 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge2-bit Conformer quantization for automatic speech recognition
May 26, 2023

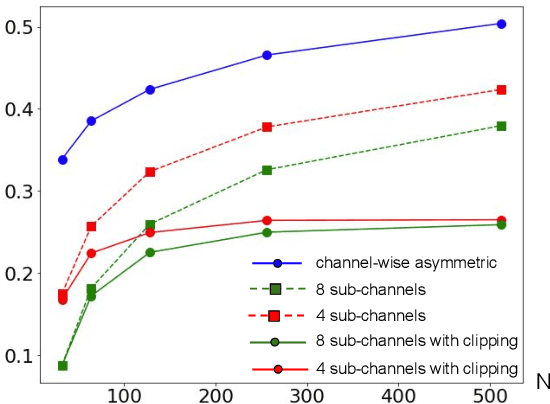

Large speech models are rapidly gaining traction in research community. As a result, model compression has become an important topic, so that these models can fit in memory and be served with reduced cost. Practical approaches for compressing automatic speech recognition (ASR) model use int8 or int4 weight quantization. In this study, we propose to develop 2-bit ASR models. We explore the impact of symmetric and asymmetric quantization combined with sub-channel quantization and clipping on both LibriSpeech dataset and large-scale training data. We obtain a lossless 2-bit Conformer model with 32% model size reduction when compared to state of the art 4-bit Conformer model for LibriSpeech. With the large-scale training data, we obtain a 2-bit Conformer model with over 40% model size reduction against the 4-bit version at the cost of 17% relative word error rate degradation
Streaming Parrotron for on-device speech-to-speech conversion
Oct 25, 2022



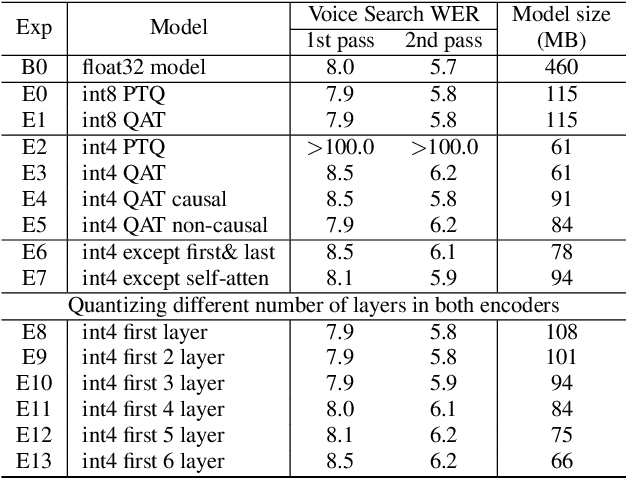
We present a fully on-device and streaming Speech-To-Speech (STS) conversion model that normalizes a given input speech directly to synthesized output speech (a.k.a. Parrotron). Deploying such an end-to-end model locally on mobile devices pose significant challenges in terms of memory footprint and computation requirements. In this paper, we present a streaming-based approach to produce an acceptable delay, with minimal loss in speech conversion quality, when compared to a non-streaming server-based approach. Our approach consists of first streaming the encoder in real time while the speaker is speaking. Then, as soon as the speaker stops speaking, we run the spectrogram decoder in streaming mode along the side of a streaming vocoder to generate output speech in real time. To achieve an acceptable delay quality trade-off, we study a novel hybrid approach for look-ahead in the encoder which combines a look-ahead feature stacker with a look-ahead self-attention. We also compare the model with int4 quantization aware training and int8 post training quantization and show that our streaming approach is 2x faster than real time on the Pixel4 CPU.
4-bit Conformer with Native Quantization Aware Training for Speech Recognition
Mar 29, 2022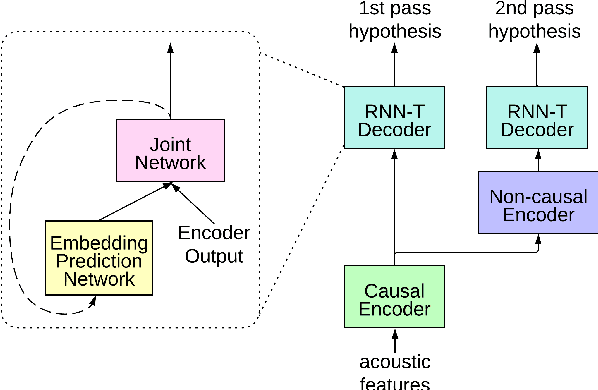
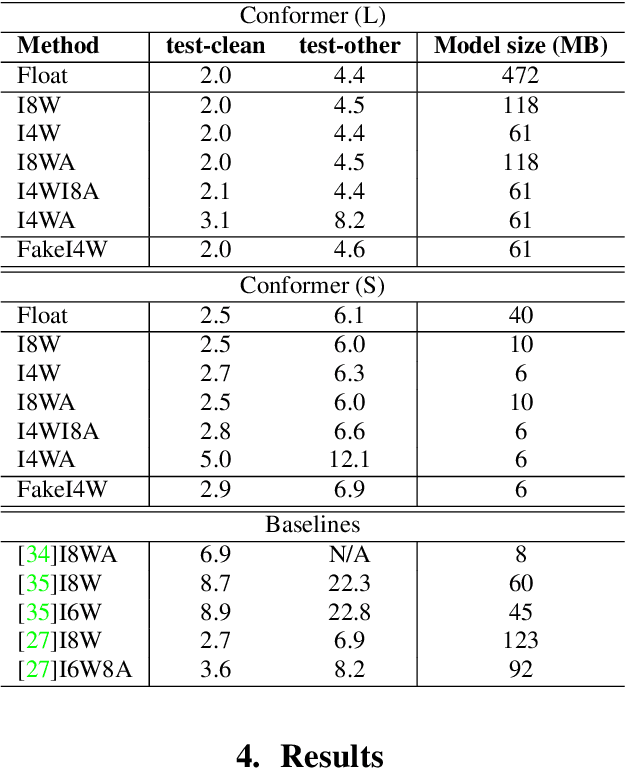

Reducing the latency and model size has always been a significant research problem for live Automatic Speech Recognition (ASR) application scenarios. Along this direction, model quantization has become an increasingly popular approach to compress neural networks and reduce computation cost. Most of the existing practical ASR systems apply post-training 8-bit quantization. To achieve a higher compression rate without introducing additional performance regression, in this study, we propose to develop 4-bit ASR models with native quantization aware training, which leverages native integer operations to effectively optimize both training and inference. We conducted two experiments on state-of-the-art Conformer-based ASR models to evaluate our proposed quantization technique. First, we explored the impact of different precisions for both weight and activation quantization on the LibriSpeech dataset, and obtained a lossless 4-bit Conformer model with 7.7x size reduction compared to the float32 model. Following this, we for the first time investigated and revealed the viability of 4-bit quantization on a practical ASR system that is trained with large-scale datasets, and produced a lossless Conformer ASR model with mixed 4-bit and 8-bit weights that has 5x size reduction compared to the float32 model.