 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResource-Efficient Transfer Learning From Speech Foundation Model Using Hierarchical Feature Fusion
Paper and Code
Nov 04, 2022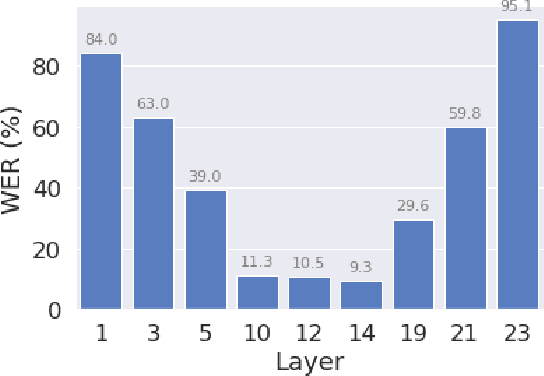
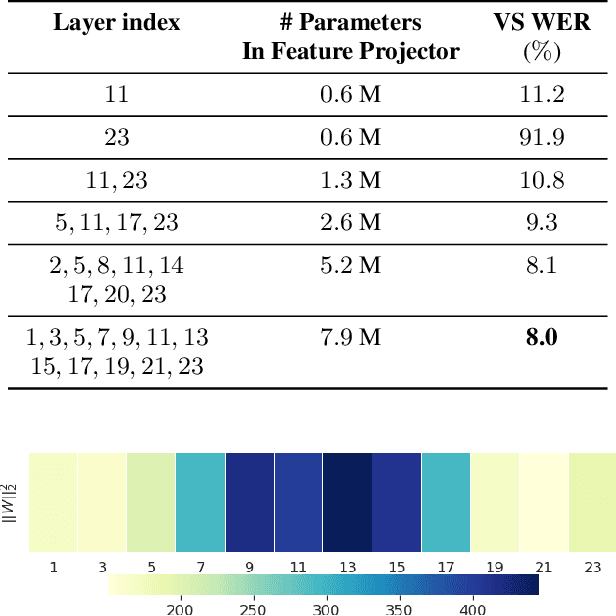
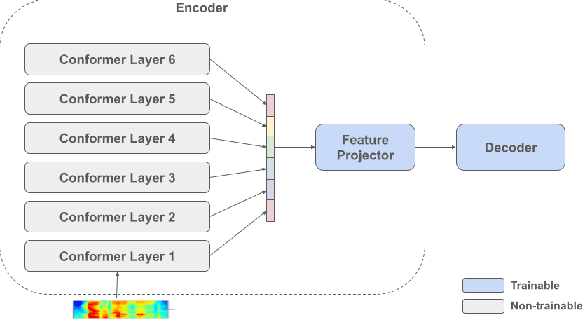
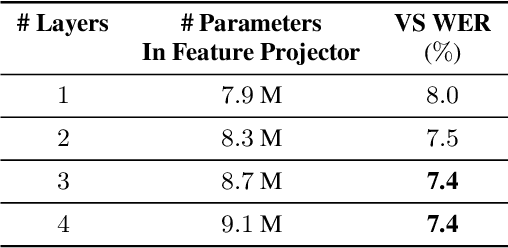
Self-supervised pre-training of a speech foundation model, followed by supervised fine-tuning, has shown impressive quality improvements on automatic speech recognition (ASR) tasks. Fine-tuning separate foundation models for many downstream tasks are expensive since the foundation model is usually very big. Parameter-efficient fine-tuning methods (e.g. adapter, sparse update methods) offer an alternative paradigm where a small set of parameters are updated to adapt the foundation model to new tasks. However, these methods still suffer from a high computational memory cost and slow training speed because they require backpropagation through the entire neural network at each step. In the paper, we analyze the performance of features at different layers of a foundation model on the speech recognition task and propose a novel hierarchical feature fusion method for resource-efficient transfer learning from speech foundation models. Experimental results show that the proposed method can achieve better performance on speech recognition task than existing algorithms with fewer number of trainable parameters, less computational memory cost and faster training speed. After combining with Adapters at all layers, the proposed method can achieve the same performance as fine-tuning the whole model with $97\%$ fewer trainable encoder parameters and $53\%$ faster training speed.