverage the robustness of intermediate features. In order to compress the data size incurred by cooperation, a convolution neural network-based autoencoder is adopted. Numerical results demonstrate that intermediate fusion is more robust to channel impairments than early fusion and late fusion, when the SNR is greater than 0 dB. Also, the proposed fusion scheme outperforms the conventional late fusion using detection outputs, and autoencoder provides a good compromise between detection accuracy and bandwidth usage.
Large-scale Language Model Rescoring on Long-form Data
Jun 13, 2023
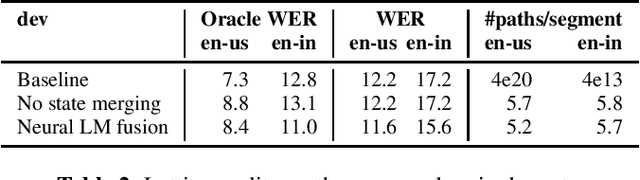


In this work, we study the impact of Large-scale Language Models (LLM) on Automated Speech Recognition (ASR) of YouTube videos, which we use as a source for long-form ASR. We demonstrate up to 8\% relative reduction in Word Error Eate (WER) on US English (en-us) and code-switched Indian English (en-in) long-form ASR test sets and a reduction of up to 30\% relative on Salient Term Error Rate (STER) over a strong first-pass baseline that uses a maximum-entropy based language model. Improved lattice processing that results in a lattice with a proper (non-tree) digraph topology and carrying context from the 1-best hypothesis of the previous segment(s) results in significant wins in rescoring with LLMs. We also find that the gains in performance from the combination of LLMs trained on vast quantities of available data (such as C4) and conventional neural LMs is additive and significantly outperforms a strong first-pass baseline with a maximum entropy LM.
* 5 pages, accepted in ICASSP 2023
LAST: Scalable Lattice-Based Speech Modelling in JAX
Apr 25, 2023We introduce LAST, a LAttice-based Speech Transducer library in JAX. With an emphasis on flexibility, ease-of-use, and scalability, LAST implements differentiable weighted finite state automaton (WFSA) algorithms needed for training \& inference that scale to a large WFSA such as a recognition lattice over the entire utterance. Despite these WFSA algorithms being well-known in the literature, new challenges arise from performance characteristics of modern architectures, and from nuances in automatic differentiation. We describe a suite of generally applicable techniques employed in LAST to address these challenges, and demonstrate their effectiveness with benchmarks on TPUv3 and V100 GPU.
Alignment Entropy Regularization
Dec 22, 2022



Existing training criteria in automatic speech recognition(ASR) permit the model to freely explore more than one time alignments between the feature and label sequences. In this paper, we use entropy to measure a model's uncertainty, i.e. how it chooses to distribute the probability mass over the set of allowed alignments. Furthermore, we evaluate the effect of entropy regularization in encouraging the model to distribute the probability mass only on a smaller subset of allowed alignments. Experiments show that entropy regularization enables a much simpler decoding method without sacrificing word error rate, and provides better time alignment quality.
Global Normalization for Streaming Speech Recognition in a Modular Framework
May 26, 2022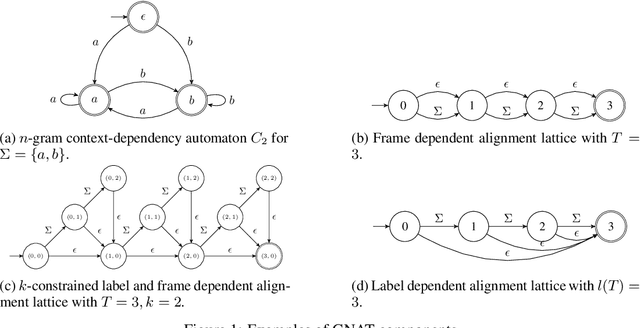
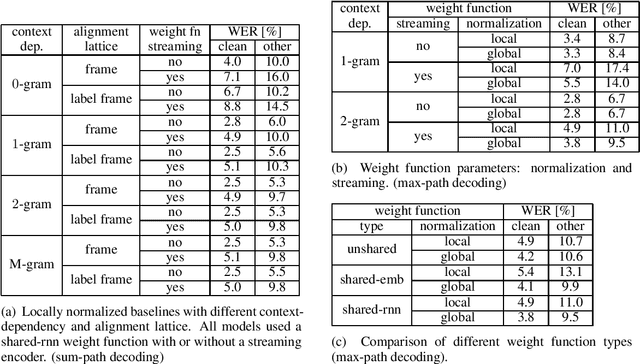
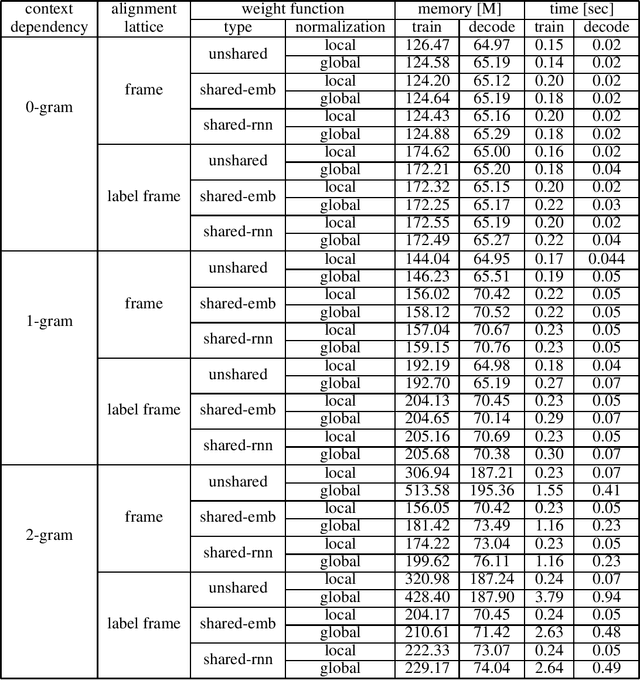
We introduce the Globally Normalized Autoregressive Transducer (GNAT) for addressing the label bias problem in streaming speech recognition. Our solution admits a tractable exact computation of the denominator for the sequence-level normalization. Through theoretical and empirical results, we demonstrate that by switching to a globally normalized model, the word error rate gap between streaming and non-streaming speech-recognition models can be greatly reduced (by more than 50\% on the Librispeech dataset). This model is developed in a modular framework which encompasses all the common neural speech recognition models. The modularity of this framework enables controlled comparison of modelling choices and creation of new models.
Learning discrete distributions: user vs item-level privacy
Jul 28, 2020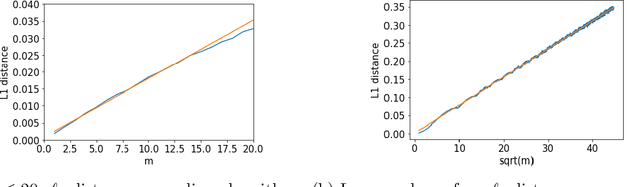
Much of the literature on differential privacy focuses on item-level privacy, where loosely speaking, the goal is to provide privacy per item or training example. However, recently many practical applications such as federated learning require preserving privacy for all items of a single user, which is much harder to achieve. Therefore understanding the theoretical limit of user-level privacy becomes crucial. We study the fundamental problem of learning discrete distributions over $k$ symbols with user-level differential privacy. If each user has $m$ samples, we show that straightforward applications of Laplace or Gaussian mechanisms require the number of users to be $\mathcal{O}(k/(m\alpha^2) + k/\epsilon\alpha)$ to achieve an $\ell_1$ distance of $\alpha$ between the true and estimated distributions, with the privacy-induced penalty $k/\epsilon\alpha$ independent of the number of samples per user $m$. Moreover, we show that any mechanism that only operates on the final aggregate should require a user complexity of the same order. We then propose a mechanism such that the number of users scales as $\tilde{\mathcal{O}}(k/(m\alpha^2) + k/\sqrt{m}\epsilon\alpha)$ and further show that it is nearly-optimal under certain regimes. Thus the privacy penalty is $\mathcal{O}(\sqrt{m})$ times smaller compared to the standard mechanisms. We also propose general techniques for obtaining lower bounds on restricted differentially private estimators and a lower bound on the total variation between binomial distributions, both of which might be of independent interest.
Hybrid Autoregressive Transducer (hat)
Mar 12, 2020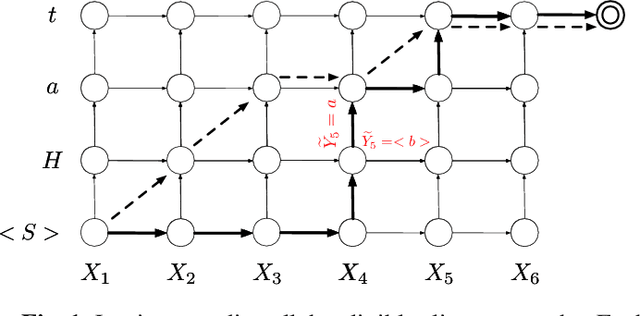

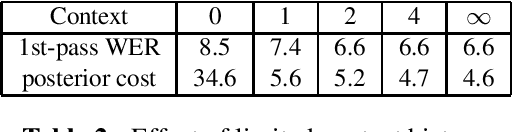
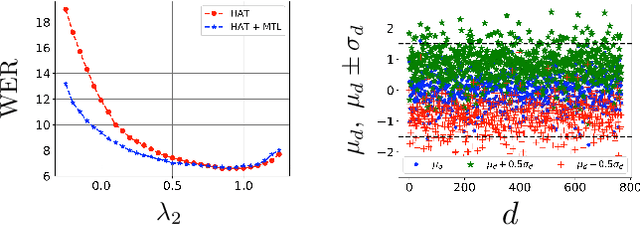
This paper proposes and evaluates the hybrid autoregressive transducer (HAT) model, a time-synchronous encoderdecoder model that preserves the modularity of conventional automatic speech recognition systems. The HAT model provides a way to measure the quality of the internal language model that can be used to decide whether inference with an external language model is beneficial or not. This article also presents a finite context version of the HAT model that addresses the exposure bias problem and significantly simplifies the overall training and inference. We evaluate our proposed model on a large-scale voice search task. Our experiments show significant improvements in WER compared to the state-of-the-art approaches.