 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText Injection for Neural Contextual Biasing
Jun 05, 2024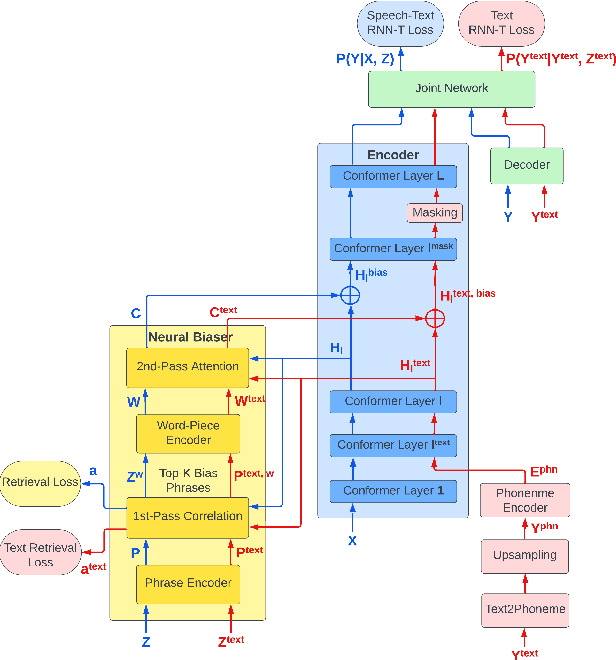
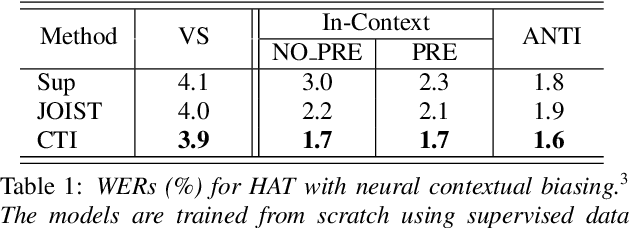
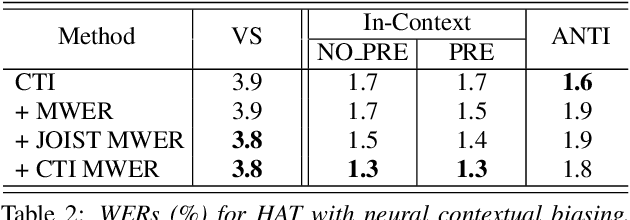
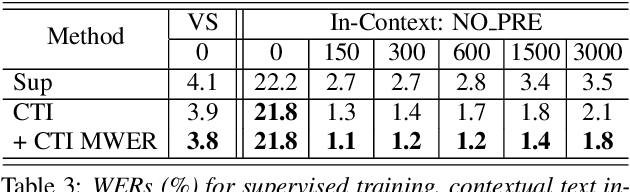
Neural contextual biasing effectively improves automatic speech recognition (ASR) for crucial phrases within a speaker's context, particularly those that are infrequent in the training data. This work proposes contextual text injection (CTI) to enhance contextual ASR. CTI leverages not only the paired speech-text data, but also a much larger corpus of unpaired text to optimize the ASR model and its biasing component. Unpaired text is converted into speech-like representations and used to guide the model's attention towards relevant bias phrases. Moreover, we introduce a contextual text-injected (CTI) minimum word error rate (MWER) training, which minimizes the expected WER caused by contextual biasing when unpaired text is injected into the model. Experiments show that CTI with 100 billion text sentences can achieve up to 43.3% relative WER reduction from a strong neural biasing model. CTI-MWER provides a further relative improvement of 23.5%.
* 5 pages, 1 figure
Extreme Encoder Output Frame Rate Reduction: Improving Computational Latencies of Large End-to-End Models
Feb 27, 2024The accuracy of end-to-end (E2E) automatic speech recognition (ASR) models continues to improve as they are scaled to larger sizes, with some now reaching billions of parameters. Widespread deployment and adoption of these models, however, requires computationally efficient strategies for decoding. In the present work, we study one such strategy: applying multiple frame reduction layers in the encoder to compress encoder outputs into a small number of output frames. While similar techniques have been investigated in previous work, we achieve dramatically more reduction than has previously been demonstrated through the use of multiple funnel reduction layers. Through ablations, we study the impact of various architectural choices in the encoder to identify the most effective strategies. We demonstrate that we can generate one encoder output frame for every 2.56 sec of input speech, without significantly affecting word error rate on a large-scale voice search task, while improving encoder and decoder latencies by 48% and 92% respectively, relative to a strong but computationally expensive baseline.
Handling Ambiguity in Emotion: From Out-of-Domain Detection to Distribution Estimation
Feb 20, 2024



The subjective perception of emotion leads to inconsistent labels from human annotators. Typically, utterances lacking majority-agreed labels are excluded when training an emotion classifier, which cause problems when encountering ambiguous emotional expressions during testing. This paper investigates three methods to handle ambiguous emotion. First, we show that incorporating utterances without majority-agreed labels as an additional class in the classifier reduces the classification performance of the other emotion classes. Then, we propose detecting utterances with ambiguous emotions as out-of-domain samples by quantifying the uncertainty in emotion classification using evidential deep learning. This approach retains the classification accuracy while effectively detects ambiguous emotion expressions. Furthermore, to obtain fine-grained distinctions among ambiguous emotions, we propose representing emotion as a distribution instead of a single class label. The task is thus re-framed from classification to distribution estimation where every individual annotation is taken into account, not just the majority opinion. The evidential uncertainty measure is extended to quantify the uncertainty in emotion distribution estimation. Experimental results on the IEMOCAP and CREMA-D datasets demonstrate the superior capability of the proposed method in terms of majority class prediction, emotion distribution estimation, and uncertainty estimation.
Multilingual and Fully Non-Autoregressive ASR with Large Language Model Fusion: A Comprehensive Study
Jan 23, 2024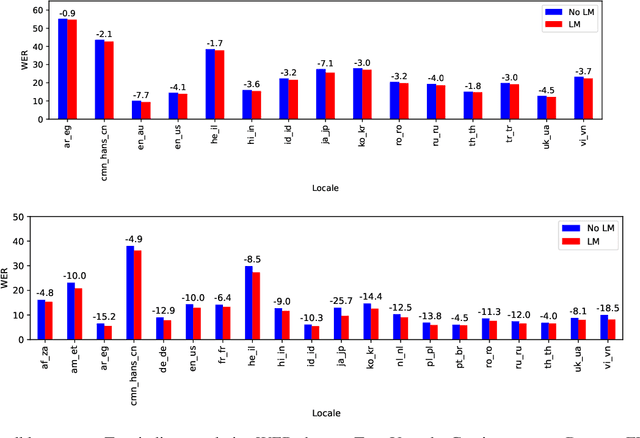
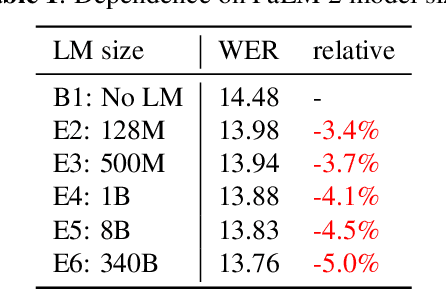
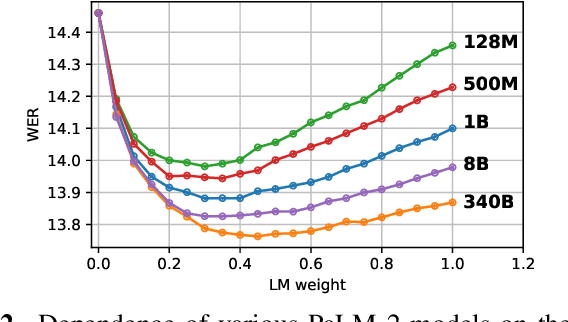
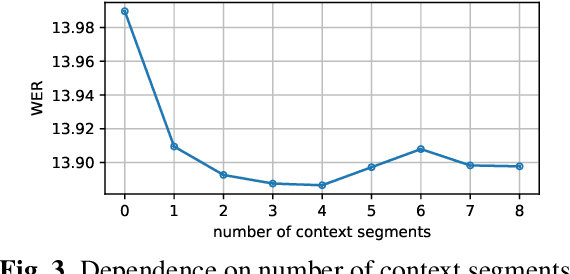
In the era of large models, the autoregressive nature of decoding often results in latency serving as a significant bottleneck. We propose a non-autoregressive LM-fused ASR system that effectively leverages the parallelization capabilities of accelerator hardware. Our approach combines the Universal Speech Model (USM) and the PaLM 2 language model in per-segment scoring mode, achieving an average relative WER improvement across all languages of 10.8% on FLEURS and 3.6% on YouTube captioning. Furthermore, our comprehensive ablation study analyzes key parameters such as LLM size, context length, vocabulary size, fusion methodology. For instance, we explore the impact of LLM size ranging from 128M to 340B parameters on ASR performance. This study provides valuable insights into the factors influencing the effectiveness of practical large-scale LM-fused speech recognition systems.
Efficient Adapter Finetuning for Tail Languages in Streaming Multilingual ASR
Jan 17, 2024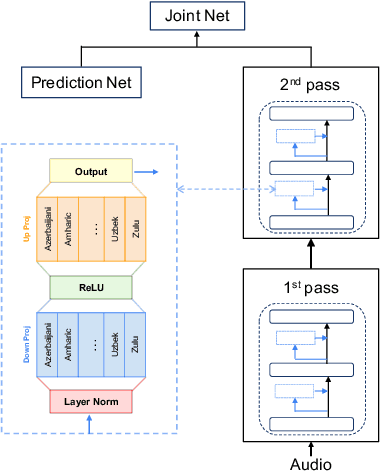

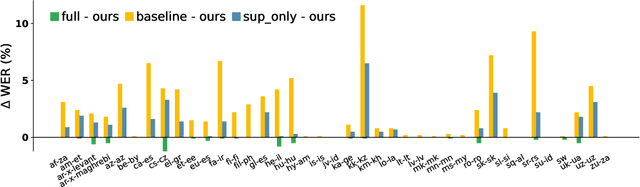
The end-to-end ASR model is often desired in the streaming multilingual scenario since it is easier to deploy and can benefit from pre-trained speech models such as powerful foundation models. Meanwhile, the heterogeneous nature and imbalanced data abundance of different languages may cause performance degradation, leading to asynchronous peak performance for different languages during training, especially on tail ones. Sometimes even the data itself may become unavailable as a result of the enhanced privacy protection. Existing work tend to significantly increase the model size or learn language-specific decoders to accommodate each language separately. In this study, we explore simple yet effective Language-Dependent Adapter (LDA) finetuning under a cascaded Conformer transducer framework enhanced by teacher pseudo-labeling for tail languages in the streaming multilingual ASR. The adapter only accounts for 0.4% of the full model per language. It is plugged into the frozen foundation model and is the only trainable module during the finetuning process with noisy student training. The final model merges the adapter parameters from different checkpoints for different languages. The model performance is validated on a challenging multilingual dictation dataset, which includes 39 tail languages across Latin, Greek, Arabic, etc. Our proposed method brings 12.2% word error rate reduction on average and up to 37.5% on a single locale. Furthermore, we show that our parameter-efficient LDA can match the quality of the full model finetuning, thus greatly alleviating the asynchronous peak performance issue.
USM-Lite: Quantization and Sparsity Aware Fine-tuning for Speech Recognition with Universal Speech Models
Jan 03, 2024End-to-end automatic speech recognition (ASR) models have seen revolutionary quality gains with the recent development of large-scale universal speech models (USM). However, deploying these massive USMs is extremely expensive due to the enormous memory usage and computational cost. Therefore, model compression is an important research topic to fit USM-based ASR under budget in real-world scenarios. In this study, we propose a USM fine-tuning approach for ASR, with a low-bit quantization and N:M structured sparsity aware paradigm on the model weights, reducing the model complexity from parameter precision and matrix topology perspectives. We conducted extensive experiments with a 2-billion parameter USM on a large-scale voice search dataset to evaluate our proposed method. A series of ablation studies validate the effectiveness of up to int4 quantization and 2:4 sparsity. However, a single compression technique fails to recover the performance well under extreme setups including int2 quantization and 1:4 sparsity. By contrast, our proposed method can compress the model to have 9.4% of the size, at the cost of only 7.3% relative word error rate (WER) regressions. We also provided in-depth analyses on the results and discussions on the limitations and potential solutions, which would be valuable for future studies.
Improved Long-Form Speech Recognition by Jointly Modeling the Primary and Non-primary Speakers
Dec 18, 2023ASR models often suffer from a long-form deletion problem where the model predicts sequential blanks instead of words when transcribing a lengthy audio (in the order of minutes or hours). From the perspective of a user or downstream system consuming the ASR results, this behavior can be perceived as the model "being stuck", and potentially make the product hard to use. One of the culprits for long-form deletion is training-test data mismatch, which can happen even when the model is trained on diverse and large-scale data collected from multiple application domains. In this work, we introduce a novel technique to simultaneously model different groups of speakers in the audio along with the standard transcript tokens. Speakers are grouped as primary and non-primary, which connects the application domains and significantly alleviates the long-form deletion problem. This improved model neither needs any additional training data nor incurs additional training or inference cost.
Text Injection for Capitalization and Turn-Taking Prediction in Speech Models
Aug 14, 2023



Text injection for automatic speech recognition (ASR), wherein unpaired text-only data is used to supplement paired audio-text data, has shown promising improvements for word error rate. This study examines the use of text injection for auxiliary tasks, which are the non-ASR tasks often performed by an E2E model. In this work, we use joint end-to-end and internal language model training (JEIT) as our text injection algorithm to train an ASR model which performs two auxiliary tasks. The first is capitalization, which is a de-normalization task. The second is turn-taking prediction, which attempts to identify whether a user has completed their conversation turn in a digital assistant interaction. We show results demonstrating that our text injection method boosts capitalization performance for long-tail data, and improves turn-taking detection recall.
Improving Joint Speech-Text Representations Without Alignment
Aug 11, 2023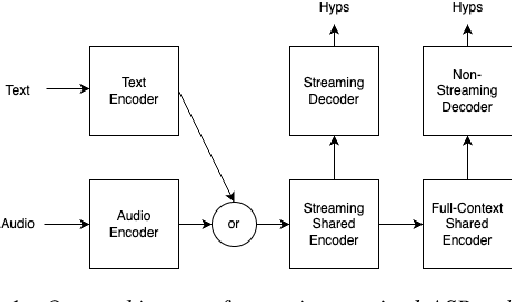
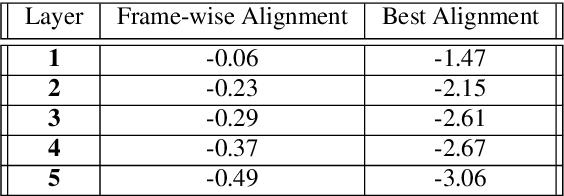
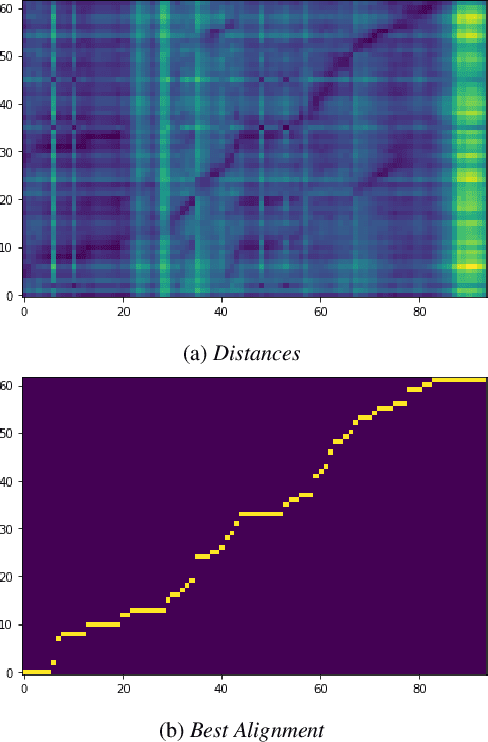
The last year has seen astonishing progress in text-prompted image generation premised on the idea of a cross-modal representation space in which the text and image domains are represented jointly. In ASR, this idea has found application as joint speech-text encoders that can scale to the capacities of very large parameter models by being trained on both unpaired speech and text. While these methods show promise, they have required special treatment of the sequence-length mismatch inherent in speech and text, either by up-sampling heuristics or an explicit alignment model. In this work, we offer evidence that joint speech-text encoders naturally achieve consistent representations across modalities by disregarding sequence length, and argue that consistency losses could forgive length differences and simply assume the best alignment. We show that such a loss improves downstream WER in both a large-parameter monolingual and multilingual system.
How to Estimate Model Transferability of Pre-Trained Speech Models?
Jun 01, 2023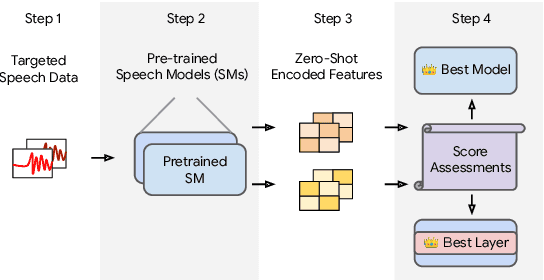
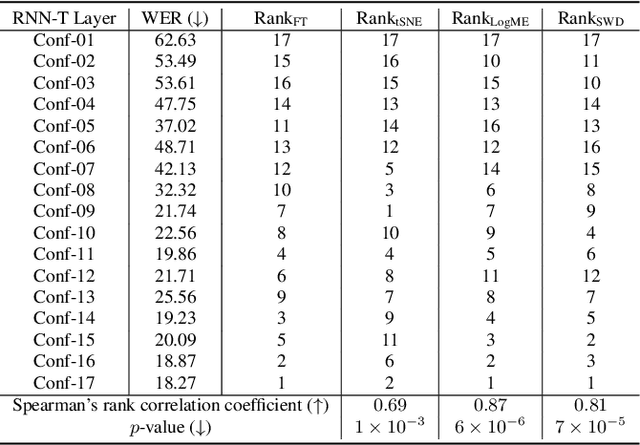
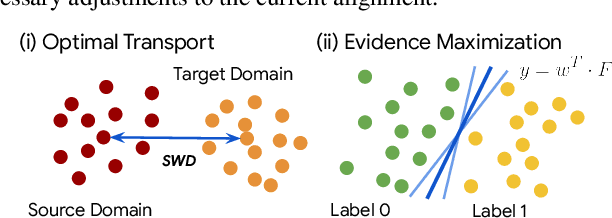
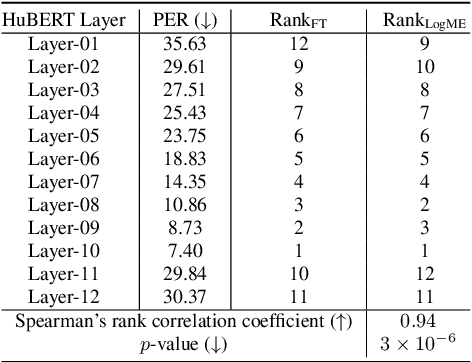
In this work, we introduce a ``score-based assessment'' framework for estimating the transferability of pre-trained speech models (PSMs) for fine-tuning target tasks. We leverage upon two representation theories, Bayesian likelihood estimation and optimal transport, to generate rank scores for the PSM candidates using the extracted representations. Our framework efficiently computes transferability scores without actual fine-tuning of candidate models or layers by making a temporal independent hypothesis. We evaluate some popular supervised speech models (e.g., Conformer RNN-Transducer) and self-supervised speech models (e.g., HuBERT) in cross-layer and cross-model settings using public data. Experimental results show a high Spearman's rank correlation and low $p$-value between our estimation framework and fine-tuning ground truth. Our proposed transferability framework requires less computational time and resources, making it a resource-saving and time-efficient approach for tuning speech foundation models.