 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThinKV: Thought-Adaptive KV Cache Compression for Efficient Reasoning Models
Oct 01, 2025The long-output context generation of large reasoning models enables extended chain of thought (CoT) but also drives rapid growth of the key-value (KV) cache, quickly overwhelming GPU memory. To address this challenge, we propose ThinKV, a thought-adaptive KV cache compression framework. ThinKV is based on the observation that attention sparsity reveals distinct thought types with varying importance within the CoT. It applies a hybrid quantization-eviction strategy, assigning token precision by thought importance and progressively evicting tokens from less critical thoughts as reasoning trajectories evolve. Furthermore, to implement ThinKV, we design a kernel that extends PagedAttention to enable efficient reuse of evicted tokens' memory slots, eliminating compaction overheads. Extensive experiments on DeepSeek-R1-Distill, GPT-OSS, and NVIDIA AceReason across mathematics and coding benchmarks show that ThinKV achieves near-lossless accuracy with less than 5% of the original KV cache, while improving performance with up to 5.8x higher inference throughput over state-of-the-art baselines.
MTLoRA: A Low-Rank Adaptation Approach for Efficient Multi-Task Learning
Mar 29, 2024Adapting models pre-trained on large-scale datasets to a variety of downstream tasks is a common strategy in deep learning. Consequently, parameter-efficient fine-tuning methods have emerged as a promising way to adapt pre-trained models to different tasks while training only a minimal number of parameters. While most of these methods are designed for single-task adaptation, parameter-efficient training in Multi-Task Learning (MTL) architectures is still unexplored. In this paper, we introduce MTLoRA, a novel framework for parameter-efficient training of MTL models. MTLoRA employs Task-Agnostic and Task-Specific Low-Rank Adaptation modules, which effectively disentangle the parameter space in MTL fine-tuning, thereby enabling the model to adeptly handle both task specialization and interaction within MTL contexts. We applied MTLoRA to hierarchical-transformer-based MTL architectures, adapting them to multiple downstream dense prediction tasks. Our extensive experiments on the PASCAL dataset show that MTLoRA achieves higher accuracy on downstream tasks compared to fully fine-tuning the MTL model while reducing the number of trainable parameters by 3.6x. Furthermore, MTLoRA establishes a Pareto-optimal trade-off between the number of trainable parameters and the accuracy of the downstream tasks, outperforming current state-of-the-art parameter-efficient training methods in both accuracy and efficiency. Our code is publicly available.
PikeLPN: Mitigating Overlooked Inefficiencies of Low-Precision Neural Networks
Mar 29, 2024Low-precision quantization is recognized for its efficacy in neural network optimization. Our analysis reveals that non-quantized elementwise operations which are prevalent in layers such as parameterized activation functions, batch normalization, and quantization scaling dominate the inference cost of low-precision models. These non-quantized elementwise operations are commonly overlooked in SOTA efficiency metrics such as Arithmetic Computation Effort (ACE). In this paper, we propose ACEv2 - an extended version of ACE which offers a better alignment with the inference cost of quantized models and their energy consumption on ML hardware. Moreover, we introduce PikeLPN, a model that addresses these efficiency issues by applying quantization to both elementwise operations and multiply-accumulate operations. In particular, we present a novel quantization technique for batch normalization layers named QuantNorm which allows for quantizing the batch normalization parameters without compromising the model performance. Additionally, we propose applying Double Quantization where the quantization scaling parameters are quantized. Furthermore, we recognize and resolve the issue of distribution mismatch in Separable Convolution layers by introducing Distribution-Heterogeneous Quantization which enables quantizing them to low-precision. PikeLPN achieves Pareto-optimality in efficiency-accuracy trade-off with up to 3X efficiency improvement compared to SOTA low-precision models.
AdaMTL: Adaptive Input-dependent Inference for Efficient Multi-Task Learning
Apr 17, 2023Modern Augmented reality applications require performing multiple tasks on each input frame simultaneously. Multi-task learning (MTL) represents an effective approach where multiple tasks share an encoder to extract representative features from the input frame, followed by task-specific decoders to generate predictions for each task. Generally, the shared encoder in MTL models needs to have a large representational capacity in order to generalize well to various tasks and input data, which has a negative effect on the inference latency. In this paper, we argue that due to the large variations in the complexity of the input frames, some computations might be unnecessary for the output. Therefore, we introduce AdaMTL, an adaptive framework that learns task-aware inference policies for the MTL models in an input-dependent manner. Specifically, we attach a task-aware lightweight policy network to the shared encoder and co-train it alongside the MTL model to recognize unnecessary computations. During runtime, our task-aware policy network decides which parts of the model to activate depending on the input frame and the target computational complexity. Extensive experiments on the PASCAL dataset demonstrate that AdaMTL reduces the computational complexity by 43% while improving the accuracy by 1.32% compared to single-task models. Combined with SOTA MTL methodologies, AdaMTL boosts the accuracy by 7.8% while improving the efficiency by 3.1X. When deployed on Vuzix M4000 smart glasses, AdaMTL reduces the inference latency and the energy consumption by up to 21.8% and 37.5%, respectively, compared to the static MTL model. Our code is publicly available at https://github.com/scale-lab/AdaMTL.git.
BitTrain: Sparse Bitmap Compression for Memory-Efficient Training on the Edge
Oct 29, 2021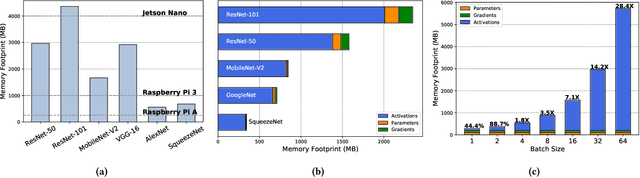


Training on the Edge enables neural networks to learn continuously from new data after deployment on memory-constrained edge devices. Previous work is mostly concerned with reducing the number of model parameters which is only beneficial for inference. However, memory footprint from activations is the main bottleneck for training on the edge. Existing incremental training methods fine-tune the last few layers sacrificing accuracy gains from re-training the whole model. In this work, we investigate the memory footprint of training deep learning models, and use our observations to propose BitTrain. In BitTrain, we exploit activation sparsity and propose a novel bitmap compression technique that reduces the memory footprint during training. We save the activations in our proposed bitmap compression format during the forward pass of the training, and restore them during the backward pass for the optimizer computations. The proposed method can be integrated seamlessly in the computation graph of modern deep learning frameworks. Our implementation is safe by construction, and has no negative impact on the accuracy of model training. Experimental results show up to 34% reduction in the memory footprint at a sparsity level of 50%. Further pruning during training results in more than 70% sparsity, which can lead to up to 56% reduction in memory footprint. BitTrain advances the efforts towards bringing more machine learning capabilities to edge devices. Our source code is available at https://github.com/scale-lab/BitTrain.
AdaCon: Adaptive Context-Aware Object Detection for Resource-Constrained Embedded Devices
Aug 16, 2021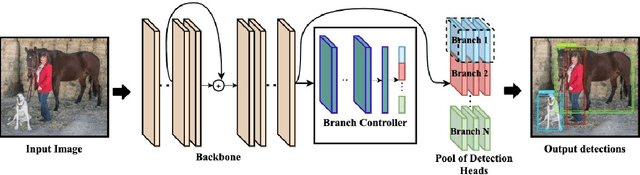
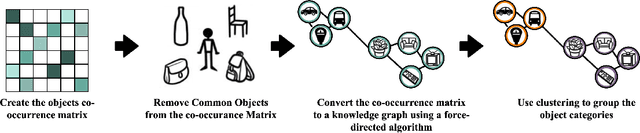
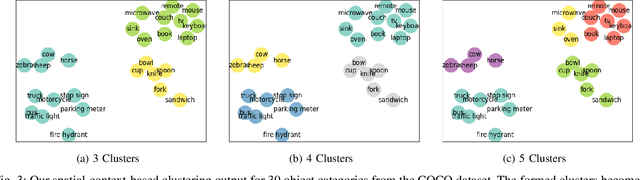
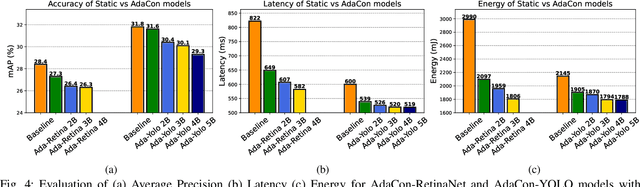
Convolutional Neural Networks achieve state-of-the-art accuracy in object detection tasks. However, they have large computational and energy requirements that challenge their deployment on resource-constrained edge devices. Object detection takes an image as an input, and identifies the existing object classes as well as their locations in the image. In this paper, we leverage the prior knowledge about the probabilities that different object categories can occur jointly to increase the efficiency of object detection models. In particular, our technique clusters the object categories based on their spatial co-occurrence probability. We use those clusters to design an adaptive network. During runtime, a branch controller decides which part(s) of the network to execute based on the spatial context of the input frame. Our experiments using COCO dataset show that our adaptive object detection model achieves up to 45% reduction in the energy consumption, and up to 27% reduction in the latency, with a small loss in the average precision (AP) of object detection.
AdaSense: Adaptive Low-Power Sensing and Activity Recognition for Wearable Devices
Jun 10, 2020

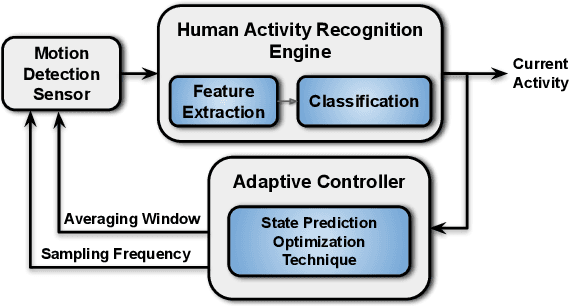

Wearable devices have strict power and memory limitations. As a result, there is a need to optimize the power consumption on those devices without sacrificing the accuracy. This paper presents AdaSense: a sensing, feature extraction and classification co-optimized framework for Human Activity Recognition. The proposed techniques reduce the power consumption by dynamically switching among different sensor configurations as a function of the user activity. The framework selects configurations that represent the pareto-frontier of the accuracy and energy trade-off. AdaSense also uses low-overhead processing and classification methodologies. The introduced approach achieves 69% reduction in the power consumption of the sensor with less than 1.5% decrease in the activity recognition accuracy.