 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemini Embedding 2: A Native Multimodal Embedding Model from Gemini
May 26, 2026We introduce Gemini Embedding 2, a native multimodal embedding model that allows embedding video, audio, image, and text modalities in a unified representation space. We leverage the multimodal capabilities of Gemini to produce embeddings for arbitrary combinations of interleaved inputs across all these modalities that generalize well across a wide variety of tasks. Applying large-scale contrastive learning in a multi-task multi-stage training setup, we achieve state-of-the-art performance on key embedding benchmarks including unimodal, cross-modal, and multimodal retrieval spanning a diverse set of tasks. We show that our embedding model demonstrates strong performance (with a score of 62.9 R@1 on MSCOCO, 68.8 NDCG@10 on Vatex, 69.9 on MTEB multilingual and 84.0 on MTEB Code) across a variety of tasks surpassing the performance of specialized models. These unified capabilities make Gemini Embedding 2 a promising candidate for downstream use cases such as RAG, recommendation and search. Furthermore, its robust zero-shot performance across distinct fields - from astronomy and bioscience to fine arts and the culinary arts - establishes it as a highly reliable, out-of-the-box representation even for specialized domains.
Benchmarking LLMs on the Massive Sound Embedding Benchmark (MSEB)
May 06, 2026The Massive Sound Embedding Benchmark (MSEB) has emerged as a standard for evaluating the functional breadth of audio models. While initial baselines focused on specialized encoders, the shift toward "audio-native" Large Language Models (LLMs) suggests a new paradigm where a single multimodal backbone may replace complex, task-specific pipelines. This paper provides a rigorous empirical evaluation of leading LLMs - including members from the Gemini and GPT families - across the eight core MSEB capabilities to assess their efficacy and audio-text parity. Our results indicate that while a significant modality gap persists regarding performance and robustness, the empirical evidence for an "optimal" modeling approach remains inconclusive. Ultimately, the choice between audionative and cascaded architectures depends heavily on specific use-case requirements and the underlying assumptions regarding latency, cost, and reasoning depth.
Massive Sound Embedding Benchmark (MSEB)
Feb 06, 2026Audio is a critical component of multimodal perception, and any truly intelligent system must demonstrate a wide range of auditory capabilities. These capabilities include transcription, classification, retrieval, reasoning, segmentation, clustering, reranking, and reconstruction. Fundamentally, each task involves transforming a raw audio signal into a meaningful 'embedding' - be it a single vector, a sequence of continuous or discrete representations, or another structured form - which then serves as the basis for generating the task's final response. To accelerate progress towards robust machine auditory intelligence, we present the Massive Sound Embedding Benchmark (MSEB): an extensible framework designed to evaluate the auditory components of any multimodal system. In its first release, MSEB offers a comprehensive suite of eight core tasks, with more planned for the future, supported by diverse datasets, including the new, large-scale Simple Voice Questions (SVQ) dataset. Our initial experiments establish clear performance headrooms, highlighting the significant opportunity to improve real-world multimodal experiences where audio is a core signal. We encourage the research community to use MSEB to assess their algorithms and contribute to its growth. The library is publicly hosted at github.
Multilingual and Fully Non-Autoregressive ASR with Large Language Model Fusion: A Comprehensive Study
Jan 23, 2024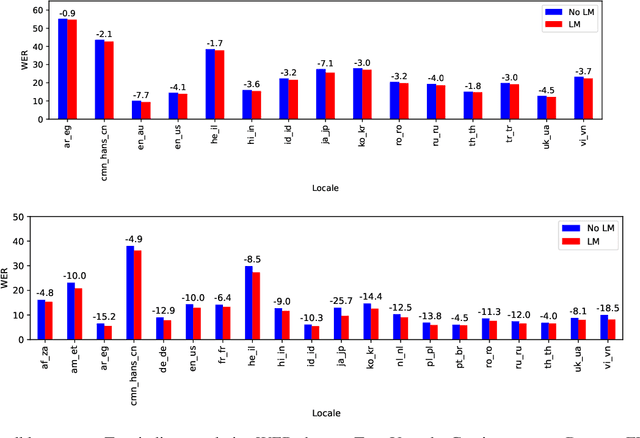
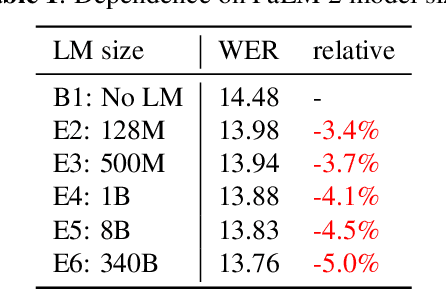
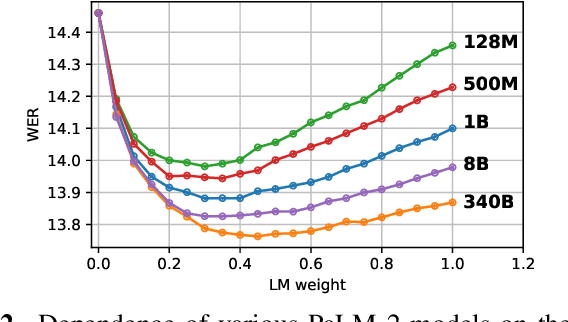
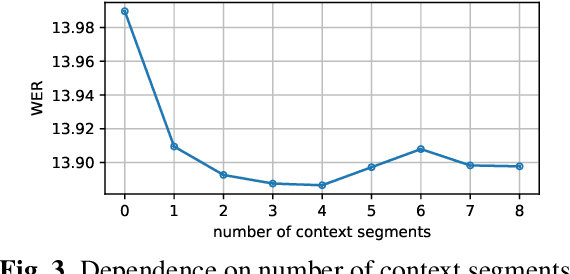
In the era of large models, the autoregressive nature of decoding often results in latency serving as a significant bottleneck. We propose a non-autoregressive LM-fused ASR system that effectively leverages the parallelization capabilities of accelerator hardware. Our approach combines the Universal Speech Model (USM) and the PaLM 2 language model in per-segment scoring mode, achieving an average relative WER improvement across all languages of 10.8% on FLEURS and 3.6% on YouTube captioning. Furthermore, our comprehensive ablation study analyzes key parameters such as LLM size, context length, vocabulary size, fusion methodology. For instance, we explore the impact of LLM size ranging from 128M to 340B parameters on ASR performance. This study provides valuable insights into the factors influencing the effectiveness of practical large-scale LM-fused speech recognition systems.
Large-scale Language Model Rescoring on Long-form Data
Jun 13, 2023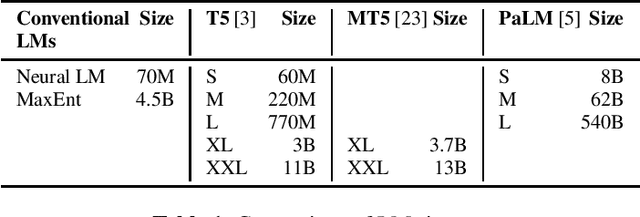
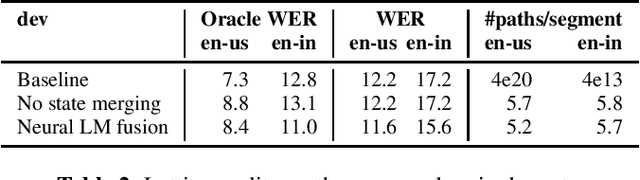


In this work, we study the impact of Large-scale Language Models (LLM) on Automated Speech Recognition (ASR) of YouTube videos, which we use as a source for long-form ASR. We demonstrate up to 8\% relative reduction in Word Error Eate (WER) on US English (en-us) and code-switched Indian English (en-in) long-form ASR test sets and a reduction of up to 30\% relative on Salient Term Error Rate (STER) over a strong first-pass baseline that uses a maximum-entropy based language model. Improved lattice processing that results in a lattice with a proper (non-tree) digraph topology and carrying context from the 1-best hypothesis of the previous segment(s) results in significant wins in rescoring with LLMs. We also find that the gains in performance from the combination of LLMs trained on vast quantities of available data (such as C4) and conventional neural LMs is additive and significantly outperforms a strong first-pass baseline with a maximum entropy LM.
* 5 pages, accepted in ICASSP 2023
Alignment Entropy Regularization
Dec 22, 2022



Existing training criteria in automatic speech recognition(ASR) permit the model to freely explore more than one time alignments between the feature and label sequences. In this paper, we use entropy to measure a model's uncertainty, i.e. how it chooses to distribute the probability mass over the set of allowed alignments. Furthermore, we evaluate the effect of entropy regularization in encouraging the model to distribute the probability mass only on a smaller subset of allowed alignments. Experiments show that entropy regularization enables a much simpler decoding method without sacrificing word error rate, and provides better time alignment quality.
E2E Segmentation in a Two-Pass Cascaded Encoder ASR Model
Nov 28, 2022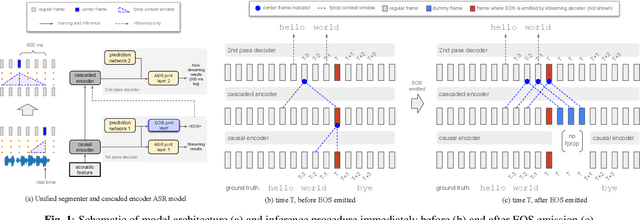
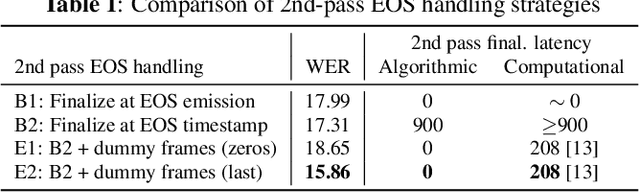
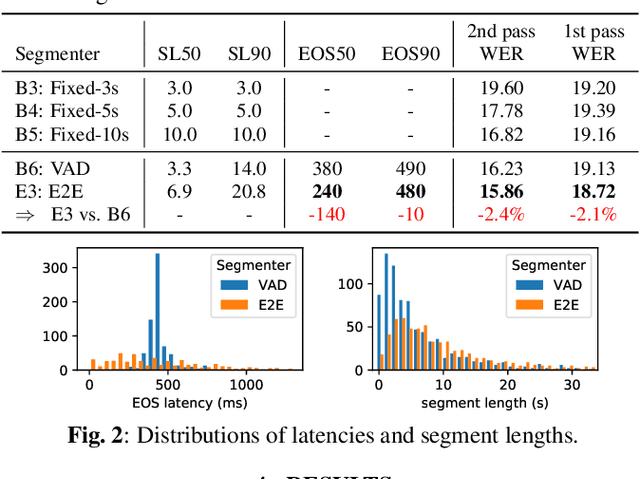

We explore unifying a neural segmenter with two-pass cascaded encoder ASR into a single model. A key challenge is allowing the segmenter (which runs in real-time, synchronously with the decoder) to finalize the 2nd pass (which runs 900 ms behind real-time) without introducing user-perceived latency or deletion errors during inference. We propose a design where the neural segmenter is integrated with the causal 1st pass decoder to emit a end-of-segment (EOS) signal in real-time. The EOS signal is then used to finalize the non-causal 2nd pass. We experiment with different ways to finalize the 2nd pass, and find that a novel dummy frame injection strategy allows for simultaneous high quality 2nd pass results and low finalization latency. On a real-world long-form captioning task (YouTube), we achieve 2.4% relative WER and 140 ms EOS latency gains over a baseline VAD-based segmenter with the same cascaded encoder.
Global Normalization for Streaming Speech Recognition in a Modular Framework
May 26, 2022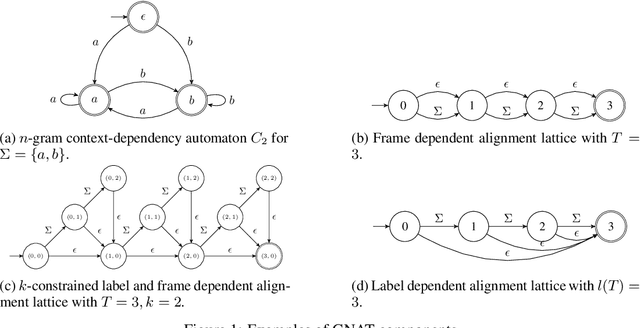
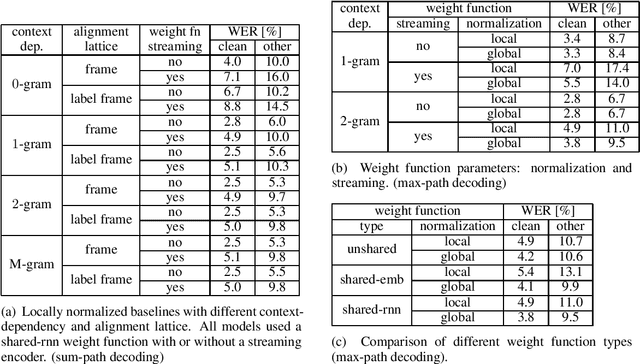
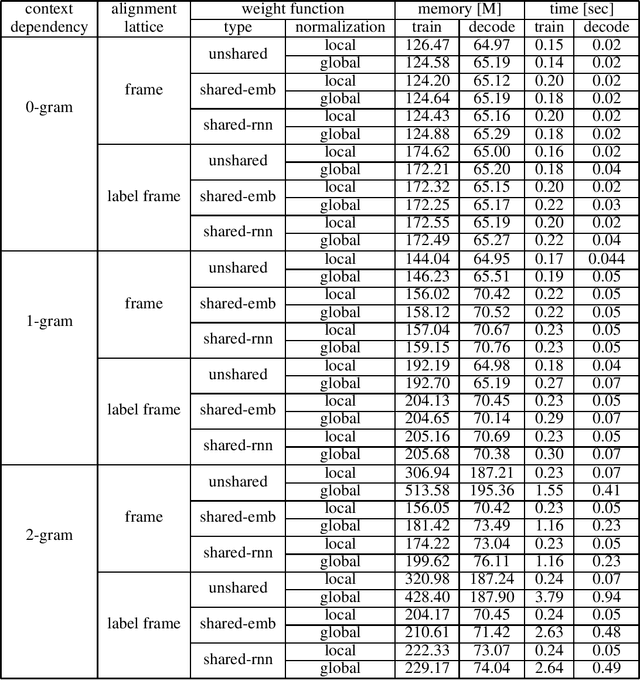
We introduce the Globally Normalized Autoregressive Transducer (GNAT) for addressing the label bias problem in streaming speech recognition. Our solution admits a tractable exact computation of the denominator for the sequence-level normalization. Through theoretical and empirical results, we demonstrate that by switching to a globally normalized model, the word error rate gap between streaming and non-streaming speech-recognition models can be greatly reduced (by more than 50\% on the Librispeech dataset). This model is developed in a modular framework which encompasses all the common neural speech recognition models. The modularity of this framework enables controlled comparison of modelling choices and creation of new models.
E2E Segmenter: Joint Segmenting and Decoding for Long-Form ASR
Apr 22, 2022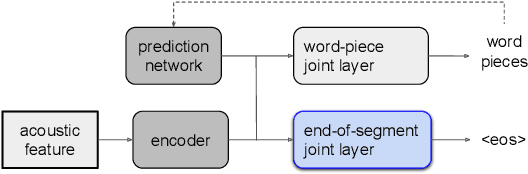
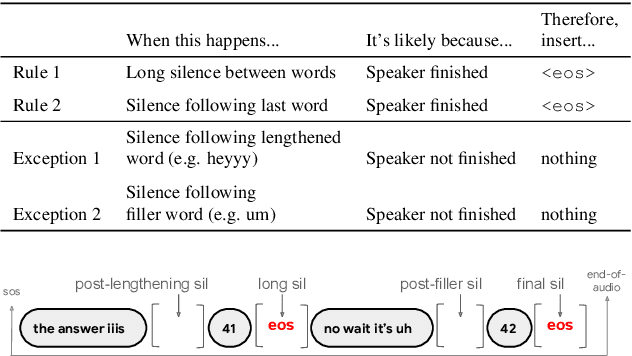
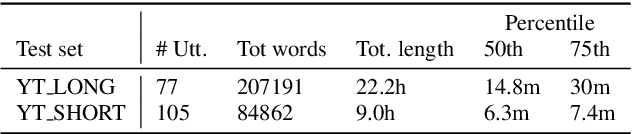
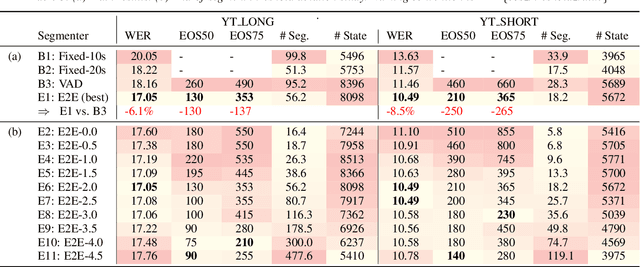
Improving the performance of end-to-end ASR models on long utterances ranging from minutes to hours in length is an ongoing challenge in speech recognition. A common solution is to segment the audio in advance using a separate voice activity detector (VAD) that decides segment boundary locations based purely on acoustic speech/non-speech information. VAD segmenters, however, may be sub-optimal for real-world speech where, e.g., a complete sentence that should be taken as a whole may contain hesitations in the middle ("set an alarm for... 5 o'clock"). We propose to replace the VAD with an end-to-end ASR model capable of predicting segment boundaries in a streaming fashion, allowing the segmentation decision to be conditioned not only on better acoustic features but also on semantic features from the decoded text with negligible extra computation. In experiments on real world long-form audio (YouTube) with lengths of up to 30 minutes, we demonstrate 8.5% relative WER improvement and 250 ms reduction in median end-of-segment latency compared to the VAD segmenter baseline on a state-of-the-art Conformer RNN-T model.
A* shortest string decoding for non-idempotent semirings
Apr 14, 2022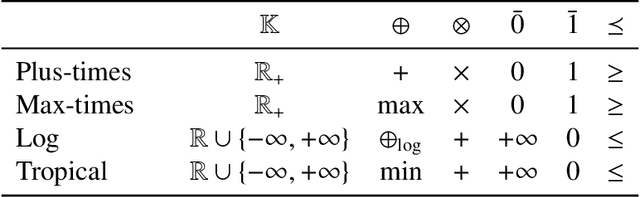
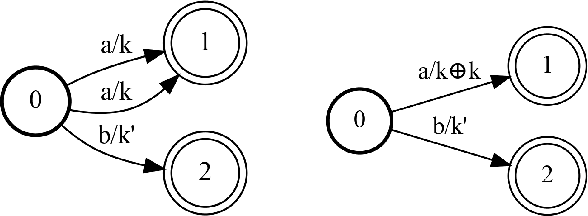
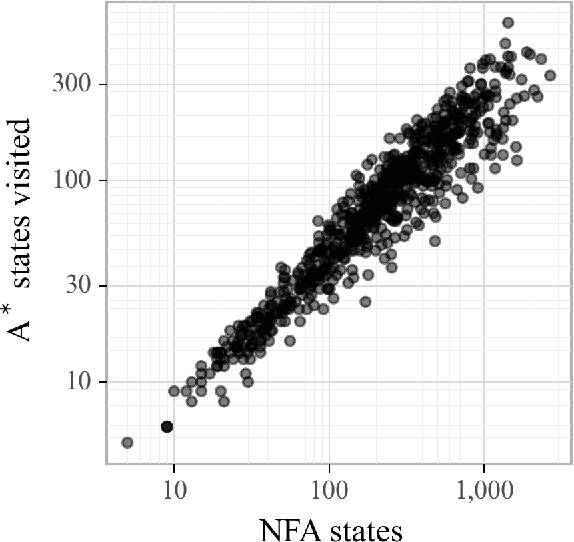
The single shortest path algorithm is undefined for weighted finite-state automata over non-idempotent semirings because such semirings do not guarantee the existence of a shortest path. However, in non-idempotent semirings admitting an order satisfying a monotonicity condition (such as the plus-times or log semirings), the notion of shortest string is well-defined. We describe an algorithm which finds the shortest string for a weighted non-deterministic automaton over such semirings using the backwards shortest distance of an equivalent deterministic automaton (DFA) as a heuristic for A* search performed over a companion idempotent semiring, which is proven to return the shortest string. While there may be exponentially more states in the DFA, this algorithm needs to visit only a small fraction of them if determinization is performed "on the fly".