 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUSM-Lite: Quantization and Sparsity Aware Fine-tuning for Speech Recognition with Universal Speech Models
Jan 03, 2024End-to-end automatic speech recognition (ASR) models have seen revolutionary quality gains with the recent development of large-scale universal speech models (USM). However, deploying these massive USMs is extremely expensive due to the enormous memory usage and computational cost. Therefore, model compression is an important research topic to fit USM-based ASR under budget in real-world scenarios. In this study, we propose a USM fine-tuning approach for ASR, with a low-bit quantization and N:M structured sparsity aware paradigm on the model weights, reducing the model complexity from parameter precision and matrix topology perspectives. We conducted extensive experiments with a 2-billion parameter USM on a large-scale voice search dataset to evaluate our proposed method. A series of ablation studies validate the effectiveness of up to int4 quantization and 2:4 sparsity. However, a single compression technique fails to recover the performance well under extreme setups including int2 quantization and 1:4 sparsity. By contrast, our proposed method can compress the model to have 9.4% of the size, at the cost of only 7.3% relative word error rate (WER) regressions. We also provided in-depth analyses on the results and discussions on the limitations and potential solutions, which would be valuable for future studies.
2-bit Conformer quantization for automatic speech recognition
May 26, 2023

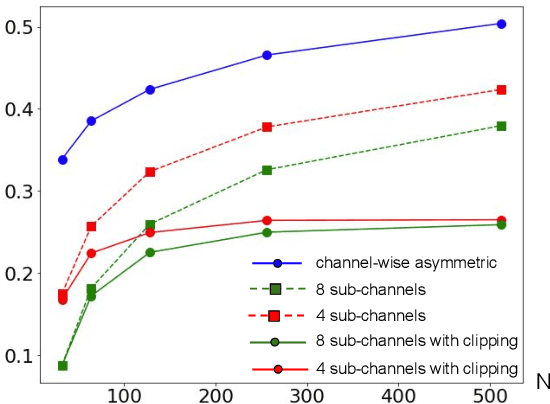

Large speech models are rapidly gaining traction in research community. As a result, model compression has become an important topic, so that these models can fit in memory and be served with reduced cost. Practical approaches for compressing automatic speech recognition (ASR) model use int8 or int4 weight quantization. In this study, we propose to develop 2-bit ASR models. We explore the impact of symmetric and asymmetric quantization combined with sub-channel quantization and clipping on both LibriSpeech dataset and large-scale training data. We obtain a lossless 2-bit Conformer model with 32% model size reduction when compared to state of the art 4-bit Conformer model for LibriSpeech. With the large-scale training data, we obtain a 2-bit Conformer model with over 40% model size reduction against the 4-bit version at the cost of 17% relative word error rate degradation
RAND: Robustness Aware Norm Decay For Quantized Seq2seq Models
May 24, 2023



With the rapid increase in the size of neural networks, model compression has become an important area of research. Quantization is an effective technique at decreasing the model size, memory access, and compute load of large models. Despite recent advances in quantization aware training (QAT) technique, most papers present evaluations that are focused on computer vision tasks, which have different training dynamics compared to sequence tasks. In this paper, we first benchmark the impact of popular techniques such as straight through estimator, pseudo-quantization noise, learnable scale parameter, clipping, etc. on 4-bit seq2seq models across a suite of speech recognition datasets ranging from 1,000 hours to 1 million hours, as well as one machine translation dataset to illustrate its applicability outside of speech. Through the experiments, we report that noise based QAT suffers when there is insufficient regularization signal flowing back to the quantization scale. We propose low complexity changes to the QAT process to improve model accuracy (outperforming popular learnable scale and clipping methods). With the improved accuracy, it opens up the possibility to exploit some of the other benefits of noise based QAT: 1) training a single model that performs well in mixed precision mode and 2) improved generalization on long form speech recognition.
Sharing Low Rank Conformer Weights for Tiny Always-On Ambient Speech Recognition Models
Mar 15, 2023Continued improvements in machine learning techniques offer exciting new opportunities through the use of larger models and larger training datasets. However, there is a growing need to offer these new capabilities on-board low-powered devices such as smartphones, wearables and other embedded environments where only low memory is available. Towards this, we consider methods to reduce the model size of Conformer-based speech recognition models which typically require models with greater than 100M parameters down to just $5$M parameters while minimizing impact on model quality. Such a model allows us to achieve always-on ambient speech recognition on edge devices with low-memory neural processors. We propose model weight reuse at different levels within our model architecture: (i) repeating full conformer block layers, (ii) sharing specific conformer modules across layers, (iii) sharing sub-components per conformer module, and (iv) sharing decomposed sub-component weights after low-rank decomposition. By sharing weights at different levels of our model, we can retain the full model in-memory while increasing the number of virtual transformations applied to the input. Through a series of ablation studies and evaluations, we find that with weight sharing and a low-rank architecture, we can achieve a WER of 2.84 and 2.94 for Librispeech dev-clean and test-clean respectively with a $5$M parameter model.
A Unified Cascaded Encoder ASR Model for Dynamic Model Sizes
Apr 20, 2022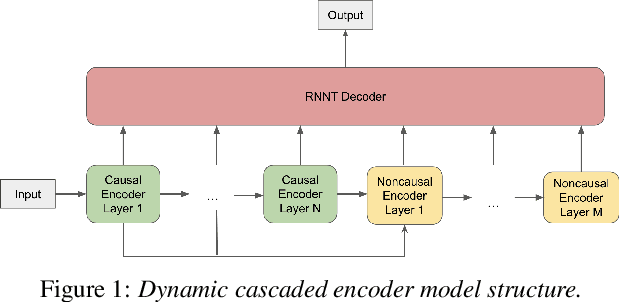
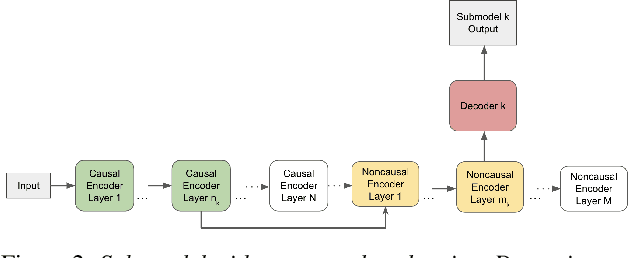
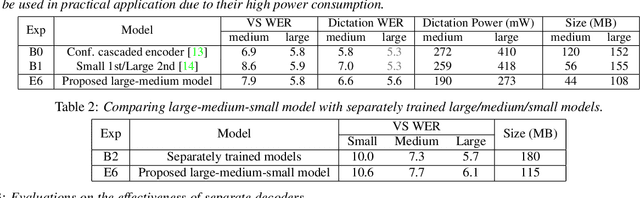
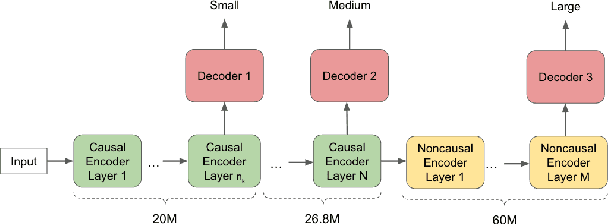
In this paper, we propose a dynamic cascaded encoder Automatic Speech Recognition (ASR) model, which unifies models for different deployment scenarios. Moreover, the model can significantly reduce model size and power consumption without loss of quality. Namely, with the dynamic cascaded encoder model, we explore three techniques to maximally boost the performance of each model size: 1) Use separate decoders for each sub-model while sharing the encoders; 2) Use funnel-pooling to improve the encoder efficiency; 3) Balance the size of causal and non-causal encoders to improve quality and fit deployment constraints. Overall, the proposed large-medium model has 30% smaller size and reduces power consumption by 33%, compared to the baseline cascaded encoder model. The triple-size model that unifies the large, medium, and small models achieves 37% total size reduction with minimal quality loss, while substantially reducing the engineering efforts of having separate models.
Personal VAD 2.0: Optimizing Personal Voice Activity Detection for On-Device Speech Recognition
Apr 13, 2022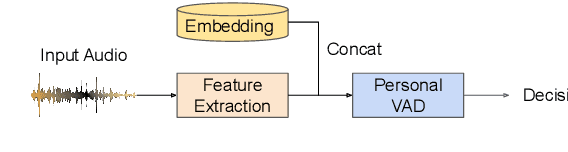
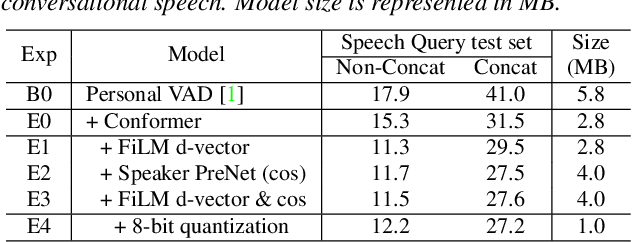
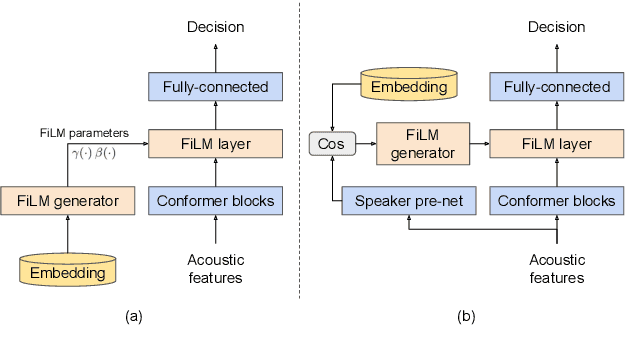
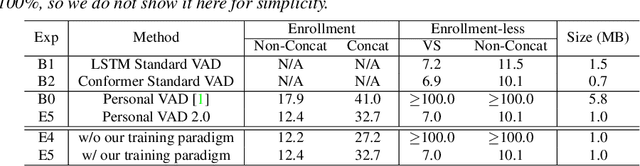
Personalization of on-device speech recognition (ASR) has seen explosive growth in recent years, largely due to the increasing popularity of personal assistant features on mobile devices and smart home speakers. In this work, we present Personal VAD 2.0, a personalized voice activity detector that detects the voice activity of a target speaker, as part of a streaming on-device ASR system. Although previous proof-of-concept studies have validated the effectiveness of Personal VAD, there are still several critical challenges to address before this model can be used in production: first, the quality must be satisfactory in both enrollment and enrollment-less scenarios; second, it should operate in a streaming fashion; and finally, the model size should be small enough to fit a limited latency and CPU/Memory budget. To meet the multi-faceted requirements, we propose a series of novel designs: 1) advanced speaker embedding modulation methods; 2) a new training paradigm to generalize to enrollment-less conditions; 3) architecture and runtime optimizations for latency and resource restrictions. Extensive experiments on a realistic speech recognition system demonstrated the state-of-the-art performance of our proposed method.
4-bit Conformer with Native Quantization Aware Training for Speech Recognition
Mar 29, 2022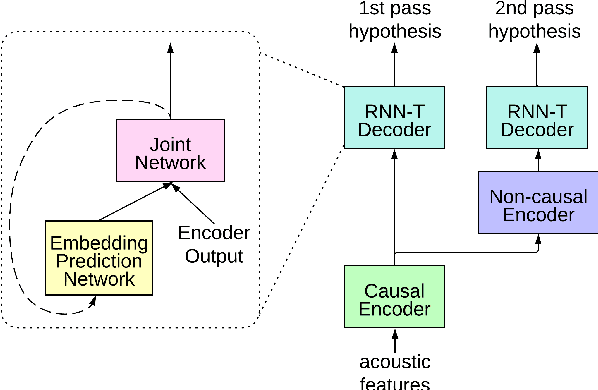
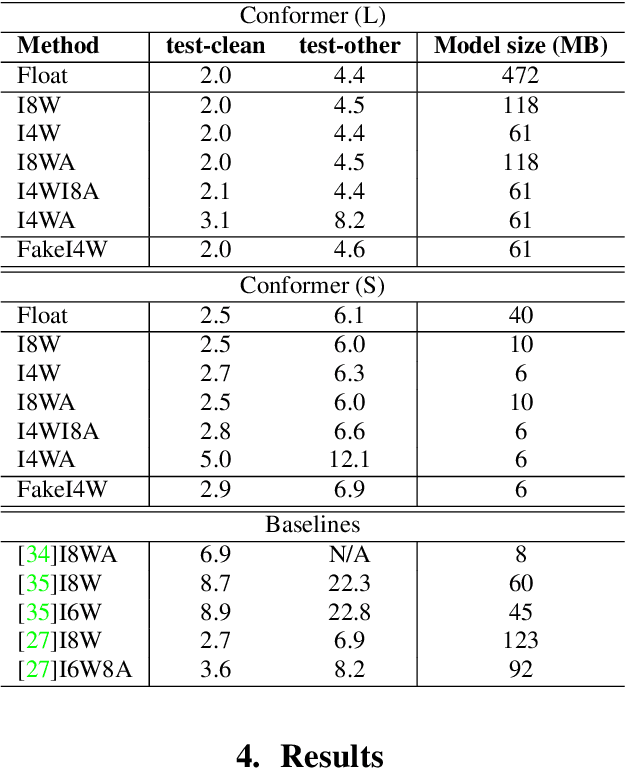

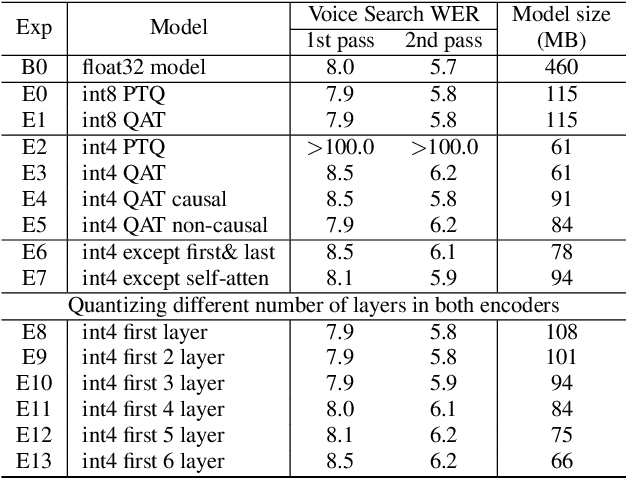
Reducing the latency and model size has always been a significant research problem for live Automatic Speech Recognition (ASR) application scenarios. Along this direction, model quantization has become an increasingly popular approach to compress neural networks and reduce computation cost. Most of the existing practical ASR systems apply post-training 8-bit quantization. To achieve a higher compression rate without introducing additional performance regression, in this study, we propose to develop 4-bit ASR models with native quantization aware training, which leverages native integer operations to effectively optimize both training and inference. We conducted two experiments on state-of-the-art Conformer-based ASR models to evaluate our proposed quantization technique. First, we explored the impact of different precisions for both weight and activation quantization on the LibriSpeech dataset, and obtained a lossless 4-bit Conformer model with 7.7x size reduction compared to the float32 model. Following this, we for the first time investigated and revealed the viability of 4-bit quantization on a practical ASR system that is trained with large-scale datasets, and produced a lossless Conformer ASR model with mixed 4-bit and 8-bit weights that has 5x size reduction compared to the float32 model.
Towards Lifelong Learning of Multilingual Text-To-Speech Synthesis
Oct 09, 2021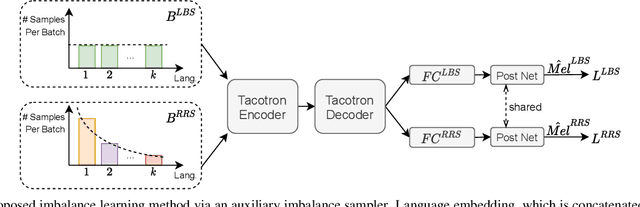
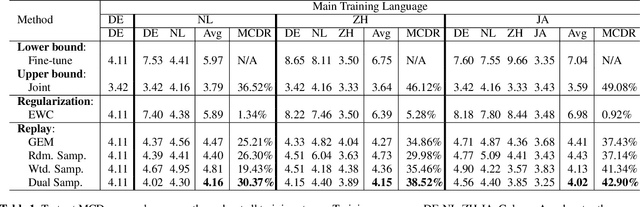
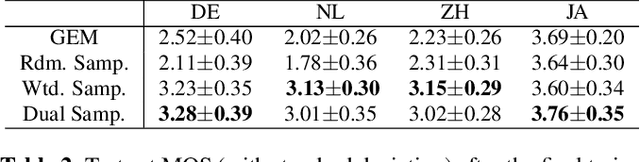
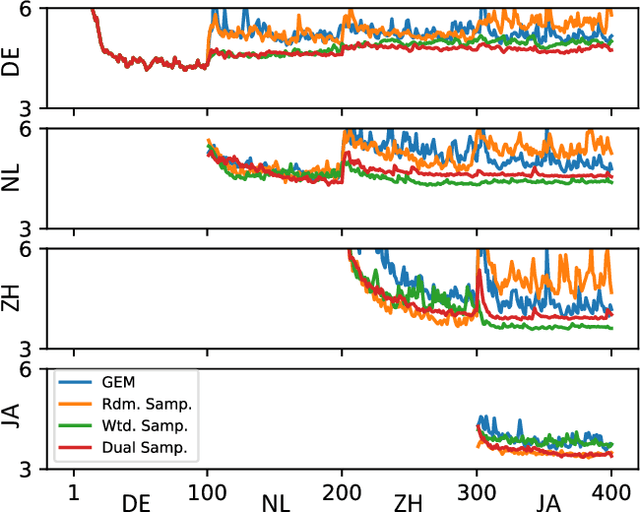
This work presents a lifelong learning approach to train a multilingual Text-To-Speech (TTS) system, where each language was seen as an individual task and was learned sequentially and continually. It does not require pooled data from all languages altogether, and thus alleviates the storage and computation burden. One of the challenges of lifelong learning methods is "catastrophic forgetting": in TTS scenario it means that model performance quickly degrades on previous languages when adapted to a new language. We approach this problem via a data-replay-based lifelong learning method. We formulate the replay process as a supervised learning problem, and propose a simple yet effective dual-sampler framework to tackle the heavily language-imbalanced training samples. Through objective and subjective evaluations, we show that this supervised learning formulation outperforms other gradient-based and regularization-based lifelong learning methods, achieving 43% Mel-Cepstral Distortion reduction compared to a fine-tuning baseline.
Textual Echo Cancellation
Aug 13, 2020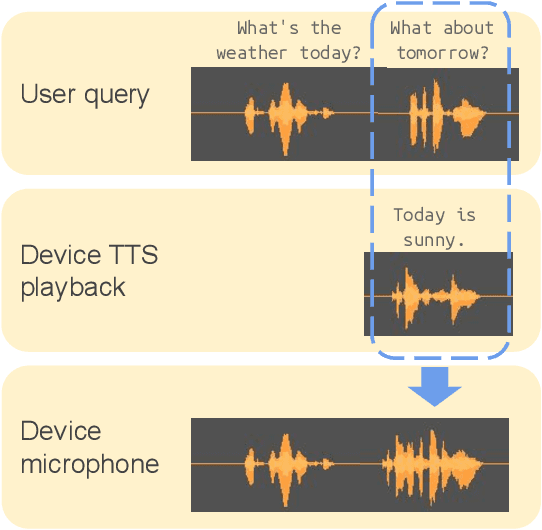
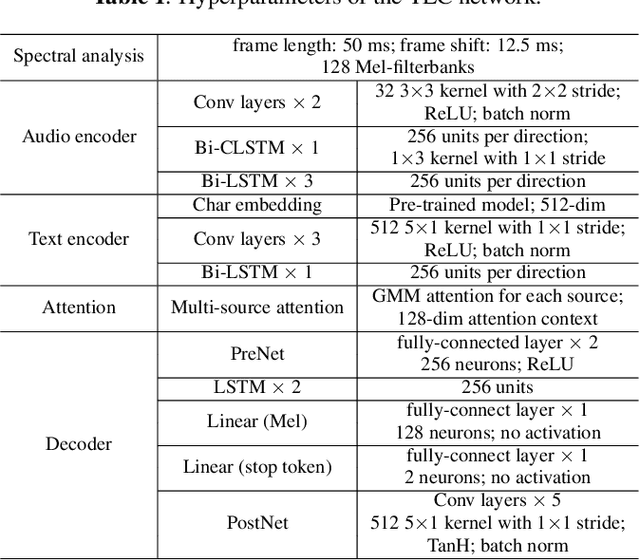
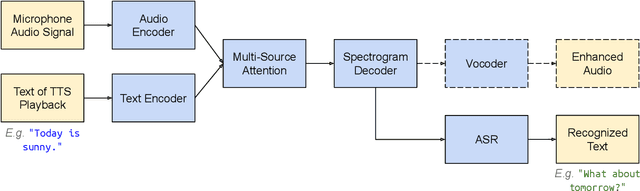
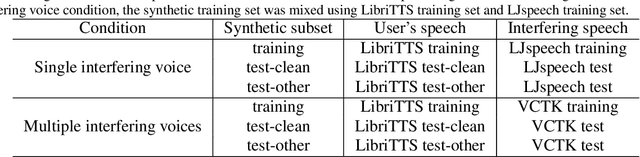
In this paper, we propose Textual Echo Cancellation (TEC) - a framework for cancelling the text-to-speech (TTS) playback echo from overlapped speech recordings. Such a system can largely improve speech recognition performance and user experience for intelligent devices such as smart speakers, as the user can talk to the device while the device is still playing the TTS signal responding to the previous query. We implement this system by using a novel sequence-to-sequence model with multi-source attention that takes both the microphone mixture signal and the source text of the TTS playback as inputs, and predicts the enhanced audio. Experiments show that the textual information of the TTS playback is critical to the enhancement performance. Besides, the text sequence is much smaller in size compared with the raw acoustic signal of the TTS playback, and can be immediately transmitted to the device and the ASR server even before the playback is synthesized. Therefore, our proposed approach effectively reduces Internet communication and latency compared with alternative approaches such as acoustic echo cancellation (AEC).
AutoSpeech: Neural Architecture Search for Speaker Recognition
May 07, 2020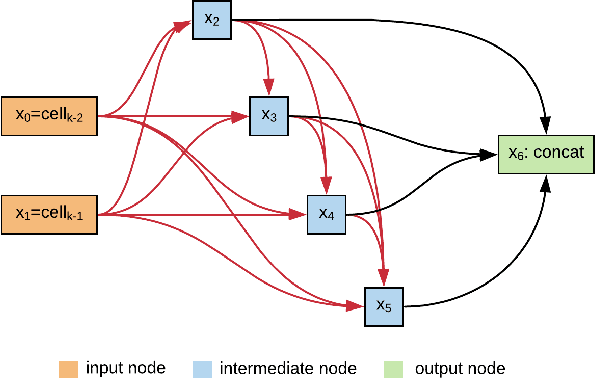
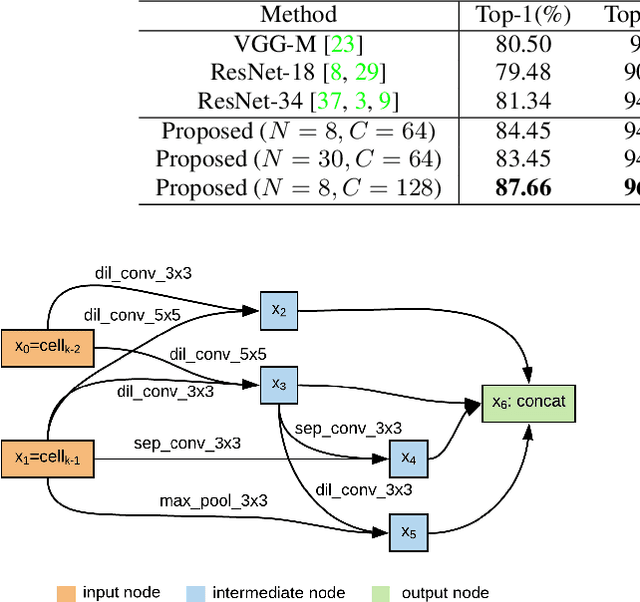
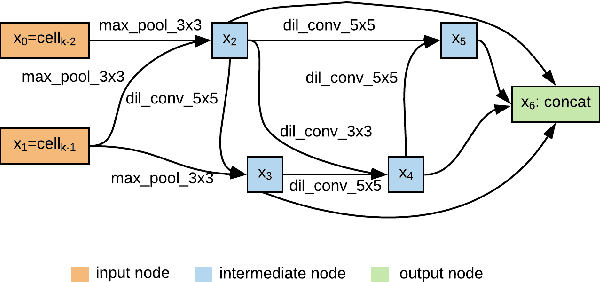
Speaker recognition systems based on Convolutional Neural Networks (CNNs) are often built with off-the-shelf backbones such as VGG-Net or ResNet. However, these backbones were originally proposed for image classification, and therefore may not be naturally fit for speaker recognition. Due to the prohibitive complexity of manually exploring the design space, we propose the first neural architecture search approach approach for the speaker recognition tasks, named as AutoSpeech. Our algorithm first identifies the optimal operation combination in a neural cell and then derives a CNN model by stacking the neural cell for multiple times. The final speaker recognition model can be obtained by training the derived CNN model through the standard scheme. To evaluate the proposed approach, we conduct experiments on both speaker identification and speaker verification tasks using the VoxCeleb1 dataset. Results demonstrate that the derived CNN architectures from the proposed approach significantly outperform current speaker recognition systems based on VGG-M, ResNet-18, and ResNet-34 back-bones, while enjoying lower model complexity.