 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTextual Echo Cancellation
Paper and Code
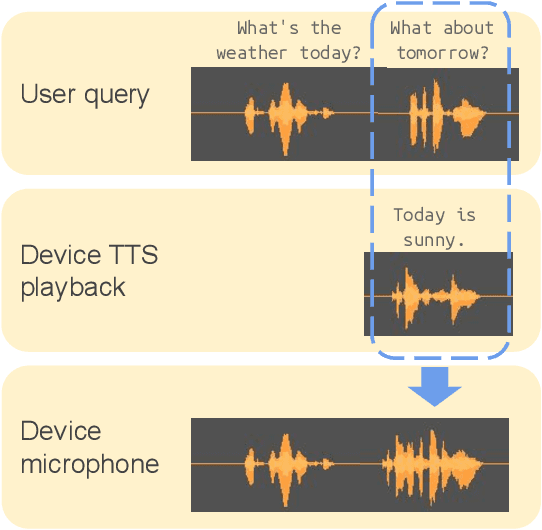
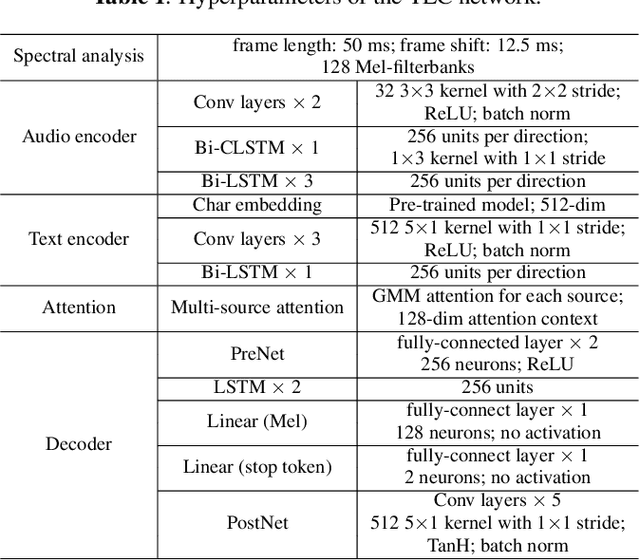
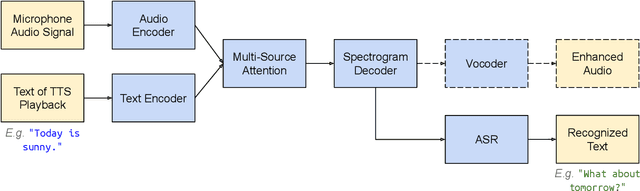
In this paper, we propose Textual Echo Cancellation (TEC) - a framework for cancelling the text-to-speech (TTS) playback echo from overlapped speech recordings. Such a system can largely improve speech recognition performance and user experience for intelligent devices such as smart speakers, as the user can talk to the device while the device is still playing the TTS signal responding to the previous query. We implement this system by using a novel sequence-to-sequence model with multi-source attention that takes both the microphone mixture signal and the source text of the TTS playback as inputs, and predicts the enhanced audio. Experiments show that the textual information of the TTS playback is critical to the enhancement performance. Besides, the text sequence is much smaller in size compared with the raw acoustic signal of the TTS playback, and can be immediately transmitted to the device and the ASR server even before the playback is synthesized. Therefore, our proposed approach effectively reduces Internet communication and latency compared with alternative approaches such as acoustic echo cancellation (AEC).