 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Learning of Large ASR Models in the Real World
Aug 19, 2024Federated learning (FL) has shown promising results on training machine learning models with privacy preservation. However, for large models with over 100 million parameters, the training resource requirement becomes an obstacle for FL because common devices do not have enough memory and computation power to finish the FL tasks. Although efficient training methods have been proposed, it is still a challenge to train the large models like Conformer based ASR. This paper presents a systematic solution to train the full-size ASR models of 130M parameters with FL. To our knowledge, this is the first real-world FL application of the Conformer model, which is also the largest model ever trained with FL so far. And this is the first paper showing FL can improve the ASR model quality with a set of proposed methods to refine the quality of data and labels of clients. We demonstrate both the training efficiency and the model quality improvement in real-world experiments.
Edit Distance based RL for RNNT decoding
May 31, 2023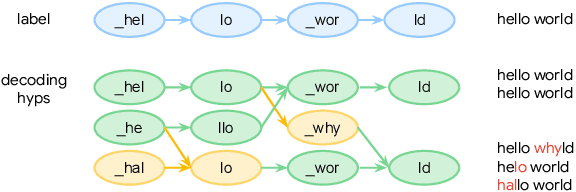


RNN-T is currently considered the industry standard in ASR due to its exceptional WERs in various benchmark tests and its ability to support seamless streaming and longform transcription. However, its biggest drawback lies in the significant discrepancy between its training and inference objectives. During training, RNN-T maximizes all alignment probabilities by teacher forcing, while during inference, it uses beam search which may not necessarily find the maximum probable alignment. Additionally, RNN-T's inability to experience mistakes during teacher forcing training makes it more problematic when a mistake occurs in inference. To address this issue, this paper proposes a Reinforcement Learning method that minimizes the gap between training and inference time. Our Edit Distance based RL (EDRL) approach computes rewards based on the edit distance, and trains the network at every action level. The proposed approach yielded SoTA WERs on LibriSpeech for the 600M Conformer RNN-T model.
Enabling On-Device Training of Speech Recognition Models with Federated Dropout
Oct 07, 2021
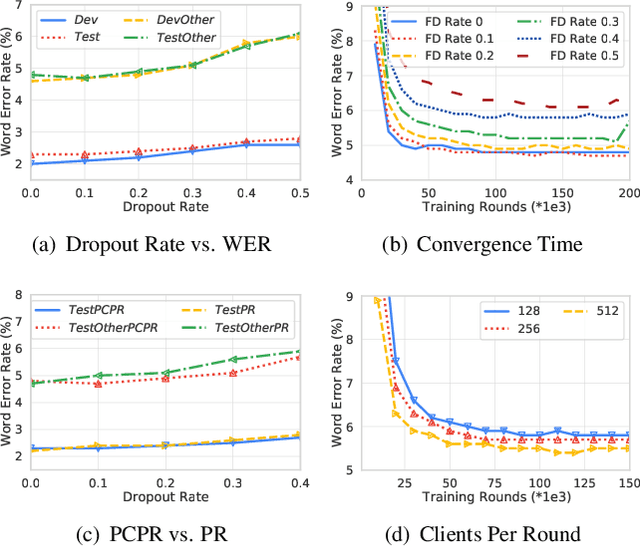

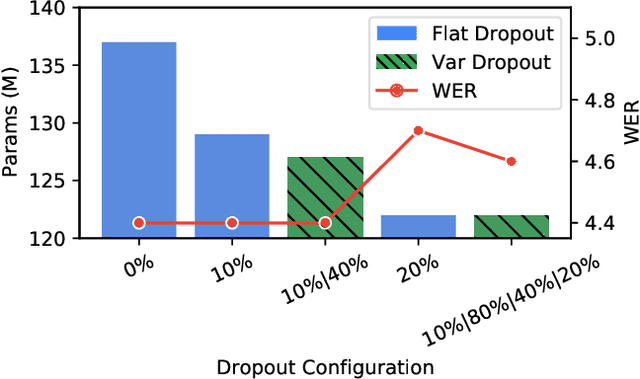
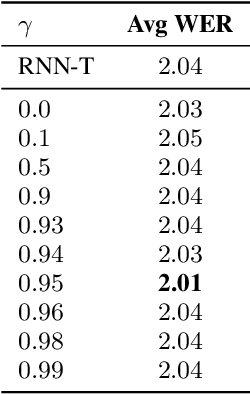
Federated learning can be used to train machine learning models on the edge on local data that never leave devices, providing privacy by default. This presents a challenge pertaining to the communication and computation costs associated with clients' devices. These costs are strongly correlated with the size of the model being trained, and are significant for state-of-the-art automatic speech recognition models. We propose using federated dropout to reduce the size of client models while training a full-size model server-side. We provide empirical evidence of the effectiveness of federated dropout, and propose a novel approach to vary the dropout rate applied at each layer. Furthermore, we find that federated dropout enables a set of smaller sub-models within the larger model to independently have low word error rates, making it easier to dynamically adjust the size of the model deployed for inference.