 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Dropout for Pruning Conformers
Dec 06, 2024


This paper proposes a method to effectively perform joint training-and-pruning based on adaptive dropout layers with unit-wise retention probabilities. The proposed method is based on the estimation of a unit-wise retention probability in a dropout layer. A unit that is estimated to have a small retention probability can be considered to be prunable. The retention probability of the unit is estimated using back-propagation and the Gumbel-Softmax technique. This pruning method is applied at several application points in Conformers such that the effective number of parameters can be significantly reduced. Specifically, adaptive dropout layers are introduced in three locations in each Conformer block: (a) the hidden layer of the feed-forward-net component, (b) the query vectors and the value vectors of the self-attention component, and (c) the input vectors of the LConv component. The proposed method is evaluated by conducting a speech recognition experiment on the LibriSpeech task. It was shown that this approach could simultaneously achieve a parameter reduction and accuracy improvement. The word error rates improved by approx 1% while reducing the number of parameters by 54%.
Extreme Encoder Output Frame Rate Reduction: Improving Computational Latencies of Large End-to-End Models
Feb 27, 2024The accuracy of end-to-end (E2E) automatic speech recognition (ASR) models continues to improve as they are scaled to larger sizes, with some now reaching billions of parameters. Widespread deployment and adoption of these models, however, requires computationally efficient strategies for decoding. In the present work, we study one such strategy: applying multiple frame reduction layers in the encoder to compress encoder outputs into a small number of output frames. While similar techniques have been investigated in previous work, we achieve dramatically more reduction than has previously been demonstrated through the use of multiple funnel reduction layers. Through ablations, we study the impact of various architectural choices in the encoder to identify the most effective strategies. We demonstrate that we can generate one encoder output frame for every 2.56 sec of input speech, without significantly affecting word error rate on a large-scale voice search task, while improving encoder and decoder latencies by 48% and 92% respectively, relative to a strong but computationally expensive baseline.
Massive End-to-end Models for Short Search Queries
Sep 22, 2023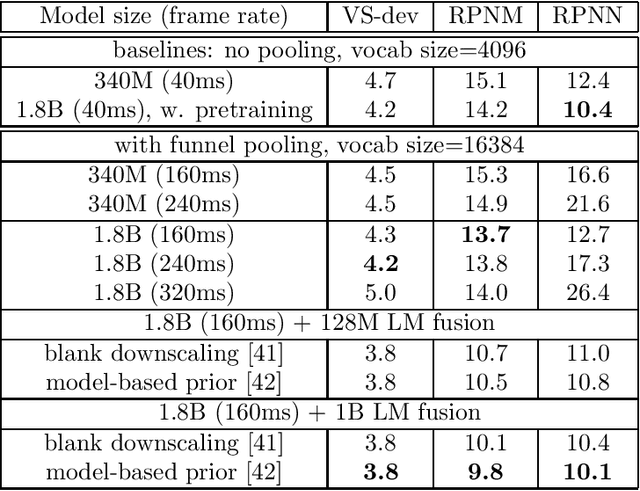
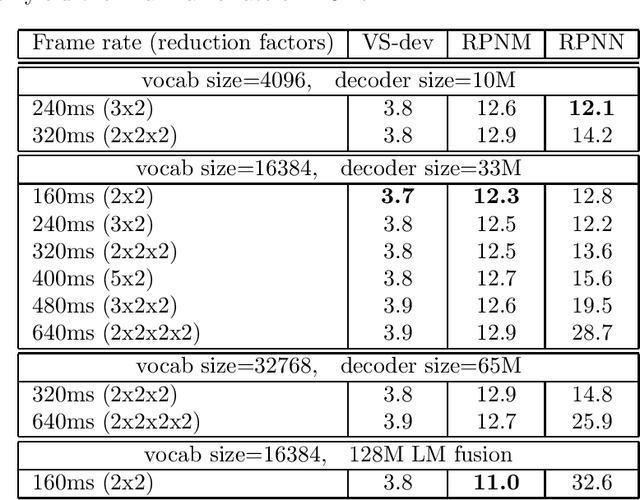
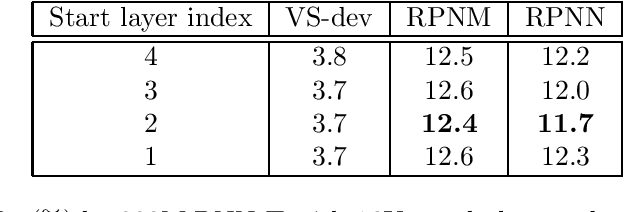
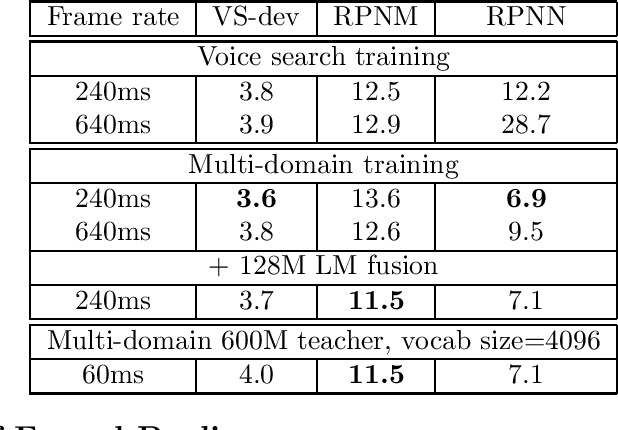
In this work, we investigate two popular end-to-end automatic speech recognition (ASR) models, namely Connectionist Temporal Classification (CTC) and RNN-Transducer (RNN-T), for offline recognition of voice search queries, with up to 2B model parameters. The encoders of our models use the neural architecture of Google's universal speech model (USM), with additional funnel pooling layers to significantly reduce the frame rate and speed up training and inference. We perform extensive studies on vocabulary size, time reduction strategy, and its generalization performance on long-form test sets. Despite the speculation that, as the model size increases, CTC can be as good as RNN-T which builds label dependency into the prediction, we observe that a 900M RNN-T clearly outperforms a 1.8B CTC and is more tolerant to severe time reduction, although the WER gap can be largely removed by LM shallow fusion.
Data-Driven Adaptive Simultaneous Machine Translation
Apr 27, 2022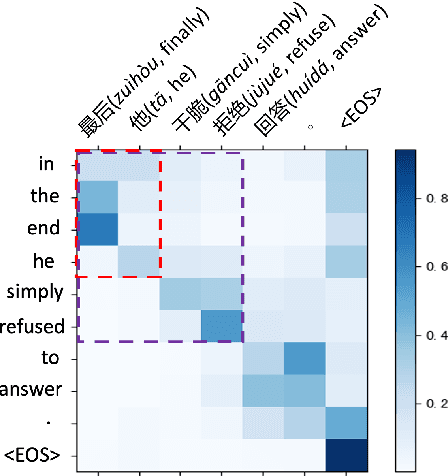
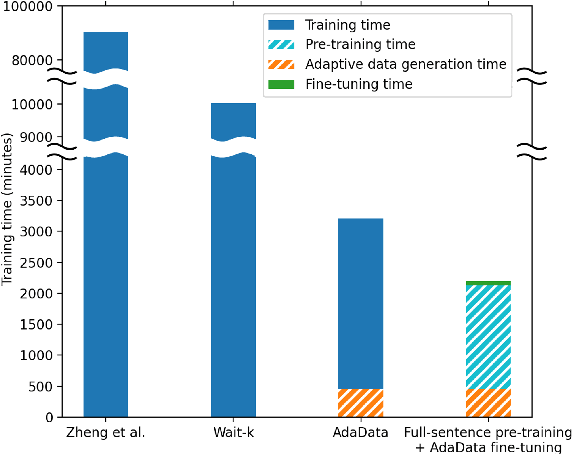
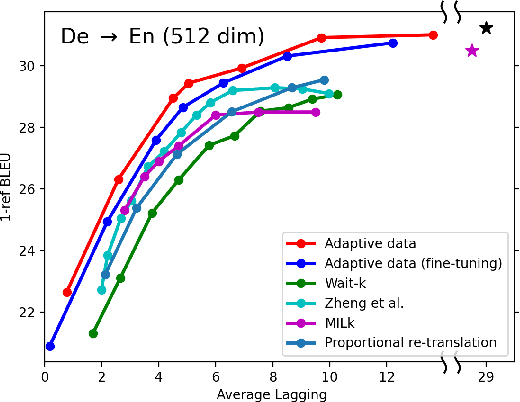
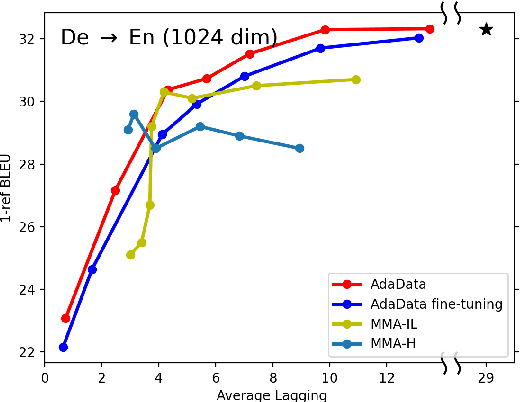
In simultaneous translation (SimulMT), the most widely used strategy is the wait-k policy thanks to its simplicity and effectiveness in balancing translation quality and latency. However, wait-k suffers from two major limitations: (a) it is a fixed policy that can not adaptively adjust latency given context, and (b) its training is much slower than full-sentence translation. To alleviate these issues, we propose a novel and efficient training scheme for adaptive SimulMT by augmenting the training corpus with adaptive prefix-to-prefix pairs, while the training complexity remains the same as that of training full-sentence translation models. Experiments on two language pairs show that our method outperforms all strong baselines in terms of translation quality and latency.
Automatic recognition of suprasegmentals in speech
Aug 04, 2021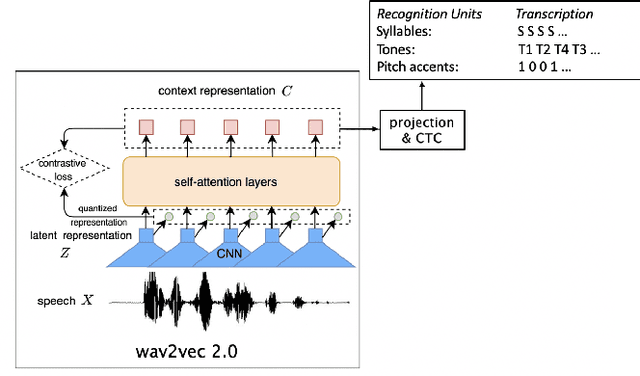
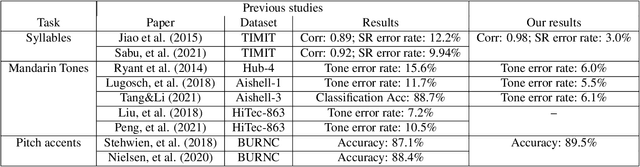
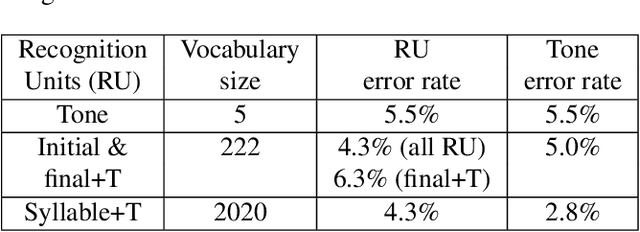
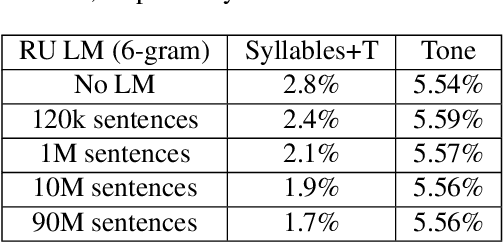
This study reports our efforts to improve automatic recognition of suprasegmentals by fine-tuning wav2vec 2.0 with CTC, a method that has been successful in automatic speech recognition. We demonstrate that the method can improve the state-of-the-art on automatic recognition of syllables, tones, and pitch accents. Utilizing segmental information, by employing tonal finals or tonal syllables as recognition units, can significantly improve Mandarin tone recognition. Language models are helpful when tonal syllables are used as recognition units, but not helpful when tones are recognition units. Finally, Mandarin tone recognition can benefit from English phoneme recognition by combining the two tasks in fine-tuning wav2vec 2.0.
The Role of Phonetic Units in Speech Emotion Recognition
Aug 02, 2021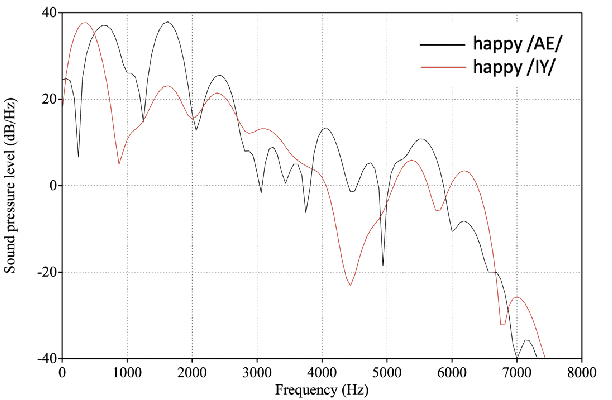
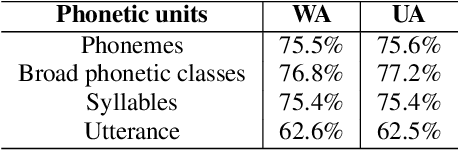
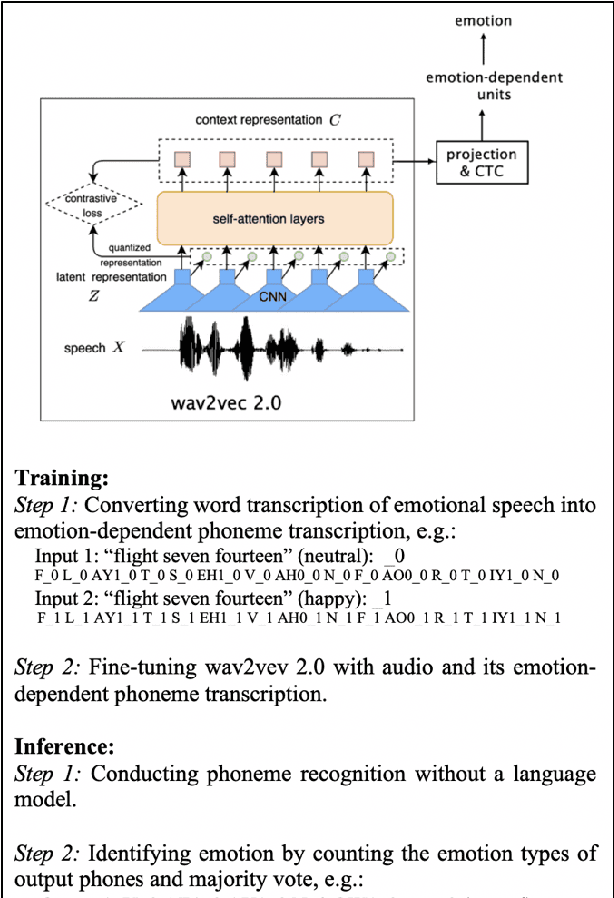
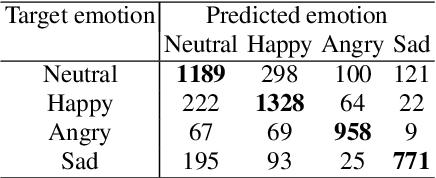
We propose a method for emotion recognition through emotiondependent speech recognition using Wav2vec 2.0. Our method achieved a significant improvement over most previously reported results on IEMOCAP, a benchmark emotion dataset. Different types of phonetic units are employed and compared in terms of accuracy and robustness of emotion recognition within and across datasets and languages. Models of phonemes, broad phonetic classes, and syllables all significantly outperform the utterance model, demonstrating that phonetic units are helpful and should be incorporated in speech emotion recognition. The best performance is from using broad phonetic classes. Further research is needed to investigate the optimal set of broad phonetic classes for the task of emotion recognition. Finally, we found that Wav2vec 2.0 can be fine-tuned to recognize coarser-grained or larger phonetic units than phonemes, such as broad phonetic classes and syllables.
Decoupling recognition and transcription in Mandarin ASR
Aug 02, 2021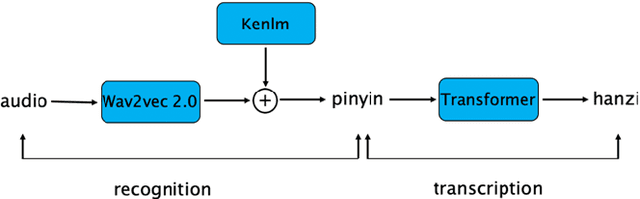
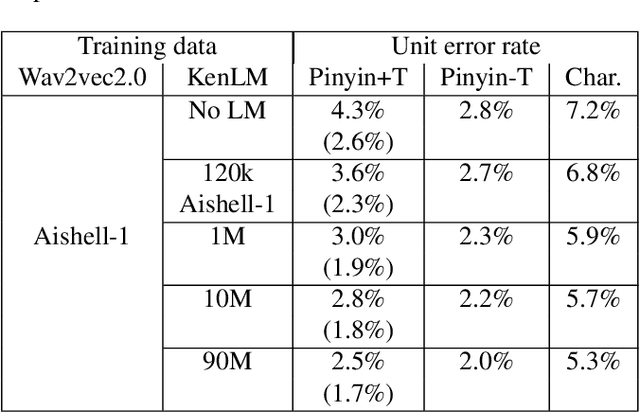
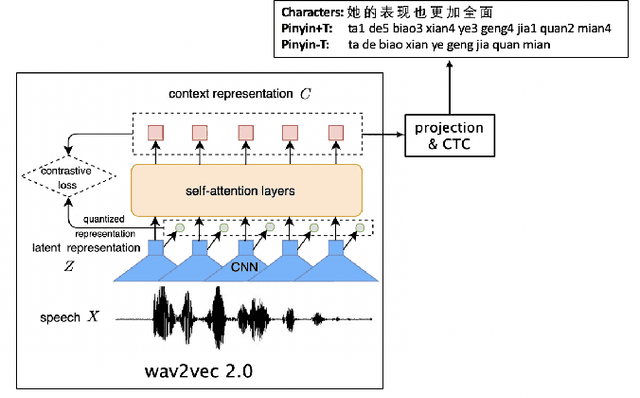
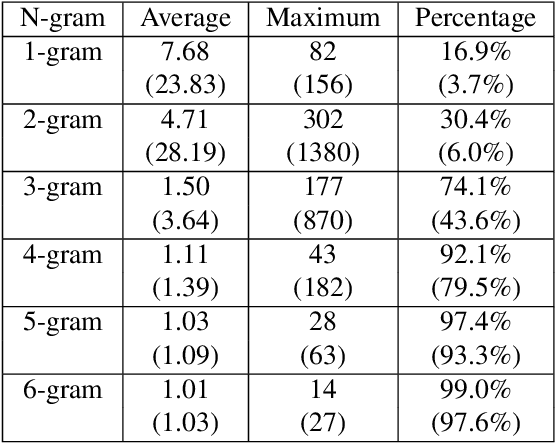
Much of the recent literature on automatic speech recognition (ASR) is taking an end-to-end approach. Unlike English where the writing system is closely related to sound, Chinese characters (Hanzi) represent meaning, not sound. We propose factoring audio -> Hanzi into two sub-tasks: (1) audio -> Pinyin and (2) Pinyin -> Hanzi, where Pinyin is a system of phonetic transcription of standard Chinese. Factoring the audio -> Hanzi task in this way achieves 3.9% CER (character error rate) on the Aishell-1 corpus, the best result reported on this dataset so far.
Better than BERT but Worse than Baseline
May 12, 2021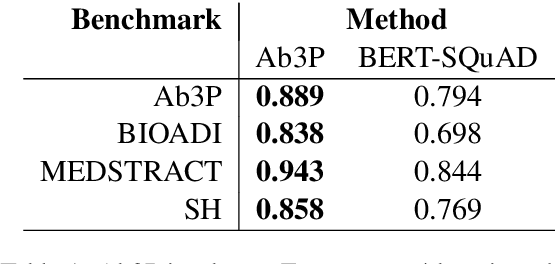
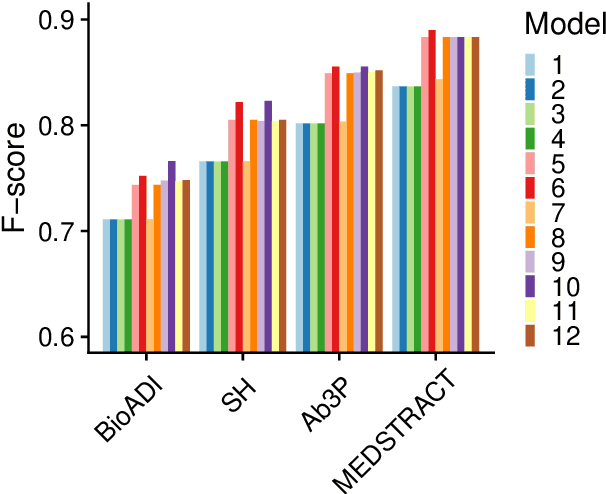
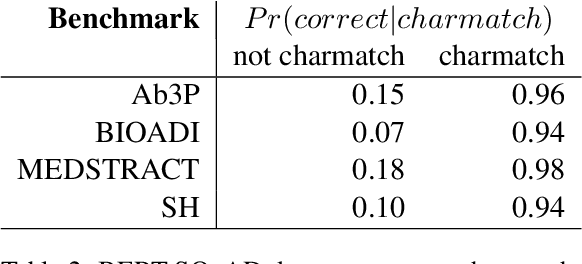
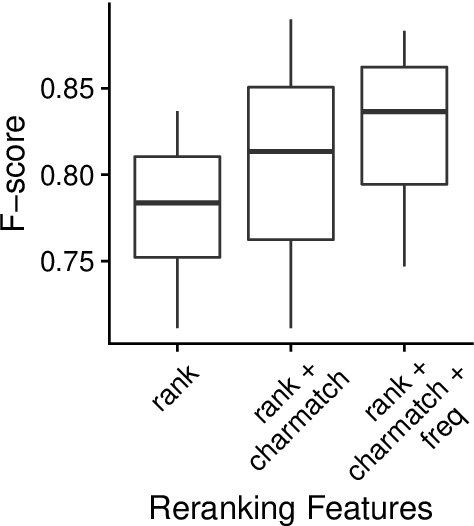
This paper compares BERT-SQuAD and Ab3P on the Abbreviation Definition Identification (ADI) task. ADI inputs a text and outputs short forms (abbreviations/acronyms) and long forms (expansions). BERT with reranking improves over BERT without reranking but fails to reach the Ab3P rule-based baseline. What is BERT missing? Reranking introduces two new features: charmatch and freq. The first feature identifies opportunities to take advantage of character constraints in acronyms and the second feature identifies opportunities to take advantage of frequency constraints across documents.