 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Speech Prefix-Tuning with RNNT Loss for Improving LLM Predictions
Jun 20, 2024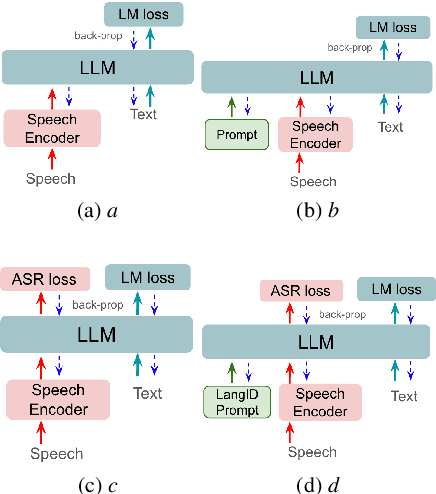



In this paper, we focus on addressing the constraints faced when applying LLMs to ASR. Recent works utilize prefixLM-type models, which directly apply speech as a prefix to LLMs for ASR. We have found that optimizing speech prefixes leads to better ASR performance and propose applying RNNT loss to perform speech prefix-tuning. This is a simple approach and does not increase the model complexity or alter the inference pipeline. We also propose language-based soft prompting to further improve with frozen LLMs. Empirical analysis on realtime testset from 10 Indic languages demonstrate that our proposed speech prefix-tuning yields improvements with both frozen and fine-tuned LLMs. Our recognition results on an average of 10 Indics show that the proposed prefix-tuning with RNNT loss results in a 12\% relative improvement in WER over the baseline with a fine-tuned LLM. Our proposed approches with the frozen LLM leads to a 31\% relative improvement over basic soft-prompting prefixLM.
Text Injection for Neural Contextual Biasing
Jun 05, 2024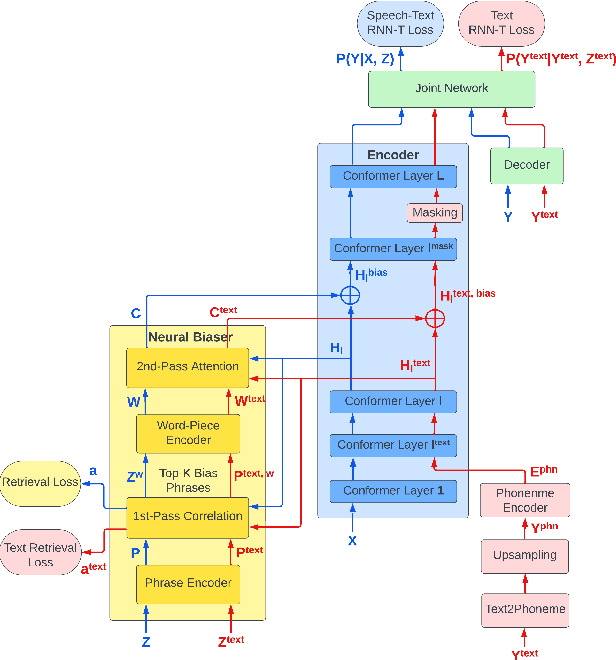
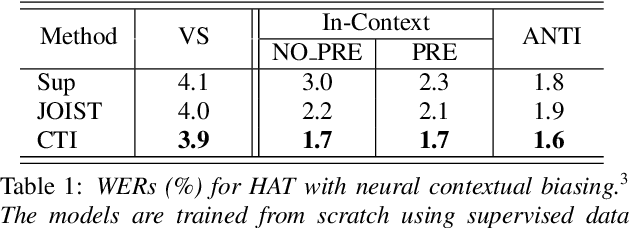
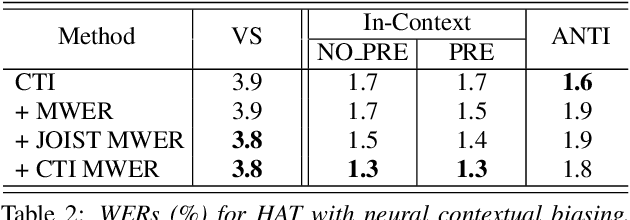
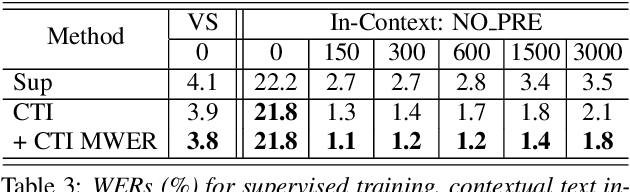
Neural contextual biasing effectively improves automatic speech recognition (ASR) for crucial phrases within a speaker's context, particularly those that are infrequent in the training data. This work proposes contextual text injection (CTI) to enhance contextual ASR. CTI leverages not only the paired speech-text data, but also a much larger corpus of unpaired text to optimize the ASR model and its biasing component. Unpaired text is converted into speech-like representations and used to guide the model's attention towards relevant bias phrases. Moreover, we introduce a contextual text-injected (CTI) minimum word error rate (MWER) training, which minimizes the expected WER caused by contextual biasing when unpaired text is injected into the model. Experiments show that CTI with 100 billion text sentences can achieve up to 43.3% relative WER reduction from a strong neural biasing model. CTI-MWER provides a further relative improvement of 23.5%.
* 5 pages, 1 figure
Efficiently Train ASR Models that Memorize Less and Perform Better with Per-core Clipping
Jun 04, 2024Gradient clipping plays a vital role in training large-scale automatic speech recognition (ASR) models. It is typically applied to minibatch gradients to prevent gradient explosion, and to the individual sample gradients to mitigate unintended memorization. This work systematically investigates the impact of a specific granularity of gradient clipping, namely per-core clip-ping (PCC), across training a wide range of ASR models. We empirically demonstrate that PCC can effectively mitigate unintended memorization in ASR models. Surprisingly, we find that PCC positively influences ASR performance metrics, leading to improved convergence rates and reduced word error rates. To avoid tuning the additional hyperparameter introduced by PCC, we further propose a novel variant, adaptive per-core clipping (APCC), for streamlined optimization. Our findings highlight the multifaceted benefits of PCC as a strategy for robust, privacy-forward ASR model training.
Deferred NAM: Low-latency Top-K Context Injection via DeferredContext Encoding for Non-Streaming ASR
Apr 15, 2024



Contextual biasing enables speech recognizers to transcribe important phrases in the speaker's context, such as contact names, even if they are rare in, or absent from, the training data. Attention-based biasing is a leading approach which allows for full end-to-end cotraining of the recognizer and biasing system and requires no separate inference-time components. Such biasers typically consist of a context encoder; followed by a context filter which narrows down the context to apply, improving per-step inference time; and, finally, context application via cross attention. Though much work has gone into optimizing per-frame performance, the context encoder is at least as important: recognition cannot begin before context encoding ends. Here, we show the lightweight phrase selection pass can be moved before context encoding, resulting in a speedup of up to 16.1 times and enabling biasing to scale to 20K phrases with a maximum pre-decoding delay under 33ms. With the addition of phrase- and wordpiece-level cross-entropy losses, our technique also achieves up to a 37.5% relative WER reduction over the baseline without the losses and lightweight phrase selection pass.
* 9 pages, 3 figures, accepted by NAACL 2024 - Industry Track
Extreme Encoder Output Frame Rate Reduction: Improving Computational Latencies of Large End-to-End Models
Feb 27, 2024The accuracy of end-to-end (E2E) automatic speech recognition (ASR) models continues to improve as they are scaled to larger sizes, with some now reaching billions of parameters. Widespread deployment and adoption of these models, however, requires computationally efficient strategies for decoding. In the present work, we study one such strategy: applying multiple frame reduction layers in the encoder to compress encoder outputs into a small number of output frames. While similar techniques have been investigated in previous work, we achieve dramatically more reduction than has previously been demonstrated through the use of multiple funnel reduction layers. Through ablations, we study the impact of various architectural choices in the encoder to identify the most effective strategies. We demonstrate that we can generate one encoder output frame for every 2.56 sec of input speech, without significantly affecting word error rate on a large-scale voice search task, while improving encoder and decoder latencies by 48% and 92% respectively, relative to a strong but computationally expensive baseline.
SLM: Bridge the thin gap between speech and text foundation models
Sep 30, 2023



We present a joint Speech and Language Model (SLM), a multitask, multilingual, and dual-modal model that takes advantage of pretrained foundational speech and language models. SLM freezes the pretrained foundation models to maximally preserves their capabilities, and only trains a simple adapter with just 1\% (156M) of the foundation models' parameters. This adaptation not only leads SLM to achieve strong performance on conventional tasks such as speech recognition (ASR) and speech translation (AST), but also introduces the novel capability of zero-shot instruction-following for more diverse tasks: given a speech input and a text instruction, SLM is able to perform unseen generation tasks including contextual biasing ASR using real-time context, dialog generation, speech continuation, and question answering, etc. Our approach demonstrates that the representational gap between pretrained speech and language models might be narrower than one would expect, and can be bridged by a simple adaptation mechanism. As a result, SLM is not only efficient to train, but also inherits strong capabilities already acquired in foundation models of different modalities.
Contextual Biasing with the Knuth-Morris-Pratt Matching Algorithm
Sep 29, 2023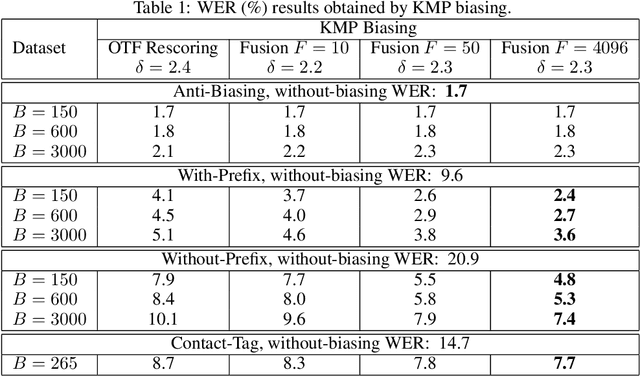
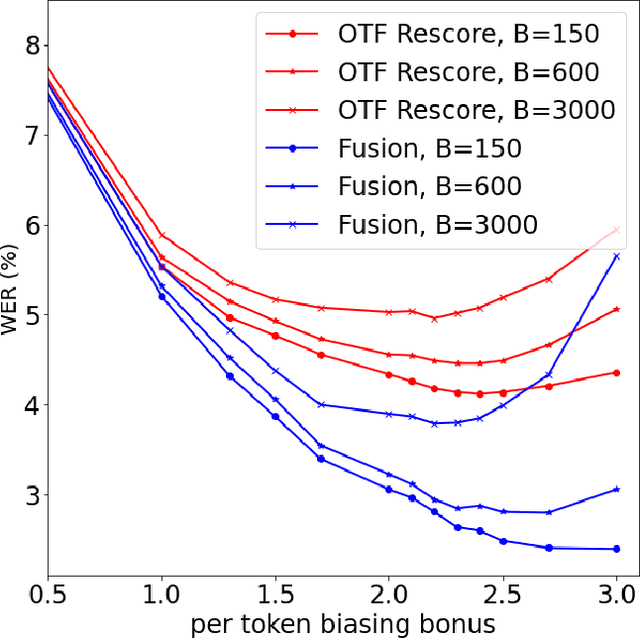
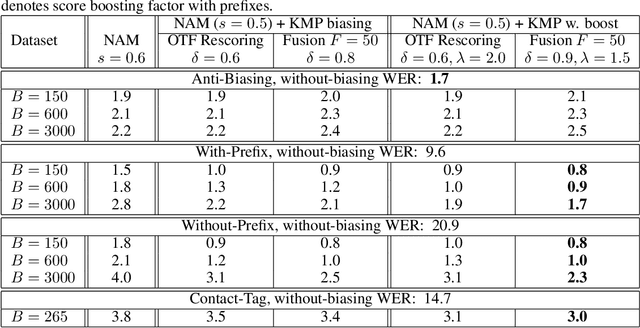
Contextual biasing refers to the problem of biasing the automatic speech recognition (ASR) systems towards rare entities that are relevant to the specific user or application scenarios. We propose algorithms for contextual biasing based on the Knuth-Morris-Pratt algorithm for pattern matching. During beam search, we boost the score of a token extension if it extends matching into a set of biasing phrases. Our method simulates the classical approaches often implemented in the weighted finite state transducer (WFST) framework, but avoids the FST language altogether, with careful considerations on memory footprint and efficiency on tensor processing units (TPUs) by vectorization. Without introducing additional model parameters, our method achieves significant word error rate (WER) reductions on biasing test sets by itself, and yields further performance gain when combined with a model-based biasing method.
Massive End-to-end Models for Short Search Queries
Sep 22, 2023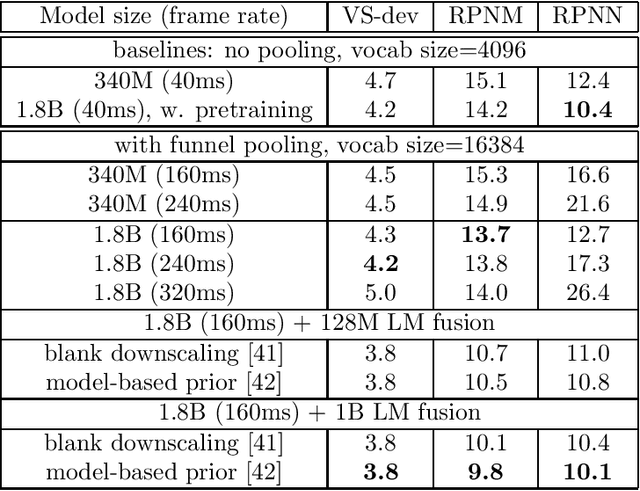
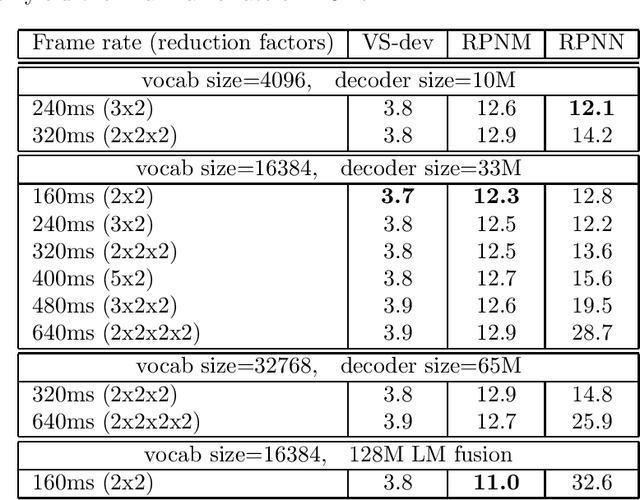
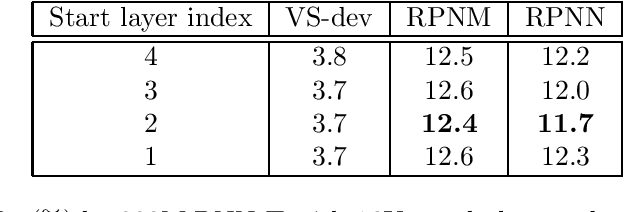
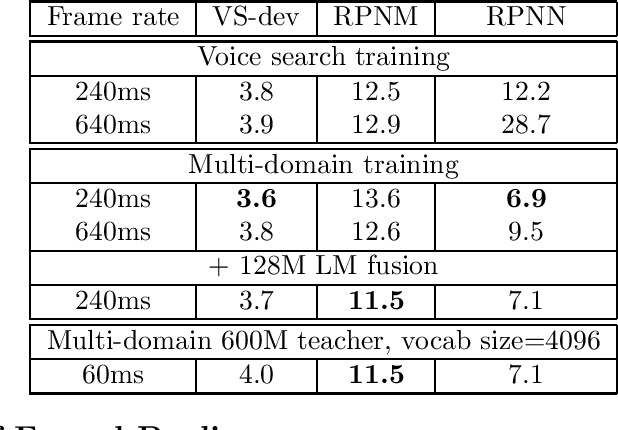
In this work, we investigate two popular end-to-end automatic speech recognition (ASR) models, namely Connectionist Temporal Classification (CTC) and RNN-Transducer (RNN-T), for offline recognition of voice search queries, with up to 2B model parameters. The encoders of our models use the neural architecture of Google's universal speech model (USM), with additional funnel pooling layers to significantly reduce the frame rate and speed up training and inference. We perform extensive studies on vocabulary size, time reduction strategy, and its generalization performance on long-form test sets. Despite the speculation that, as the model size increases, CTC can be as good as RNN-T which builds label dependency into the prediction, we observe that a 900M RNN-T clearly outperforms a 1.8B CTC and is more tolerant to severe time reduction, although the WER gap can be largely removed by LM shallow fusion.
Augmenting conformers with structured state space models for online speech recognition
Sep 15, 2023
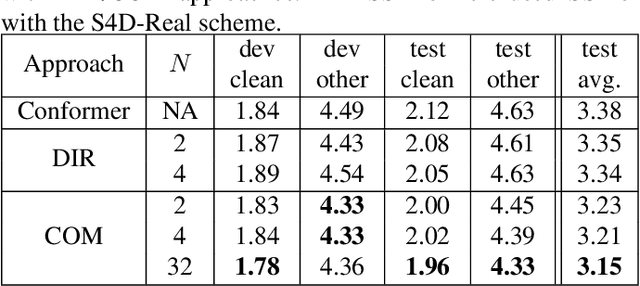
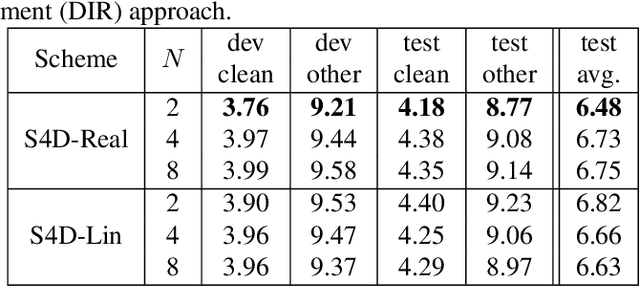
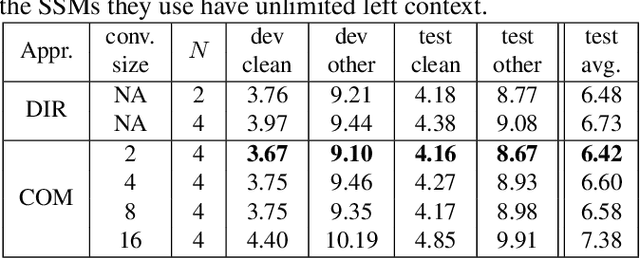
Online speech recognition, where the model only accesses context to the left, is an important and challenging use case for ASR systems. In this work, we investigate augmenting neural encoders for online ASR by incorporating structured state-space sequence models (S4), which are a family of models that provide a parameter-efficient way of accessing arbitrarily long left context. We perform systematic ablation studies to compare variants of S4 models and propose two novel approaches that combine them with convolutions. We find that the most effective design is to stack a small S4 using real-valued recurrent weights with a local convolution, allowing them to work complementarily. Our best model achieves WERs of 4.01%/8.53% on test sets from Librispeech, outperforming Conformers with extensively tuned convolution.