Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid Autoregressive Transducer (hat)
Paper and Code
Mar 12, 2020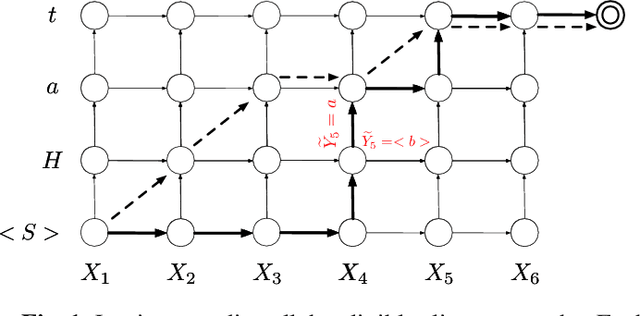

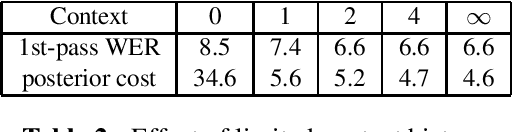
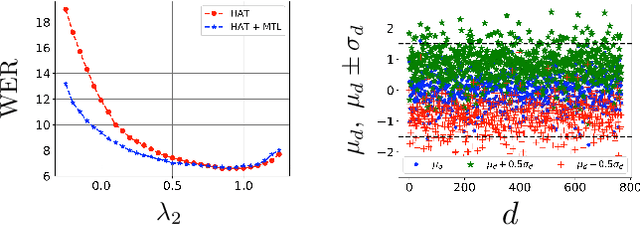
This paper proposes and evaluates the hybrid autoregressive transducer (HAT) model, a time-synchronous encoderdecoder model that preserves the modularity of conventional automatic speech recognition systems. The HAT model provides a way to measure the quality of the internal language model that can be used to decide whether inference with an external language model is beneficial or not. This article also presents a finite context version of the HAT model that addresses the exposure bias problem and significantly simplifies the overall training and inference. We evaluate our proposed model on a large-scale voice search task. Our experiments show significant improvements in WER compared to the state-of-the-art approaches.
View paper on