 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFAdam: Adam is a natural gradient optimizer using diagonal empirical Fisher information
May 23, 2024This paper establishes a mathematical foundation for the Adam optimizer, elucidating its connection to natural gradient descent through Riemannian and information geometry. We rigorously analyze the diagonal empirical Fisher information matrix (FIM) in Adam, clarifying all detailed approximations and advocating for the use of log probability functions as loss, which should be based on discrete distributions, due to the limitations of empirical FIM. Our analysis uncovers flaws in the original Adam algorithm, leading to proposed corrections such as enhanced momentum calculations, adjusted bias corrections, adaptive epsilon, and gradient clipping. We refine the weight decay term based on our theoretical framework. Our modified algorithm, Fisher Adam (FAdam), demonstrates superior performance across diverse domains including LLM, ASR, and VQ-VAE, achieving state-of-the-art results in ASR.
TransformerFAM: Feedback attention is working memory
Apr 14, 2024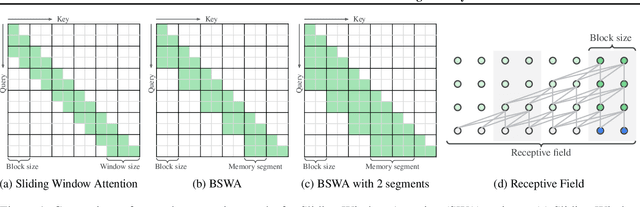
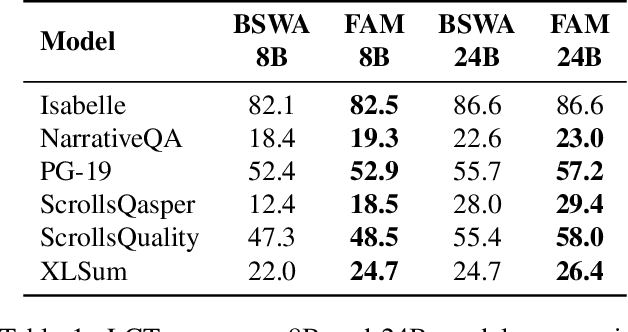

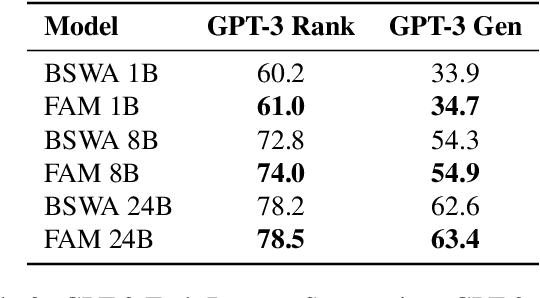
While Transformers have revolutionized deep learning, their quadratic attention complexity hinders their ability to process infinitely long inputs. We propose Feedback Attention Memory (FAM), a novel Transformer architecture that leverages a feedback loop to enable the network to attend to its own latent representations. This design fosters the emergence of working memory within the Transformer, allowing it to process indefinitely long sequences. TransformerFAM requires no additional weights, enabling seamless integration with pre-trained models. Our experiments show that TransformerFAM significantly improves Transformer performance on long-context tasks across various model sizes (1B, 8B, and 24B). These results showcase the potential to empower Large Language Models (LLMs) to process sequences of unlimited length.
Extreme Encoder Output Frame Rate Reduction: Improving Computational Latencies of Large End-to-End Models
Feb 27, 2024The accuracy of end-to-end (E2E) automatic speech recognition (ASR) models continues to improve as they are scaled to larger sizes, with some now reaching billions of parameters. Widespread deployment and adoption of these models, however, requires computationally efficient strategies for decoding. In the present work, we study one such strategy: applying multiple frame reduction layers in the encoder to compress encoder outputs into a small number of output frames. While similar techniques have been investigated in previous work, we achieve dramatically more reduction than has previously been demonstrated through the use of multiple funnel reduction layers. Through ablations, we study the impact of various architectural choices in the encoder to identify the most effective strategies. We demonstrate that we can generate one encoder output frame for every 2.56 sec of input speech, without significantly affecting word error rate on a large-scale voice search task, while improving encoder and decoder latencies by 48% and 92% respectively, relative to a strong but computationally expensive baseline.
Revisiting the Entropy Semiring for Neural Speech Recognition
Dec 19, 2023



In streaming settings, speech recognition models have to map sub-sequences of speech to text before the full audio stream becomes available. However, since alignment information between speech and text is rarely available during training, models need to learn it in a completely self-supervised way. In practice, the exponential number of possible alignments makes this extremely challenging, with models often learning peaky or sub-optimal alignments. Prima facie, the exponential nature of the alignment space makes it difficult to even quantify the uncertainty of a model's alignment distribution. Fortunately, it has been known for decades that the entropy of a probabilistic finite state transducer can be computed in time linear to the size of the transducer via a dynamic programming reduction based on semirings. In this work, we revisit the entropy semiring for neural speech recognition models, and show how alignment entropy can be used to supervise models through regularization or distillation. We also contribute an open-source implementation of CTC and RNN-T in the semiring framework that includes numerically stable and highly parallel variants of the entropy semiring. Empirically, we observe that the addition of alignment distillation improves the accuracy and latency of an already well-optimized teacher-student distillation model, achieving state-of-the-art performance on the Librispeech dataset in the streaming scenario.
Massive End-to-end Models for Short Search Queries
Sep 22, 2023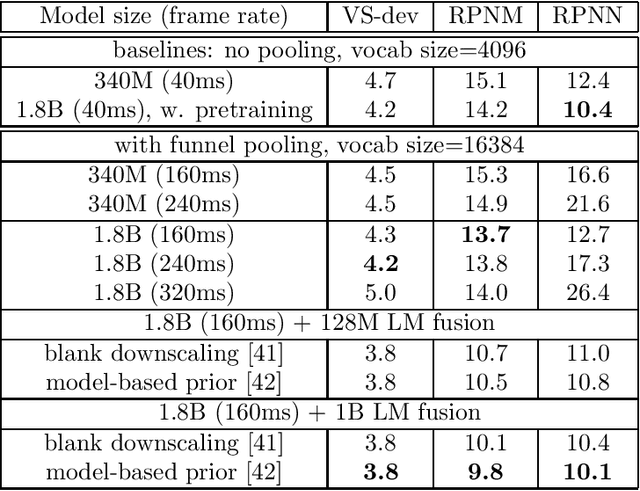
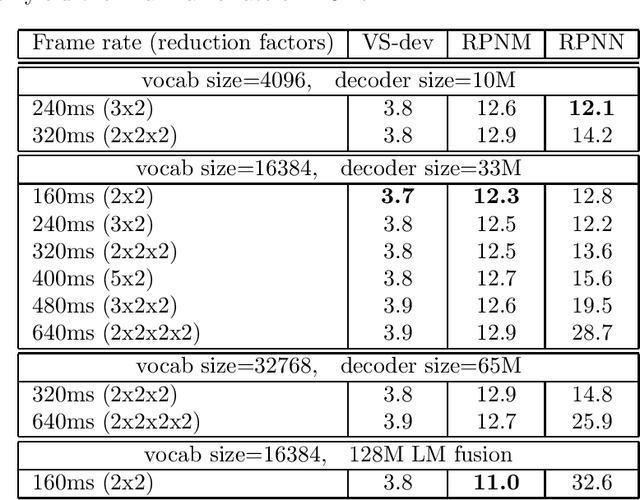
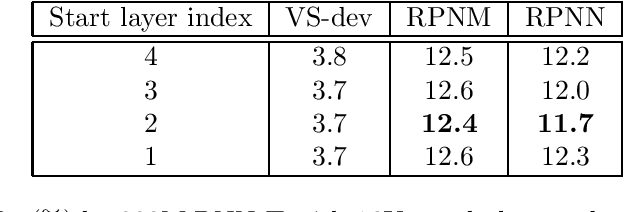
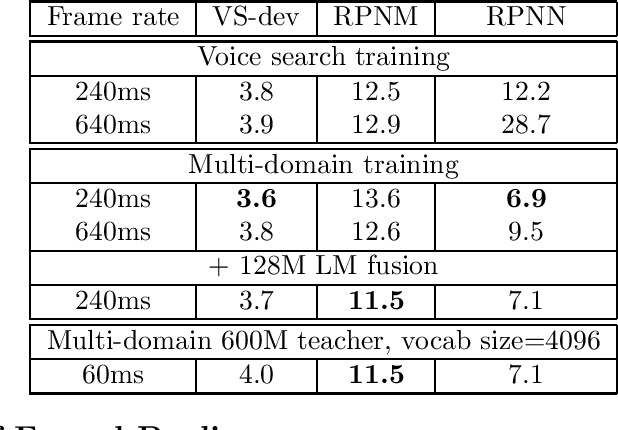
In this work, we investigate two popular end-to-end automatic speech recognition (ASR) models, namely Connectionist Temporal Classification (CTC) and RNN-Transducer (RNN-T), for offline recognition of voice search queries, with up to 2B model parameters. The encoders of our models use the neural architecture of Google's universal speech model (USM), with additional funnel pooling layers to significantly reduce the frame rate and speed up training and inference. We perform extensive studies on vocabulary size, time reduction strategy, and its generalization performance on long-form test sets. Despite the speculation that, as the model size increases, CTC can be as good as RNN-T which builds label dependency into the prediction, we observe that a 900M RNN-T clearly outperforms a 1.8B CTC and is more tolerant to severe time reduction, although the WER gap can be largely removed by LM shallow fusion.
Improving Speech Recognition for African American English With Audio Classification
Sep 16, 2023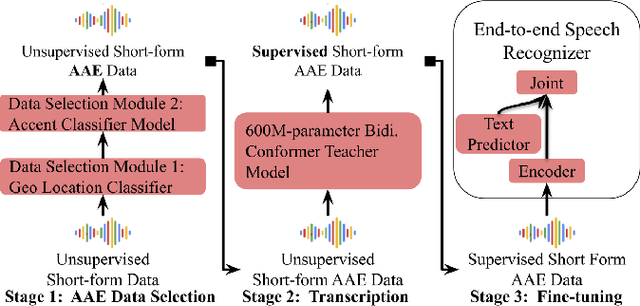
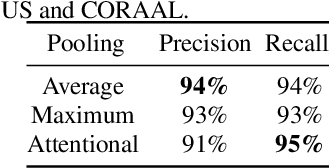

Automatic speech recognition (ASR) systems have been shown to have large quality disparities between the language varieties they are intended or expected to recognize. One way to mitigate this is to train or fine-tune models with more representative datasets. But this approach can be hindered by limited in-domain data for training and evaluation. We propose a new way to improve the robustness of a US English short-form speech recognizer using a small amount of out-of-domain (long-form) African American English (AAE) data. We use CORAAL, YouTube and Mozilla Common Voice to train an audio classifier to approximately output whether an utterance is AAE or some other variety including Mainstream American English (MAE). By combining the classifier output with coarse geographic information, we can select a subset of utterances from a large corpus of untranscribed short-form queries for semi-supervised learning at scale. Fine-tuning on this data results in a 38.5% relative word error rate disparity reduction between AAE and MAE without reducing MAE quality.
Edit Distance based RL for RNNT decoding
May 31, 2023RNN-T is currently considered the industry standard in ASR due to its exceptional WERs in various benchmark tests and its ability to support seamless streaming and longform transcription. However, its biggest drawback lies in the significant discrepancy between its training and inference objectives. During training, RNN-T maximizes all alignment probabilities by teacher forcing, while during inference, it uses beam search which may not necessarily find the maximum probable alignment. Additionally, RNN-T's inability to experience mistakes during teacher forcing training makes it more problematic when a mistake occurs in inference. To address this issue, this paper proposes a Reinforcement Learning method that minimizes the gap between training and inference time. Our Edit Distance based RL (EDRL) approach computes rewards based on the edit distance, and trains the network at every action level. The proposed approach yielded SoTA WERs on LibriSpeech for the 600M Conformer RNN-T model.
Modular Domain Adaptation for Conformer-Based Streaming ASR
May 22, 2023Speech data from different domains has distinct acoustic and linguistic characteristics. It is common to train a single multidomain model such as a Conformer transducer for speech recognition on a mixture of data from all domains. However, changing data in one domain or adding a new domain would require the multidomain model to be retrained. To this end, we propose a framework called modular domain adaptation (MDA) that enables a single model to process multidomain data while keeping all parameters domain-specific, i.e., each parameter is only trained by data from one domain. On a streaming Conformer transducer trained only on video caption data, experimental results show that an MDA-based model can reach similar performance as the multidomain model on other domains such as voice search and dictation by adding per-domain adapters and per-domain feed-forward networks in the Conformer encoder.
Efficient Domain Adaptation for Speech Foundation Models
Feb 03, 2023Foundation models (FMs), that are trained on broad data at scale and are adaptable to a wide range of downstream tasks, have brought large interest in the research community. Benefiting from the diverse data sources such as different modalities, languages and application domains, foundation models have demonstrated strong generalization and knowledge transfer capabilities. In this paper, we present a pioneering study towards building an efficient solution for FM-based speech recognition systems. We adopt the recently developed self-supervised BEST-RQ for pretraining, and propose the joint finetuning with both source and unsupervised target domain data using JUST Hydra. The FM encoder adapter and decoder are then finetuned to the target domain with a small amount of supervised in-domain data. On a large-scale YouTube and Voice Search task, our method is shown to be both data and model parameter efficient. It achieves the same quality with only 21.6M supervised in-domain data and 130.8M finetuned parameters, compared to the 731.1M model trained from scratch on additional 300M supervised in-domain data.
Resource-Efficient Transfer Learning From Speech Foundation Model Using Hierarchical Feature Fusion
Nov 04, 2022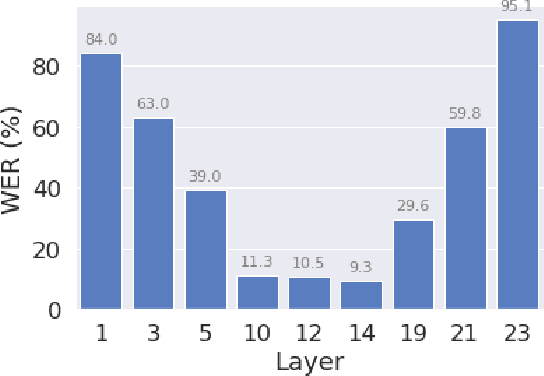
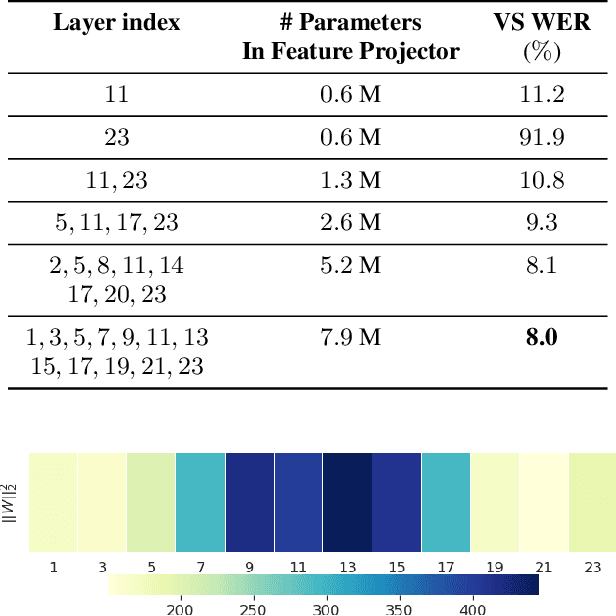
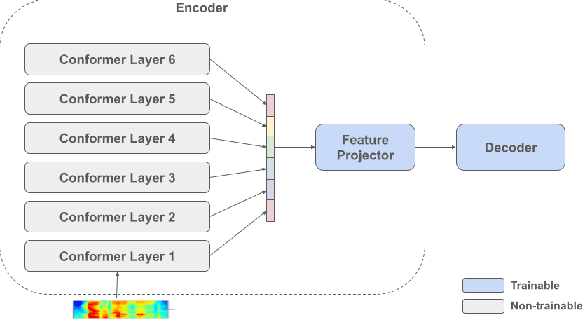
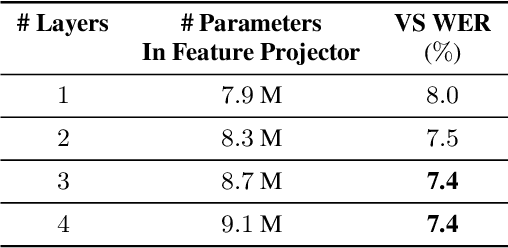
Self-supervised pre-training of a speech foundation model, followed by supervised fine-tuning, has shown impressive quality improvements on automatic speech recognition (ASR) tasks. Fine-tuning separate foundation models for many downstream tasks are expensive since the foundation model is usually very big. Parameter-efficient fine-tuning methods (e.g. adapter, sparse update methods) offer an alternative paradigm where a small set of parameters are updated to adapt the foundation model to new tasks. However, these methods still suffer from a high computational memory cost and slow training speed because they require backpropagation through the entire neural network at each step. In the paper, we analyze the performance of features at different layers of a foundation model on the speech recognition task and propose a novel hierarchical feature fusion method for resource-efficient transfer learning from speech foundation models. Experimental results show that the proposed method can achieve better performance on speech recognition task than existing algorithms with fewer number of trainable parameters, less computational memory cost and faster training speed. After combining with Adapters at all layers, the proposed method can achieve the same performance as fine-tuning the whole model with $97\%$ fewer trainable encoder parameters and $53\%$ faster training speed.