 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Training of Neural Networks at Arbitrary Precision and Sparsity
Sep 14, 2024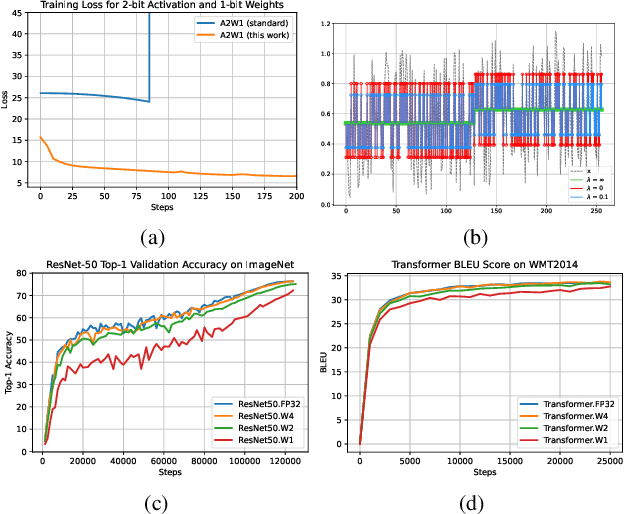

The discontinuous operations inherent in quantization and sparsification introduce obstacles to backpropagation. This is particularly challenging when training deep neural networks in ultra-low precision and sparse regimes. We propose a novel, robust, and universal solution: a denoising affine transform that stabilizes training under these challenging conditions. By formulating quantization and sparsification as perturbations during training, we derive a perturbation-resilient approach based on ridge regression. Our solution employs a piecewise constant backbone model to ensure a performance lower bound and features an inherent noise reduction mechanism to mitigate perturbation-induced corruption. This formulation allows existing models to be trained at arbitrarily low precision and sparsity levels with off-the-shelf recipes. Furthermore, our method provides a novel perspective on training temporal binary neural networks, contributing to ongoing efforts to narrow the gap between artificial and biological neural networks.
Custom Gradient Estimators are Straight-Through Estimators in Disguise
May 08, 2024Quantization-aware training comes with a fundamental challenge: the derivative of quantization functions such as rounding are zero almost everywhere and nonexistent elsewhere. Various differentiable approximations of quantization functions have been proposed to address this issue. In this paper, we prove that when the learning rate is sufficiently small, a large class of weight gradient estimators is equivalent with the straight through estimator (STE). Specifically, after swapping in the STE and adjusting both the weight initialization and the learning rate in SGD, the model will train in almost exactly the same way as it did with the original gradient estimator. Moreover, we show that for adaptive learning rate algorithms like Adam, the same result can be seen without any modifications to the weight initialization and learning rate. We experimentally show that these results hold for both a small convolutional model trained on the MNIST dataset and for a ResNet50 model trained on ImageNet.
PikeLPN: Mitigating Overlooked Inefficiencies of Low-Precision Neural Networks
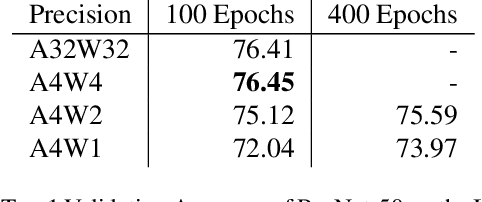
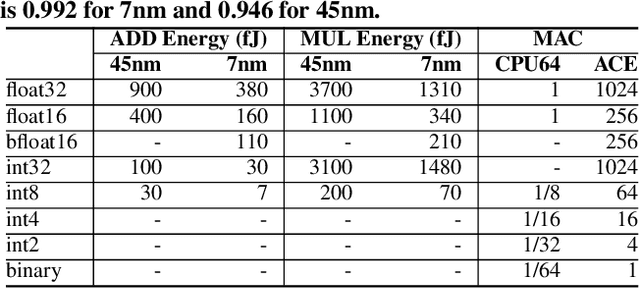
Mar 29, 2024Low-precision quantization is recognized for its efficacy in neural network optimization. Our analysis reveals that non-quantized elementwise operations which are prevalent in layers such as parameterized activation functions, batch normalization, and quantization scaling dominate the inference cost of low-precision models. These non-quantized elementwise operations are commonly overlooked in SOTA efficiency metrics such as Arithmetic Computation Effort (ACE). In this paper, we propose ACEv2 - an extended version of ACE which offers a better alignment with the inference cost of quantized models and their energy consumption on ML hardware. Moreover, we introduce PikeLPN, a model that addresses these efficiency issues by applying quantization to both elementwise operations and multiply-accumulate operations. In particular, we present a novel quantization technique for batch normalization layers named QuantNorm which allows for quantizing the batch normalization parameters without compromising the model performance. Additionally, we propose applying Double Quantization where the quantization scaling parameters are quantized. Furthermore, we recognize and resolve the issue of distribution mismatch in Separable Convolution layers by introducing Distribution-Heterogeneous Quantization which enables quantizing them to low-precision. PikeLPN achieves Pareto-optimality in efficiency-accuracy trade-off with up to 3X efficiency improvement compared to SOTA low-precision models.
4-bit Conformer with Native Quantization Aware Training for Speech Recognition
Mar 29, 2022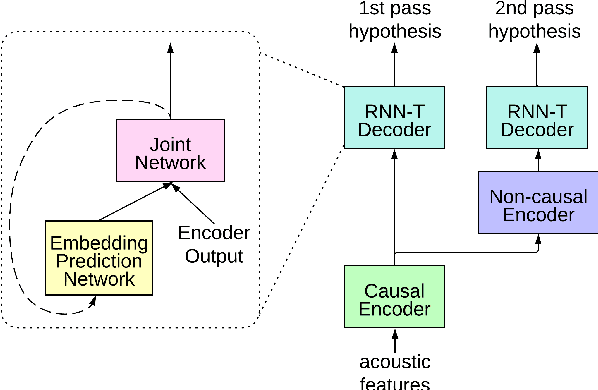
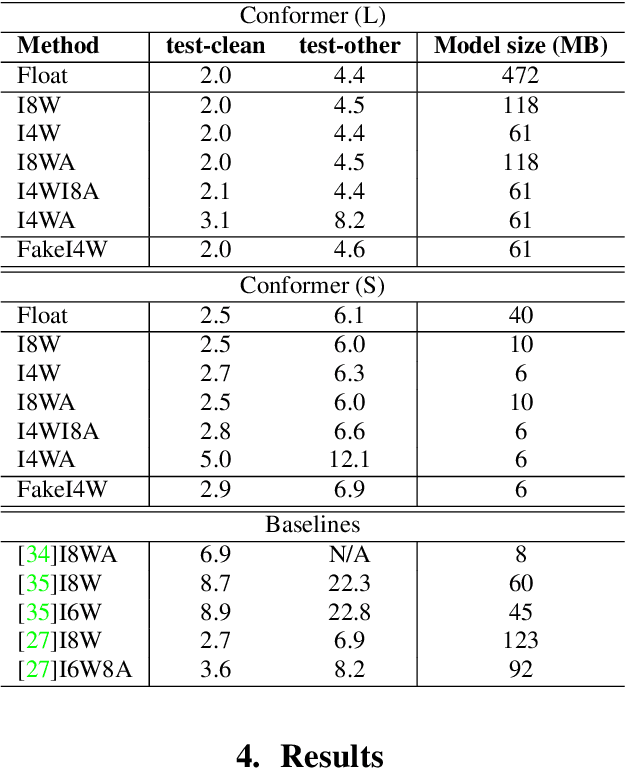

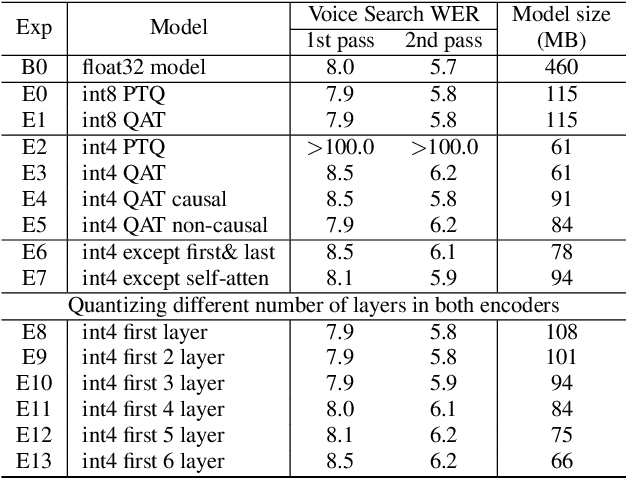
Reducing the latency and model size has always been a significant research problem for live Automatic Speech Recognition (ASR) application scenarios. Along this direction, model quantization has become an increasingly popular approach to compress neural networks and reduce computation cost. Most of the existing practical ASR systems apply post-training 8-bit quantization. To achieve a higher compression rate without introducing additional performance regression, in this study, we propose to develop 4-bit ASR models with native quantization aware training, which leverages native integer operations to effectively optimize both training and inference. We conducted two experiments on state-of-the-art Conformer-based ASR models to evaluate our proposed quantization technique. First, we explored the impact of different precisions for both weight and activation quantization on the LibriSpeech dataset, and obtained a lossless 4-bit Conformer model with 7.7x size reduction compared to the float32 model. Following this, we for the first time investigated and revealed the viability of 4-bit quantization on a practical ASR system that is trained with large-scale datasets, and produced a lossless Conformer ASR model with mixed 4-bit and 8-bit weights that has 5x size reduction compared to the float32 model.
PokeBNN: A Binary Pursuit of Lightweight Accuracy
Nov 30, 2021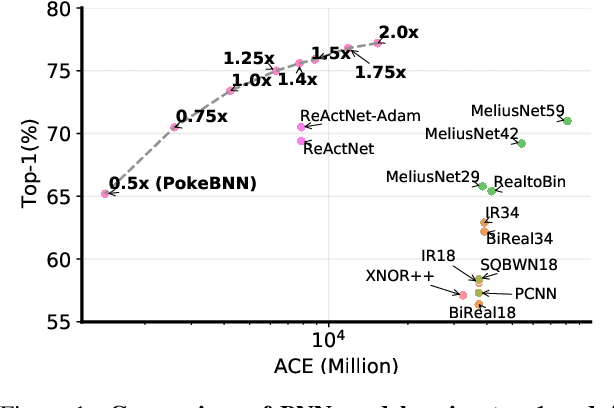


Top-1 ImageNet optimization promotes enormous networks that may be impractical in inference settings. Binary neural networks (BNNs) have the potential to significantly lower the compute intensity but existing models suffer from low quality. To overcome this deficiency, we propose PokeConv, a binary convolution block which improves quality of BNNs by techniques such as adding multiple residual paths, and tuning the activation function. We apply it to ResNet-50 and optimize ResNet's initial convolutional layer which is hard to binarize. We name the resulting network family PokeBNN. These techniques are chosen to yield favorable improvements in both top-1 accuracy and the network's cost. In order to enable joint optimization of the cost together with accuracy, we define arithmetic computation effort (ACE), a hardware- and energy-inspired cost metric for quantized and binarized networks. We also identify a need to optimize an under-explored hyper-parameter controlling the binarization gradient approximation. We establish a new, strong state-of-the-art (SOTA) on top-1 accuracy together with commonly-used CPU64 cost, ACE cost and network size metrics. ReActNet-Adam, the previous SOTA in BNNs, achieved a 70.5% top-1 accuracy with 7.9 ACE. A small variant of PokeBNN achieves 70.5% top-1 with 2.6 ACE, more than 3x reduction in cost; a larger PokeBNN achieves 75.6% top-1 with 7.8 ACE, more than 5% improvement in accuracy without increasing the cost. PokeBNN implementation in JAX/Flax and reproduction instructions are open sourced.
Pareto-Optimal Quantized ResNet Is Mostly 4-bit
May 07, 2021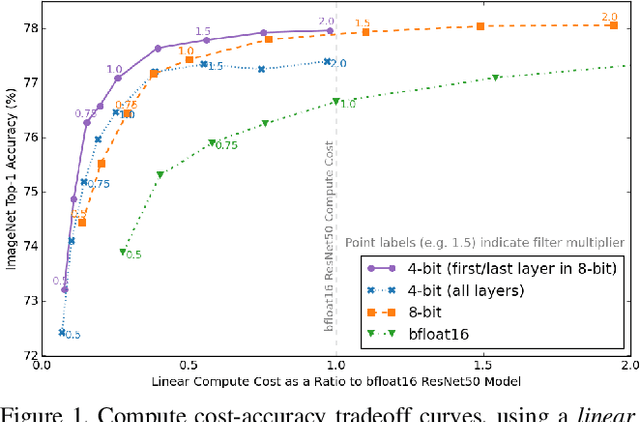


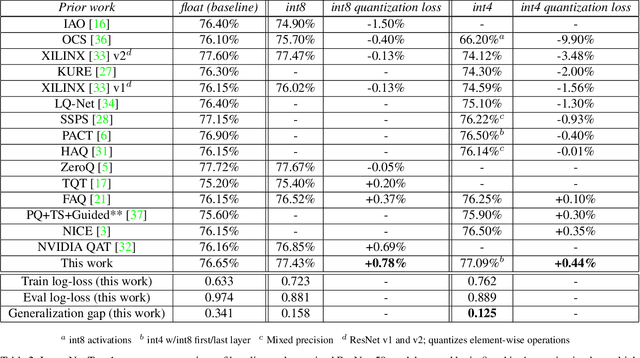
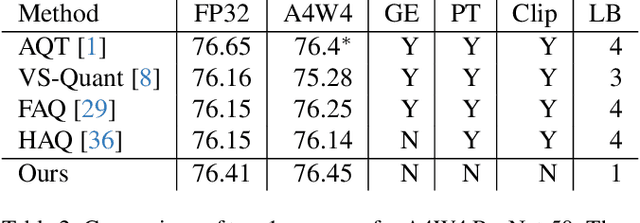
Quantization has become a popular technique to compress neural networks and reduce compute cost, but most prior work focuses on studying quantization without changing the network size. Many real-world applications of neural networks have compute cost and memory budgets, which can be traded off with model quality by changing the number of parameters. In this work, we use ResNet as a case study to systematically investigate the effects of quantization on inference compute cost-quality tradeoff curves. Our results suggest that for each bfloat16 ResNet model, there are quantized models with lower cost and higher accuracy; in other words, the bfloat16 compute cost-quality tradeoff curve is Pareto-dominated by the 4-bit and 8-bit curves, with models primarily quantized to 4-bit yielding the best Pareto curve. Furthermore, we achieve state-of-the-art results on ImageNet for 4-bit ResNet-50 with quantization-aware training, obtaining a top-1 eval accuracy of 77.09%. We demonstrate the regularizing effect of quantization by measuring the generalization gap. The quantization method we used is optimized for practicality: It requires little tuning and is designed with hardware capabilities in mind. Our work motivates further research into optimal numeric formats for quantization, as well as the development of machine learning accelerators supporting these formats. As part of this work, we contribute a quantization library written in JAX, which is open-sourced at https://github.com/google-research/google-research/tree/master/aqt.