 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual and Fully Non-Autoregressive ASR with Large Language Model Fusion: A Comprehensive Study
Jan 23, 2024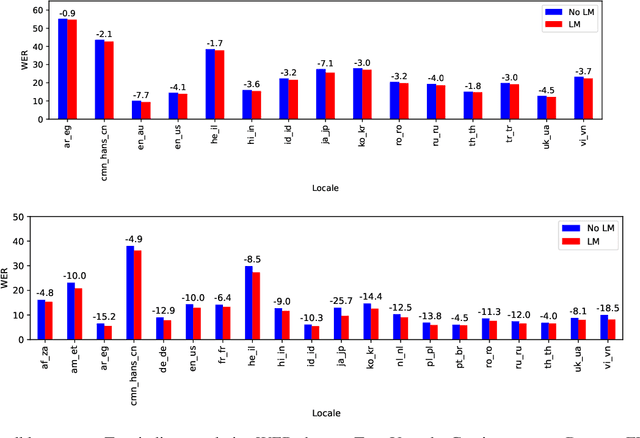
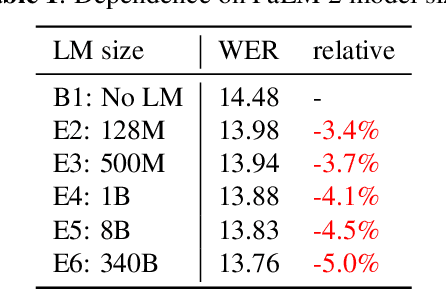
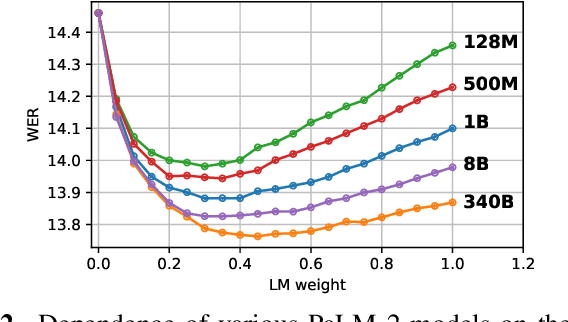
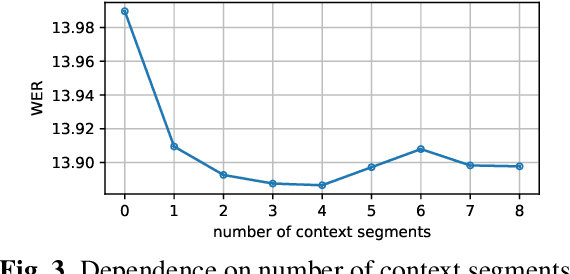
In the era of large models, the autoregressive nature of decoding often results in latency serving as a significant bottleneck. We propose a non-autoregressive LM-fused ASR system that effectively leverages the parallelization capabilities of accelerator hardware. Our approach combines the Universal Speech Model (USM) and the PaLM 2 language model in per-segment scoring mode, achieving an average relative WER improvement across all languages of 10.8% on FLEURS and 3.6% on YouTube captioning. Furthermore, our comprehensive ablation study analyzes key parameters such as LLM size, context length, vocabulary size, fusion methodology. For instance, we explore the impact of LLM size ranging from 128M to 340B parameters on ASR performance. This study provides valuable insights into the factors influencing the effectiveness of practical large-scale LM-fused speech recognition systems.
Large-scale Language Model Rescoring on Long-form Data
Jun 13, 2023
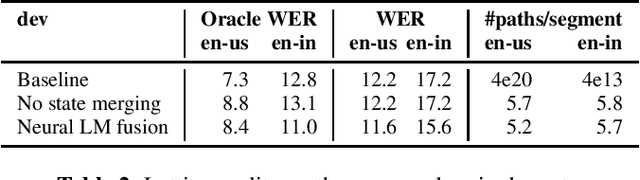


In this work, we study the impact of Large-scale Language Models (LLM) on Automated Speech Recognition (ASR) of YouTube videos, which we use as a source for long-form ASR. We demonstrate up to 8\% relative reduction in Word Error Eate (WER) on US English (en-us) and code-switched Indian English (en-in) long-form ASR test sets and a reduction of up to 30\% relative on Salient Term Error Rate (STER) over a strong first-pass baseline that uses a maximum-entropy based language model. Improved lattice processing that results in a lattice with a proper (non-tree) digraph topology and carrying context from the 1-best hypothesis of the previous segment(s) results in significant wins in rescoring with LLMs. We also find that the gains in performance from the combination of LLMs trained on vast quantities of available data (such as C4) and conventional neural LMs is additive and significantly outperforms a strong first-pass baseline with a maximum entropy LM.
* 5 pages, accepted in ICASSP 2023
Semantic Segmentation with Bidirectional Language Models Improves Long-form ASR
May 28, 2023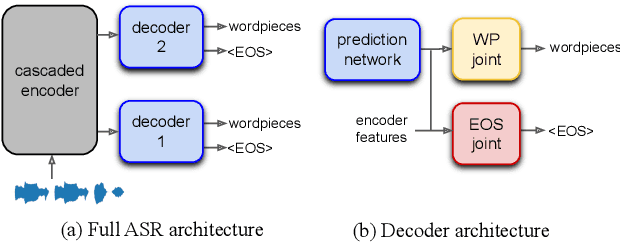
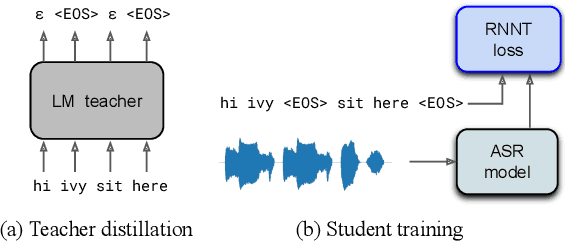
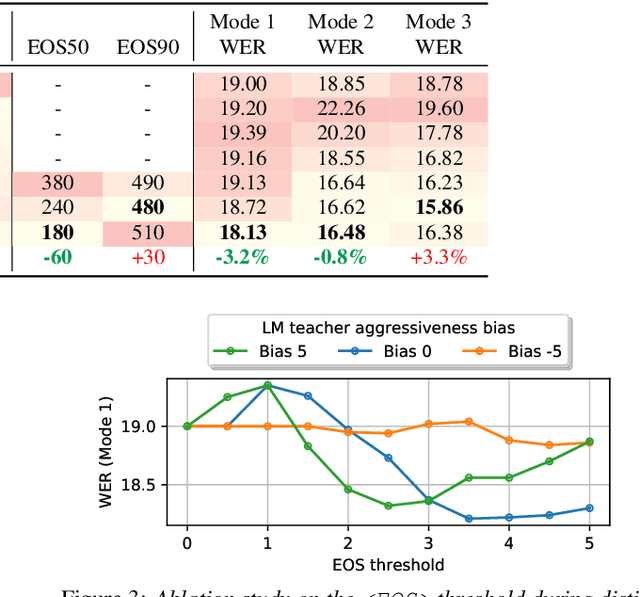
We propose a method of segmenting long-form speech by separating semantically complete sentences within the utterance. This prevents the ASR decoder from needlessly processing faraway context while also preventing it from missing relevant context within the current sentence. Semantically complete sentence boundaries are typically demarcated by punctuation in written text; but unfortunately, spoken real-world utterances rarely contain punctuation. We address this limitation by distilling punctuation knowledge from a bidirectional teacher language model (LM) trained on written, punctuated text. We compare our segmenter, which is distilled from the LM teacher, against a segmenter distilled from a acoustic-pause-based teacher used in other works, on a streaming ASR pipeline. The pipeline with our segmenter achieves a 3.2% relative WER gain along with a 60 ms median end-of-segment latency reduction on a YouTube captioning task.
E2E Segmentation in a Two-Pass Cascaded Encoder ASR Model
Nov 28, 2022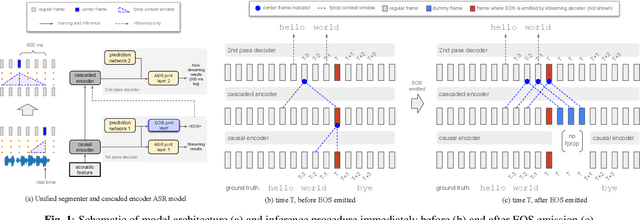
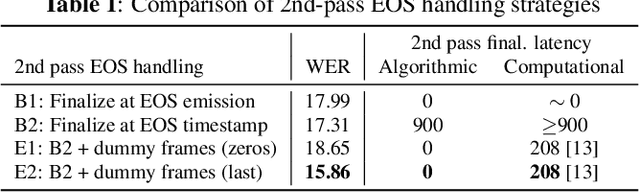
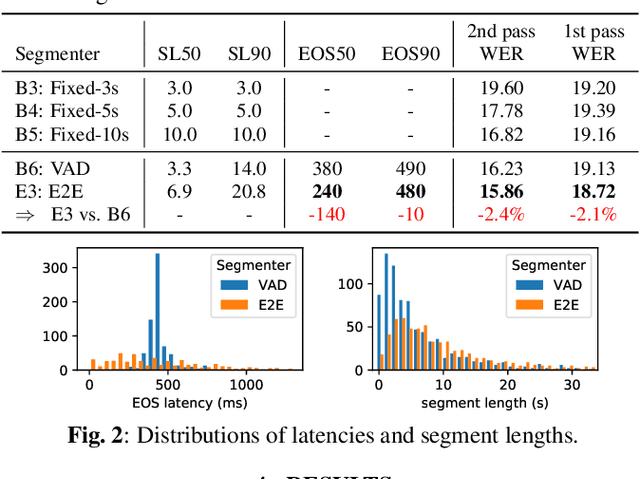

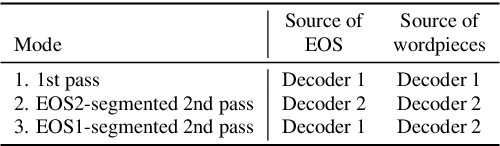
We explore unifying a neural segmenter with two-pass cascaded encoder ASR into a single model. A key challenge is allowing the segmenter (which runs in real-time, synchronously with the decoder) to finalize the 2nd pass (which runs 900 ms behind real-time) without introducing user-perceived latency or deletion errors during inference. We propose a design where the neural segmenter is integrated with the causal 1st pass decoder to emit a end-of-segment (EOS) signal in real-time. The EOS signal is then used to finalize the non-causal 2nd pass. We experiment with different ways to finalize the 2nd pass, and find that a novel dummy frame injection strategy allows for simultaneous high quality 2nd pass results and low finalization latency. On a real-world long-form captioning task (YouTube), we achieve 2.4% relative WER and 140 ms EOS latency gains over a baseline VAD-based segmenter with the same cascaded encoder.
Modular Hybrid Autoregressive Transducer
Oct 31, 2022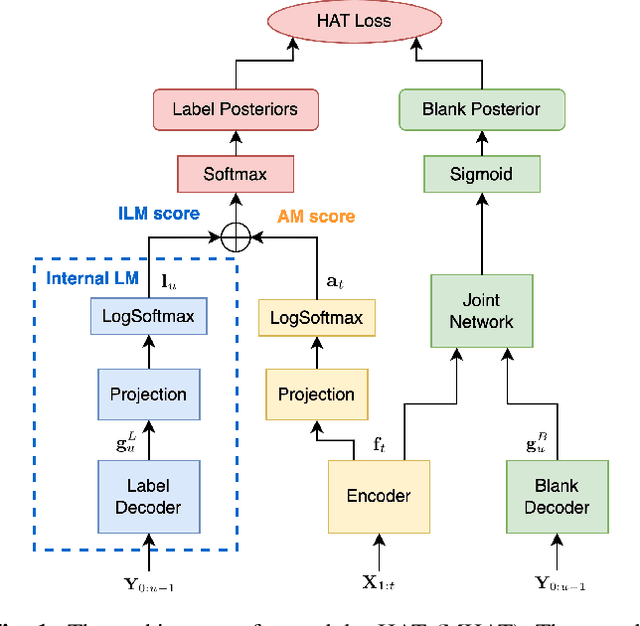
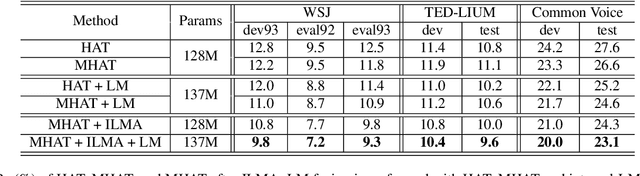
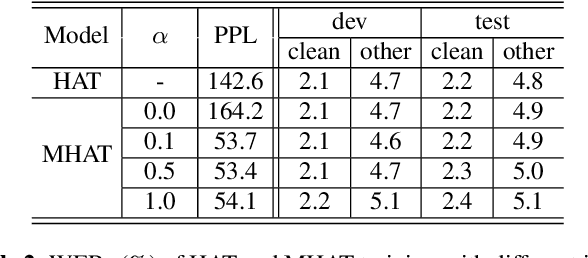
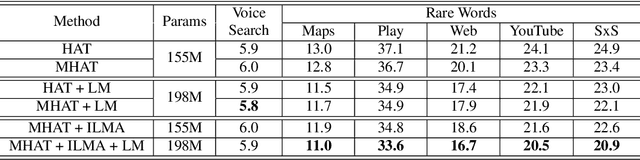
Text-only adaptation of a transducer model remains challenging for end-to-end speech recognition since the transducer has no clearly separated acoustic model (AM), language model (LM) or blank model. In this work, we propose a modular hybrid autoregressive transducer (MHAT) that has structurally separated label and blank decoders to predict label and blank distributions, respectively, along with a shared acoustic encoder. The encoder and label decoder outputs are directly projected to AM and internal LM scores and then added to compute label posteriors. We train MHAT with an internal LM loss and a HAT loss to ensure that its internal LM becomes a standalone neural LM that can be effectively adapted to text. Moreover, text adaptation of MHAT fosters a much better LM fusion than internal LM subtraction-based methods. On Google's large-scale production data, a multi-domain MHAT adapted with 100B sentences achieves relative WER reductions of up to 12.4% without LM fusion and 21.5% with LM fusion from 400K-hour trained HAT.
* 8 pages, 1 figure, SLT 2022
E2E Segmenter: Joint Segmenting and Decoding for Long-Form ASR
Apr 22, 2022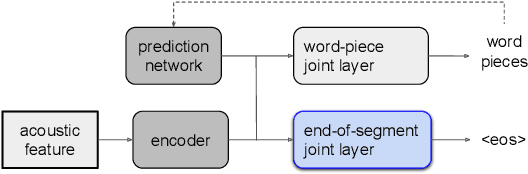
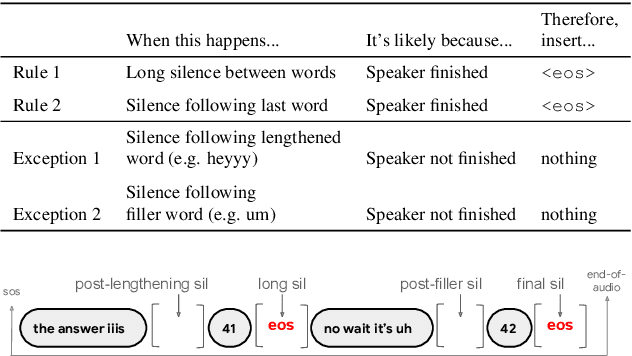
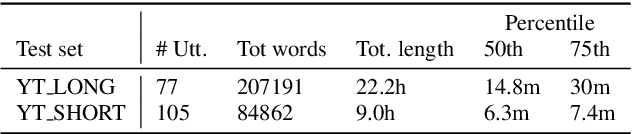
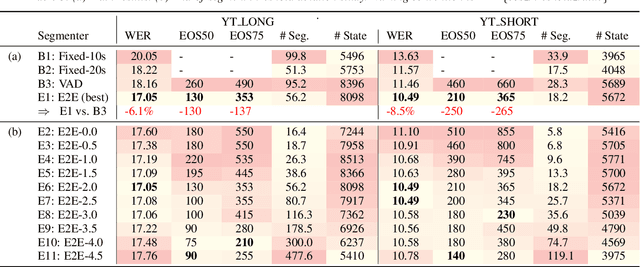
Improving the performance of end-to-end ASR models on long utterances ranging from minutes to hours in length is an ongoing challenge in speech recognition. A common solution is to segment the audio in advance using a separate voice activity detector (VAD) that decides segment boundary locations based purely on acoustic speech/non-speech information. VAD segmenters, however, may be sub-optimal for real-world speech where, e.g., a complete sentence that should be taken as a whole may contain hesitations in the middle ("set an alarm for... 5 o'clock"). We propose to replace the VAD with an end-to-end ASR model capable of predicting segment boundaries in a streaming fashion, allowing the segmentation decision to be conditioned not only on better acoustic features but also on semantic features from the decoded text with negligible extra computation. In experiments on real world long-form audio (YouTube) with lengths of up to 30 minutes, we demonstrate 8.5% relative WER improvement and 250 ms reduction in median end-of-segment latency compared to the VAD segmenter baseline on a state-of-the-art Conformer RNN-T model.
Detecting Unintended Memorization in Language-Model-Fused ASR
Apr 20, 2022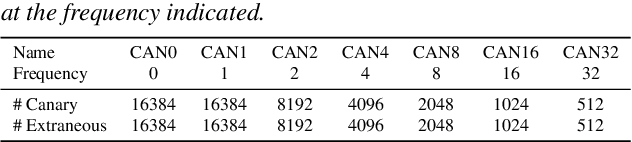
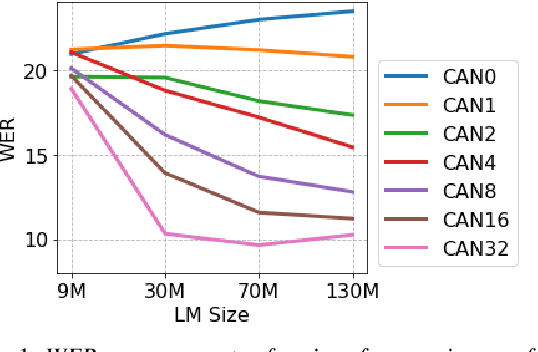
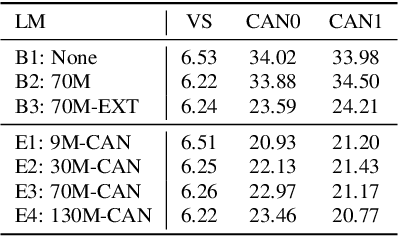
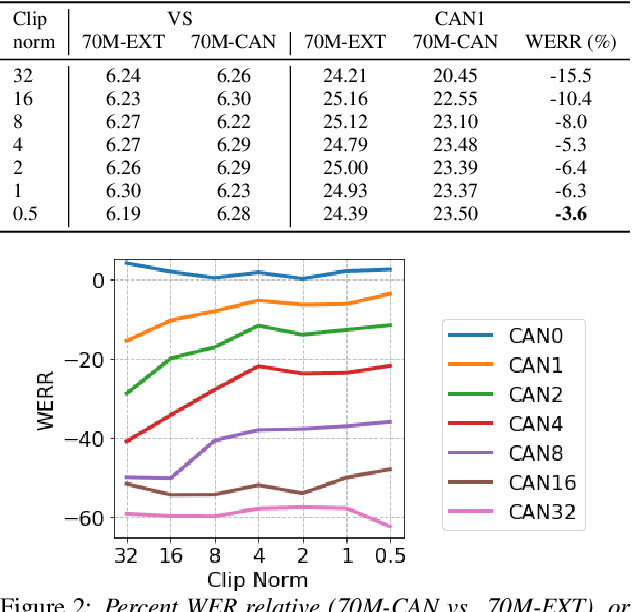
End-to-end (E2E) models are often being accompanied by language models (LMs) via shallow fusion for boosting their overall quality as well as recognition of rare words. At the same time, several prior works show that LMs are susceptible to unintentionally memorizing rare or unique sequences in the training data. In this work, we design a framework for detecting memorization of random textual sequences (which we call canaries) in the LM training data when one has only black-box (query) access to LM-fused speech recognizer, as opposed to direct access to the LM. On a production-grade Conformer RNN-T E2E model fused with a Transformer LM, we show that detecting memorization of singly-occurring canaries from the LM training data of 300M examples is possible. Motivated to protect privacy, we also show that such memorization gets significantly reduced by per-example gradient-clipped LM training without compromising overall quality.
Sentence-Select: Large-Scale Language Model Data Selection for Rare-Word Speech Recognition
Mar 09, 2022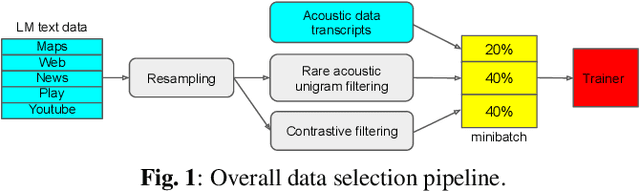
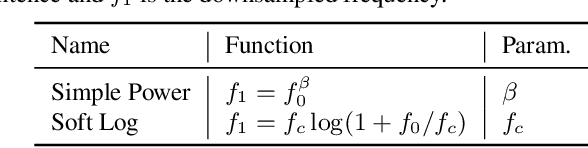
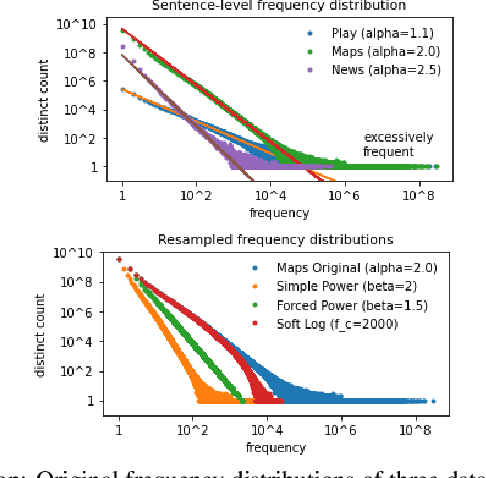
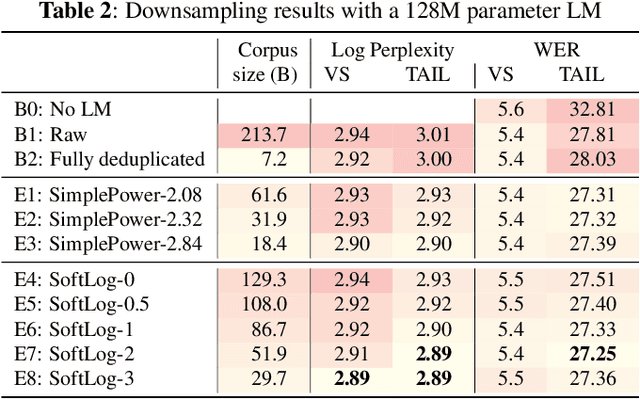
Language model fusion helps smart assistants recognize words which are rare in acoustic data but abundant in text-only corpora (typed search logs). However, such corpora have properties that hinder downstream performance, including being (1) too large, (2) beset with domain-mismatched content, and (3) heavy-headed rather than heavy-tailed (excessively many duplicate search queries such as "weather"). We show that three simple strategies for selecting language modeling data can dramatically improve rare-word recognition without harming overall performance. First, to address the heavy-headedness, we downsample the data according to a soft log function, which tunably reduces high frequency (head) sentences. Second, to encourage rare-word exposure, we explicitly filter for words rare in the acoustic data. Finally, we tackle domain-mismatch via perplexity-based contrastive selection, filtering for examples matched to the target domain. We down-select a large corpus of web search queries by a factor of 53x and achieve better LM perplexities than without down-selection. When shallow-fused with a state-of-the-art, production speech engine, our LM achieves WER reductions of up to 24% relative on rare-word sentences (without changing overall WER) compared to a baseline LM trained on the raw corpus. These gains are further validated through favorable side-by-side evaluations on live voice search traffic.
Capitalization Normalization for Language Modeling with an Accurate and Efficient Hierarchical RNN Model
Feb 16, 2022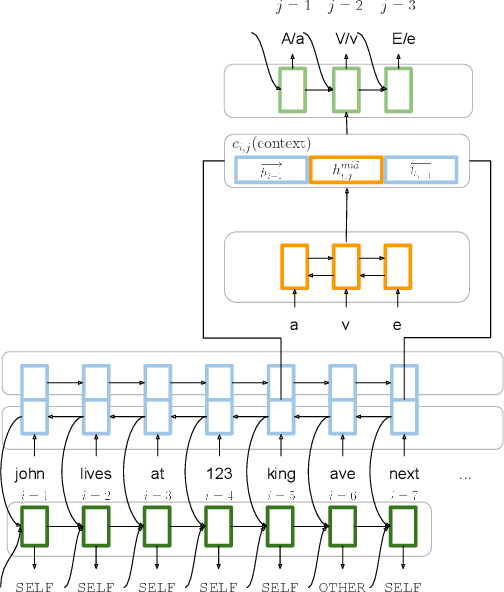
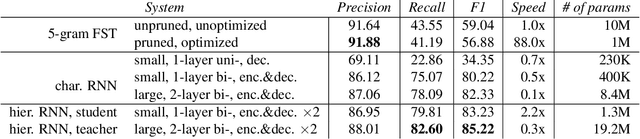

Capitalization normalization (truecasing) is the task of restoring the correct case (uppercase or lowercase) of noisy text. We propose a fast, accurate and compact two-level hierarchical word-and-character-based recurrent neural network model. We use the truecaser to normalize user-generated text in a Federated Learning framework for language modeling. A case-aware language model trained on this normalized text achieves the same perplexity as a model trained on text with gold capitalization. In a real user A/B experiment, we demonstrate that the improvement translates to reduced prediction error rates in a virtual keyboard application. Similarly, in an ASR language model fusion experiment, we show reduction in uppercase character error rate and word error rate.
Scaling End-to-End Models for Large-Scale Multilingual ASR
Apr 30, 2021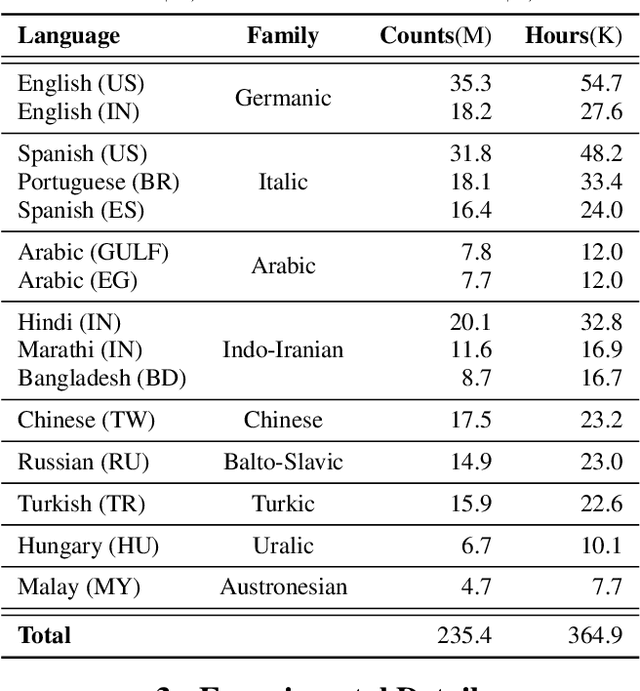
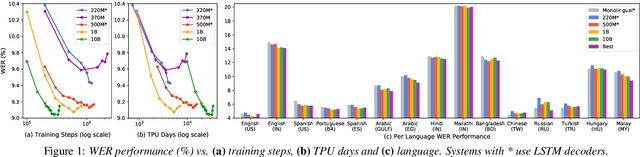

Building ASR models across many language families is a challenging multi-task learning problem due to large language variations and heavily unbalanced data. Existing work has shown positive transfer from high resource to low resource languages. However, degradations on high resource languages are commonly observed due to interference from the heterogeneous multilingual data and reduction in per-language capacity. We conduct a capacity study on a 15-language task, with the amount of data per language varying from 7.7K to 54.7K hours. We adopt GShard [1] to efficiently scale up to 10B parameters. Empirically, we find that (1) scaling the number of model parameters is an effective way to solve the capacity bottleneck - our 500M-param model is already better than monolingual baselines and scaling it to 1B and 10B brought further quality gains; (2) larger models are not only more data efficient, but also more efficient in terms of training cost as measured in TPU days - the 1B-param model reaches the same accuracy at 34% of training time as the 500M-param model; (3) given a fixed capacity budget, adding depth usually works better than width and large encoders tend to do better than large decoders.