 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge-scale Language Model Rescoring on Long-form Data
Jun 13, 2023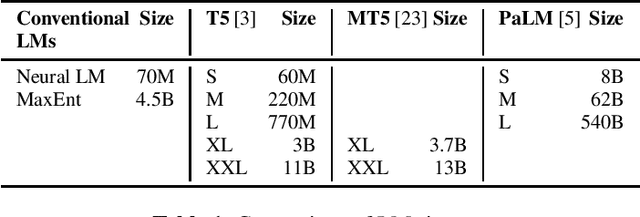
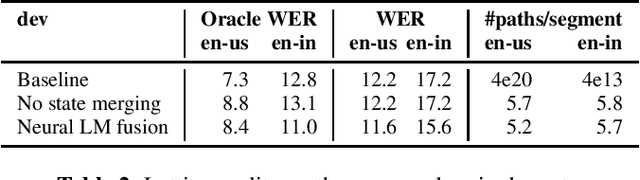


In this work, we study the impact of Large-scale Language Models (LLM) on Automated Speech Recognition (ASR) of YouTube videos, which we use as a source for long-form ASR. We demonstrate up to 8\% relative reduction in Word Error Eate (WER) on US English (en-us) and code-switched Indian English (en-in) long-form ASR test sets and a reduction of up to 30\% relative on Salient Term Error Rate (STER) over a strong first-pass baseline that uses a maximum-entropy based language model. Improved lattice processing that results in a lattice with a proper (non-tree) digraph topology and carrying context from the 1-best hypothesis of the previous segment(s) results in significant wins in rescoring with LLMs. We also find that the gains in performance from the combination of LLMs trained on vast quantities of available data (such as C4) and conventional neural LMs is additive and significantly outperforms a strong first-pass baseline with a maximum entropy LM.
* 5 pages, accepted in ICASSP 2023
Universal Paralinguistic Speech Representations Using Self-Supervised Conformers
Oct 09, 2021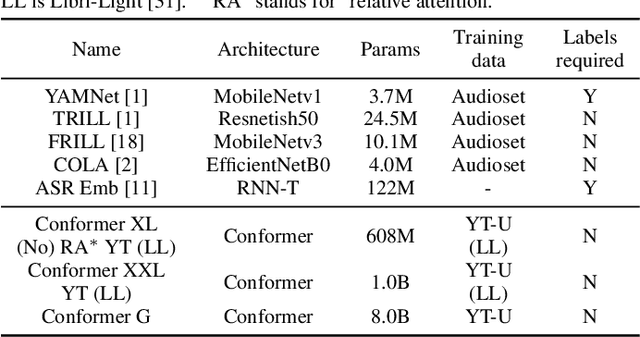
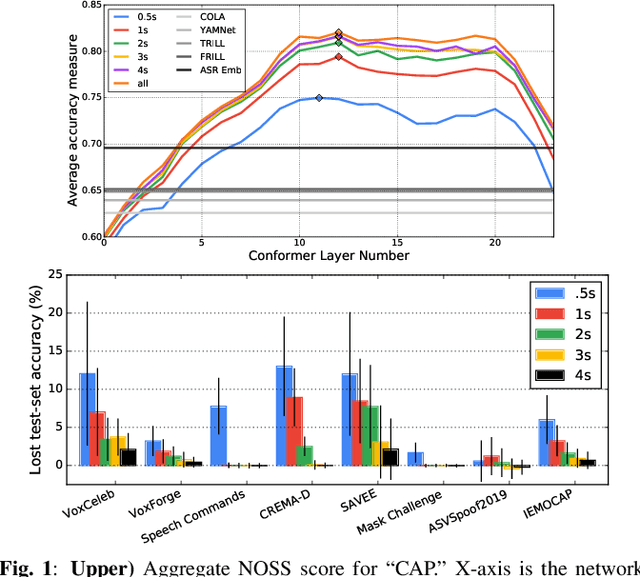
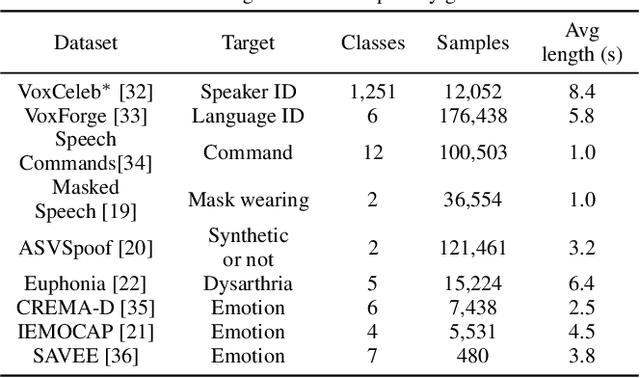
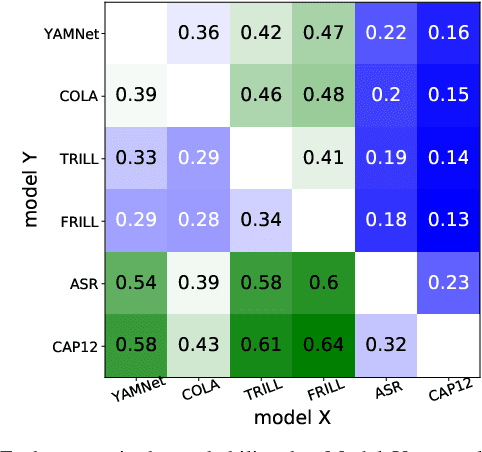
Many speech applications require understanding aspects beyond the words being spoken, such as recognizing emotion, detecting whether the speaker is wearing a mask, or distinguishing real from synthetic speech. In this work, we introduce a new state-of-the-art paralinguistic representation derived from large-scale, fully self-supervised training of a 600M+ parameter Conformer-based architecture. We benchmark on a diverse set of speech tasks and demonstrate that simple linear classifiers trained on top of our time-averaged representation outperform nearly all previous results, in some cases by large margins. Our analyses of context-window size demonstrate that, surprisingly, 2 second context-windows achieve 98% the performance of the Conformers that use the full long-term context. Furthermore, while the best per-task representations are extracted internally in the network, stable performance across several layers allows a single universal representation to reach near optimal performance on all tasks.
Output Randomization: A Novel Defense for both White-box and Black-box Adversarial Models
Jul 08, 2021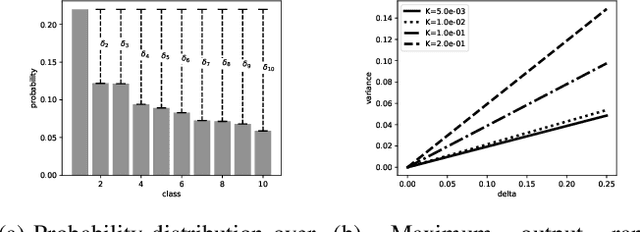
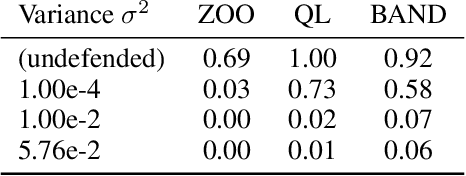
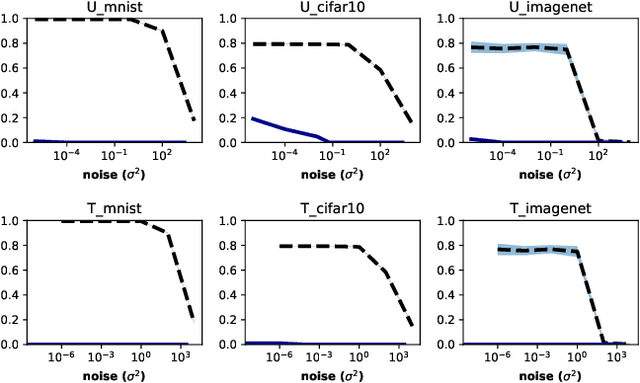
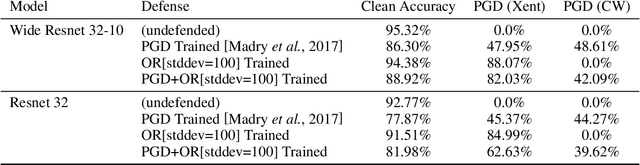
Adversarial examples pose a threat to deep neural network models in a variety of scenarios, from settings where the adversary has complete knowledge of the model in a "white box" setting and to the opposite in a "black box" setting. In this paper, we explore the use of output randomization as a defense against attacks in both the black box and white box models and propose two defenses. In the first defense, we propose output randomization at test time to thwart finite difference attacks in black box settings. Since this type of attack relies on repeated queries to the model to estimate gradients, we investigate the use of randomization to thwart such adversaries from successfully creating adversarial examples. We empirically show that this defense can limit the success rate of a black box adversary using the Zeroth Order Optimization attack to 0%. Secondly, we propose output randomization training as a defense against white box adversaries. Unlike prior approaches that use randomization, our defense does not require its use at test time, eliminating the Backward Pass Differentiable Approximation attack, which was shown to be effective against other randomization defenses. Additionally, this defense has low overhead and is easily implemented, allowing it to be used together with other defenses across various model architectures. We evaluate output randomization training against the Projected Gradient Descent attacker and show that the defense can reduce the PGD attack's success rate down to 12% when using cross-entropy loss.
SpeechStew: Simply Mix All Available Speech Recognition Data to Train One Large Neural Network
Apr 27, 2021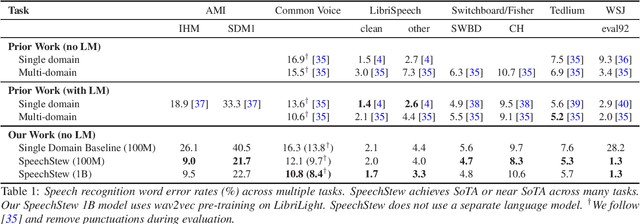
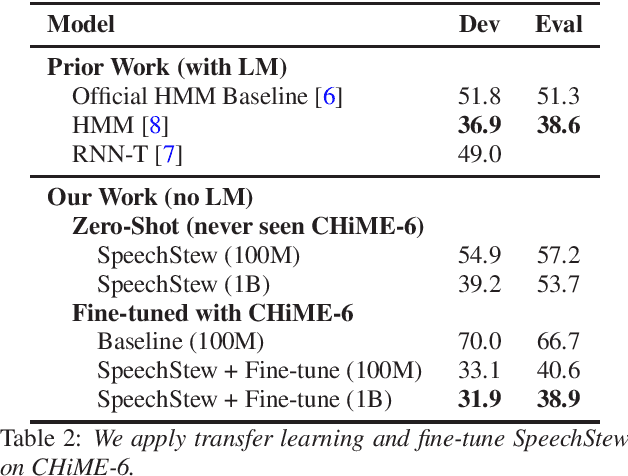
We present SpeechStew, a speech recognition model that is trained on a combination of various publicly available speech recognition datasets: AMI, Broadcast News, Common Voice, LibriSpeech, Switchboard/Fisher, Tedlium, and Wall Street Journal. SpeechStew simply mixes all of these datasets together, without any special re-weighting or re-balancing of the datasets. SpeechStew achieves SoTA or near SoTA results across a variety of tasks, without the use of an external language model. Our results include 9.0\% WER on AMI-IHM, 4.7\% WER on Switchboard, 8.3\% WER on CallHome, and 1.3\% on WSJ, which significantly outperforms prior work with strong external language models. We also demonstrate that SpeechStew learns powerful transfer learning representations. We fine-tune SpeechStew on a noisy low resource speech dataset, CHiME-6. We achieve 38.9\% WER without a language model, which compares to 38.6\% WER to a strong HMM baseline with a language model.
Towards Obfuscated Malware Detection for Low Powered IoT Devices
Nov 06, 2020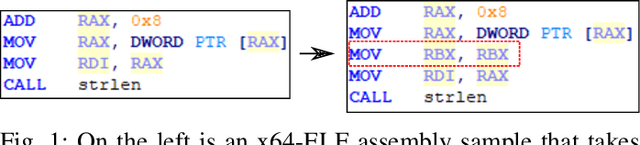
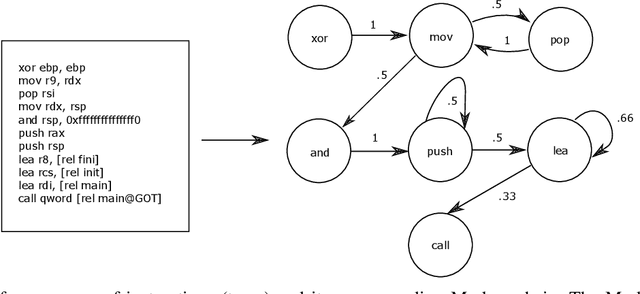
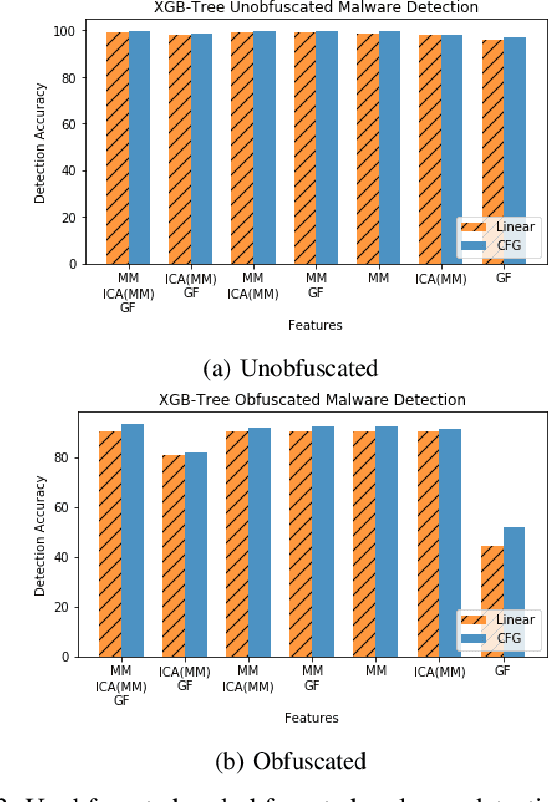
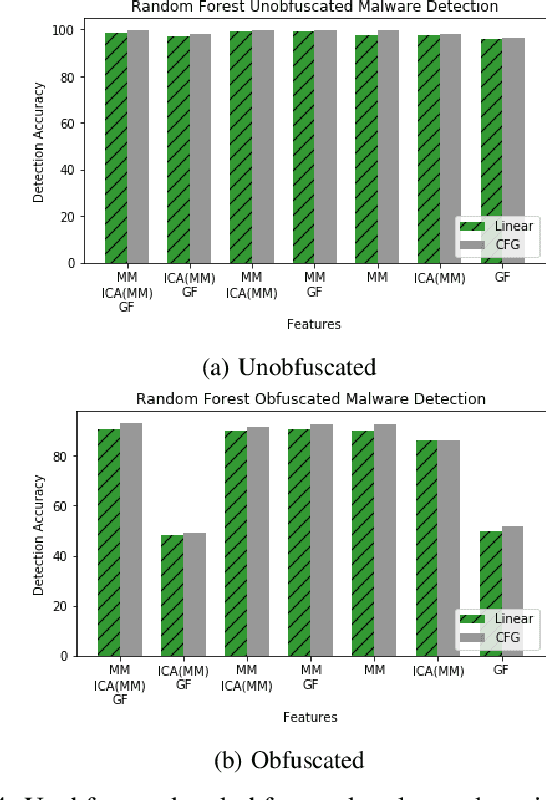
With the increased deployment of IoT and edge devices into commercial and user networks, these devices have become a new threat vector for malware authors. It is imperative to protect these devices as they become more prevalent in commercial and personal networks. However, due to their limited computational power and storage space, especially in the case of battery-powered devices, it is infeasible to deploy state-of-the-art malware detectors onto these systems. In this work, we propose using and extracting features from Markov matrices constructed from opcode traces as a low cost feature for unobfuscated and obfuscated malware detection. We empirically show that our approach maintains a high detection rate while consuming less power than similar work.
A survey on practical adversarial examples for malware classifiers
Nov 06, 2020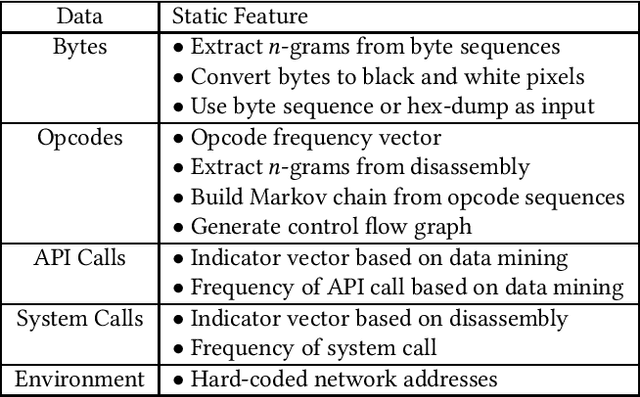


Machine learning based solutions have been very helpful in solving problems that deal with immense amounts of data, such as malware detection and classification. However, deep neural networks have been found to be vulnerable to adversarial examples, or inputs that have been purposefully perturbed to result in an incorrect label. Researchers have shown that this vulnerability can be exploited to create evasive malware samples. However, many proposed attacks do not generate an executable and instead generate a feature vector. To fully understand the impact of adversarial examples on malware detection, we review practical attacks against malware classifiers that generate executable adversarial malware examples. We also discuss current challenges in this area of research, as well as suggestions for improvement and future research directions.
Thwarting finite difference adversarial attacks with output randomization
May 23, 2019

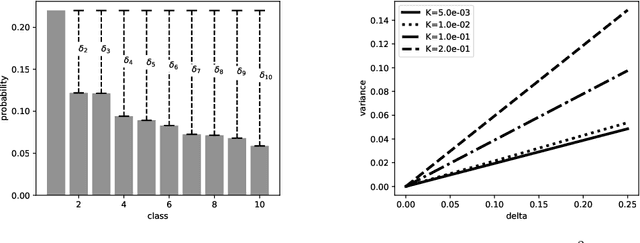
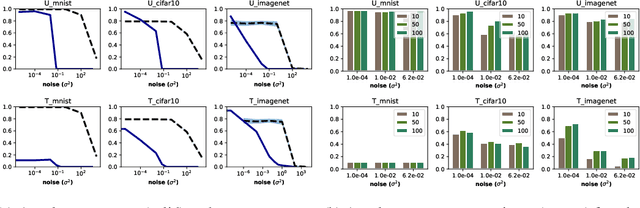
Adversarial examples pose a threat to deep neural network models in a variety of scenarios, from settings where the adversary has complete knowledge of the model and to the opposite "black box" setting. Black box attacks are particularly threatening as the adversary only needs access to the input and output of the model. Defending against black box adversarial example generation attacks is paramount as currently proposed defenses are not effective. Since these types of attacks rely on repeated queries to the model to estimate gradients over input dimensions, we investigate the use of randomization to thwart such adversaries from successfully creating adversarial examples. Randomization applied to the output of the deep neural network model has the potential to confuse potential attackers, however this introduces a tradeoff between accuracy and robustness. We show that for certain types of randomization, we can bound the probability of introducing errors by carefully setting distributional parameters. For the particular case of finite difference black box attacks, we quantify the error introduced by the defense in the finite difference estimate of the gradient. Lastly, we show empirically that the defense can thwart two adaptive black box adversarial attack algorithms.
Short Paper: Creating Adversarial Malware Examples using Code Insertion
Apr 09, 2019


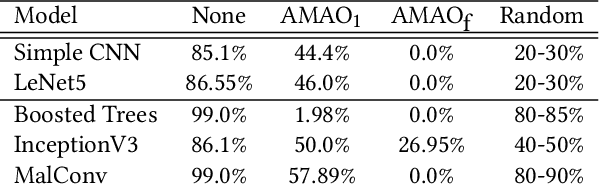
There has been an increased interest in the application of convolutional neural networks for image based malware classification, but the susceptibility of neural networks to adversarial examples allows malicious actors to evade classifiers. We shed light on the definition of an adversarial example in the malware domain. Then, we propose a method to obfuscate malware using patterns found in adversarial examples such that the newly obfuscated malware evades classification while maintaining executability and the original program logic.