 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModular Hybrid Autoregressive Transducer
Oct 31, 2022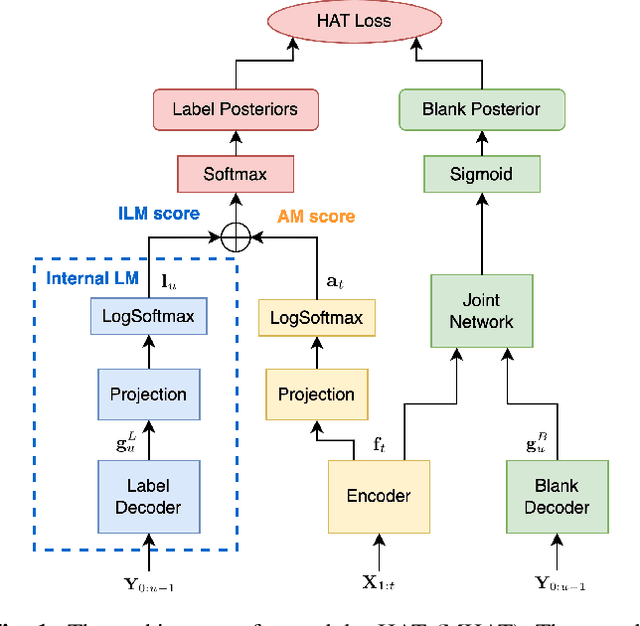
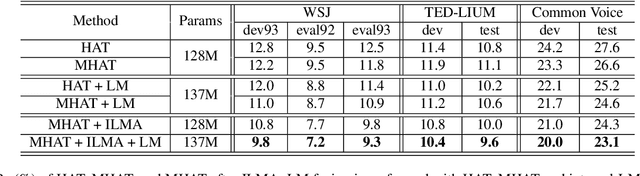
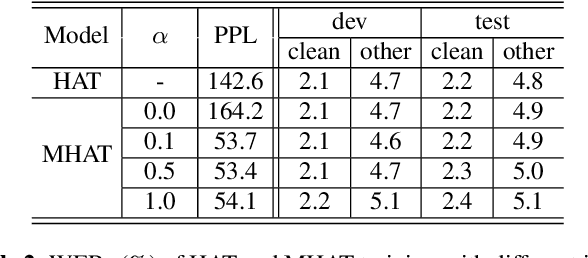
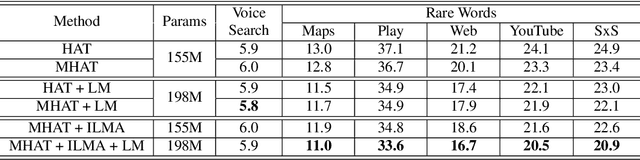
Text-only adaptation of a transducer model remains challenging for end-to-end speech recognition since the transducer has no clearly separated acoustic model (AM), language model (LM) or blank model. In this work, we propose a modular hybrid autoregressive transducer (MHAT) that has structurally separated label and blank decoders to predict label and blank distributions, respectively, along with a shared acoustic encoder. The encoder and label decoder outputs are directly projected to AM and internal LM scores and then added to compute label posteriors. We train MHAT with an internal LM loss and a HAT loss to ensure that its internal LM becomes a standalone neural LM that can be effectively adapted to text. Moreover, text adaptation of MHAT fosters a much better LM fusion than internal LM subtraction-based methods. On Google's large-scale production data, a multi-domain MHAT adapted with 100B sentences achieves relative WER reductions of up to 12.4% without LM fusion and 21.5% with LM fusion from 400K-hour trained HAT.
* 8 pages, 1 figure, SLT 2022
Non-Parallel Voice Conversion for ASR Augmentation
Sep 15, 2022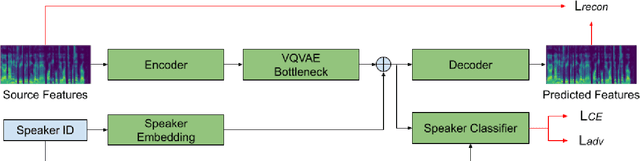
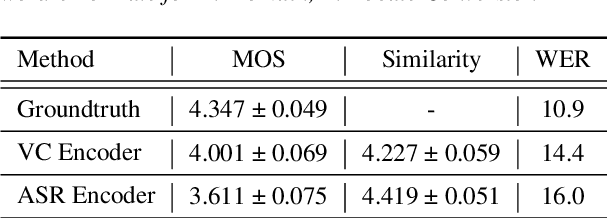
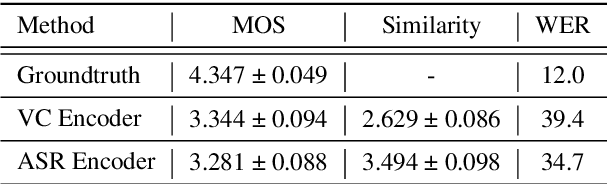
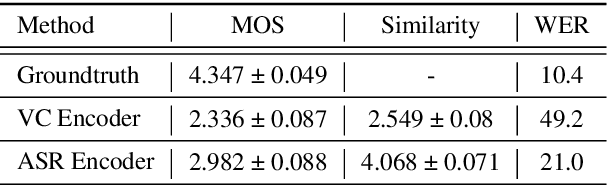
Automatic speech recognition (ASR) needs to be robust to speaker differences. Voice Conversion (VC) modifies speaker characteristics of input speech. This is an attractive feature for ASR data augmentation. In this paper, we demonstrate that voice conversion can be used as a data augmentation technique to improve ASR performance, even on LibriSpeech, which contains 2,456 speakers. For ASR augmentation, it is necessary that the VC model be robust to a wide range of input speech. This motivates the use of a non-autoregressive, non-parallel VC model, and the use of a pretrained ASR encoder within the VC model. This work suggests that despite including many speakers, speaker diversity may remain a limitation to ASR quality. Finally, interrogation of our VC performance has provided useful metrics for objective evaluation of VC quality.
Language-agnostic Multilingual Modeling
Apr 20, 2020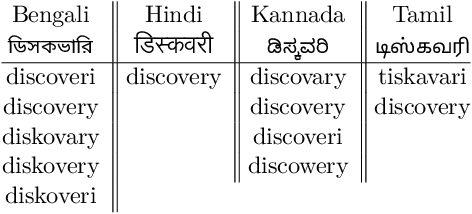
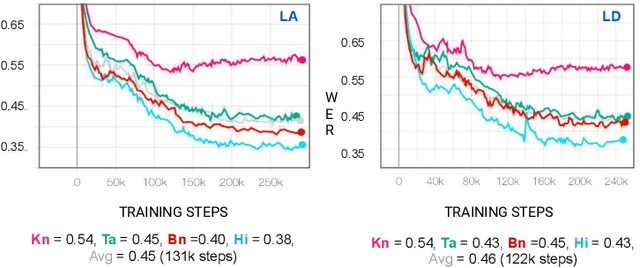
Multilingual Automated Speech Recognition (ASR) systems allow for the joint training of data-rich and data-scarce languages in a single model. This enables data and parameter sharing across languages, which is especially beneficial for the data-scarce languages. However, most state-of-the-art multilingual models require the encoding of language information and therefore are not as flexible or scalable when expanding to newer languages. Language-independent multilingual models help to address this issue, and are also better suited for multicultural societies where several languages are frequently used together (but often rendered with different writing systems). In this paper, we propose a new approach to building a language-agnostic multilingual ASR system which transforms all languages to one writing system through a many-to-one transliteration transducer. Thus, similar sounding acoustics are mapped to a single, canonical target sequence of graphemes, effectively separating the modeling and rendering problems. We show with four Indic languages, namely, Hindi, Bengali, Tamil and Kannada, that the language-agnostic multilingual model achieves up to 10% relative reduction in Word Error Rate (WER) over a language-dependent multilingual model.