 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgetorchmSAT: A GPU-Accelerated Approximation To The Maximum Satisfiability Problem
Feb 06, 2024The remarkable achievements of machine learning techniques in analyzing discrete structures have drawn significant attention towards their integration into combinatorial optimization algorithms. Typically, these methodologies improve existing solvers by injecting learned models within the solving loop to enhance the efficiency of the search process. In this work, we derive a single differentiable function capable of approximating solutions for the Maximum Satisfiability Problem (MaxSAT). Then, we present a novel neural network architecture to model our differentiable function, and progressively solve MaxSAT using backpropagation. This approach eliminates the need for labeled data or a neural network training phase, as the training process functions as the solving algorithm. Additionally, we leverage the computational power of GPUs to accelerate these computations. Experimental results on challenging MaxSAT instances show that our proposed methodology outperforms two existing MaxSAT solvers, and is on par with another in terms of solution cost, without necessitating any training or access to an underlying SAT solver. Given that numerous NP-hard problems can be reduced to MaxSAT, our novel technique paves the way for a new generation of solvers poised to benefit from neural network GPU acceleration.
Automatic MILP Solver Configuration By Learning Problem Similarities
Jul 02, 2023A large number of real-world optimization problems can be formulated as Mixed Integer Linear Programs (MILP). MILP solvers expose numerous configuration parameters to control their internal algorithms. Solutions, and their associated costs or runtimes, are significantly affected by the choice of the configuration parameters, even when problem instances have the same number of decision variables and constraints. On one hand, using the default solver configuration leads to suboptimal solutions. On the other hand, searching and evaluating a large number of configurations for every problem instance is time-consuming and, in some cases, infeasible. In this study, we aim to predict configuration parameters for unseen problem instances that yield lower-cost solutions without the time overhead of searching-and-evaluating configurations at the solving time. Toward that goal, we first investigate the cost correlation of MILP problem instances that come from the same distribution when solved using different configurations. We show that instances that have similar costs using one solver configuration also have similar costs using another solver configuration in the same runtime environment. After that, we present a methodology based on Deep Metric Learning to learn MILP similarities that correlate with their final solutions' costs. At inference time, given a new problem instance, it is first projected into the learned metric space using the trained model, and configuration parameters are instantly predicted using previously-explored configurations from the nearest neighbor instance in the learned embedding space. Empirical results on real-world problem benchmarks show that our method predicts configuration parameters that improve solutions' costs by up to 38% compared to existing approaches.
BitTrain: Sparse Bitmap Compression for Memory-Efficient Training on the Edge
Oct 29, 2021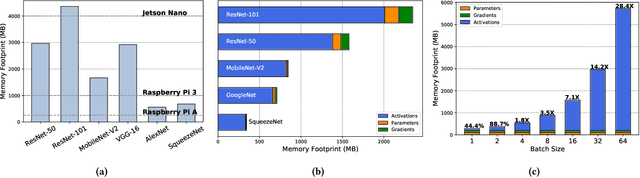

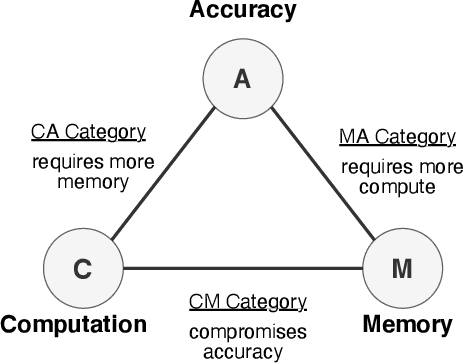

Training on the Edge enables neural networks to learn continuously from new data after deployment on memory-constrained edge devices. Previous work is mostly concerned with reducing the number of model parameters which is only beneficial for inference. However, memory footprint from activations is the main bottleneck for training on the edge. Existing incremental training methods fine-tune the last few layers sacrificing accuracy gains from re-training the whole model. In this work, we investigate the memory footprint of training deep learning models, and use our observations to propose BitTrain. In BitTrain, we exploit activation sparsity and propose a novel bitmap compression technique that reduces the memory footprint during training. We save the activations in our proposed bitmap compression format during the forward pass of the training, and restore them during the backward pass for the optimizer computations. The proposed method can be integrated seamlessly in the computation graph of modern deep learning frameworks. Our implementation is safe by construction, and has no negative impact on the accuracy of model training. Experimental results show up to 34% reduction in the memory footprint at a sparsity level of 50%. Further pruning during training results in more than 70% sparsity, which can lead to up to 56% reduction in memory footprint. BitTrain advances the efforts towards bringing more machine learning capabilities to edge devices. Our source code is available at https://github.com/scale-lab/BitTrain.
Characterizing and Optimizing EDA Flows for the Cloud
Feb 22, 2021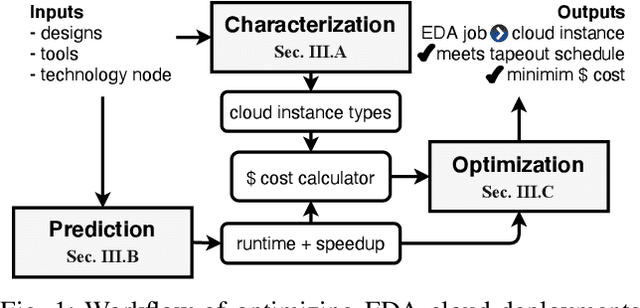
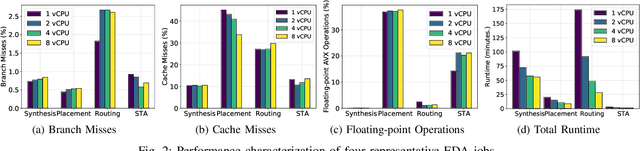
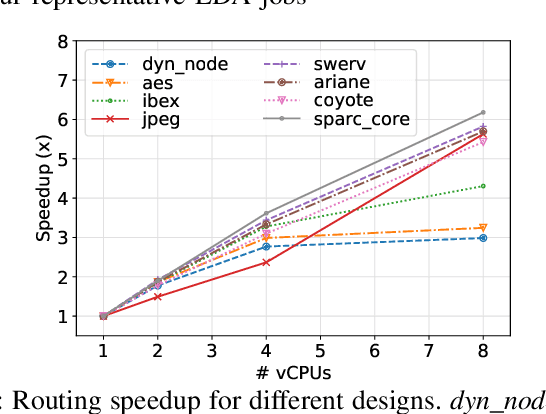
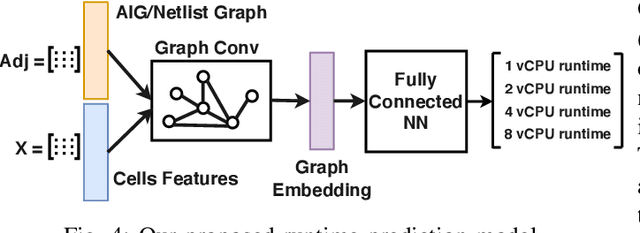
Cloud computing accelerates design space exploration in logic synthesis, and parameter tuning in physical design. However, deploying EDA jobs on the cloud requires EDA teams to deeply understand the characteristics of their jobs in cloud environments. Unfortunately, there has been little to no public information on these characteristics. Thus, in this paper, we formulate the problem of migrating EDA jobs to the cloud. First, we characterize the performance of four main EDA applications, namely: synthesis, placement, routing and static timing analysis. We show that different EDA jobs require different machine configurations. Second, using observations from our characterization, we propose a novel model based on Graph Convolutional Networks to predict the total runtime of a given application on different machine configurations. Our model achieves a prediction accuracy of 87%. Third, we develop a new formulation for optimizing cloud deployments in order to reduce deployment costs while meeting deadline constraints. We present a pseudo-polynomial optimal solution using a multi-choice knapsack mapping that reduces costs by 35.29%.
DRiLLS: Deep Reinforcement Learning for Logic Synthesis
Nov 13, 2019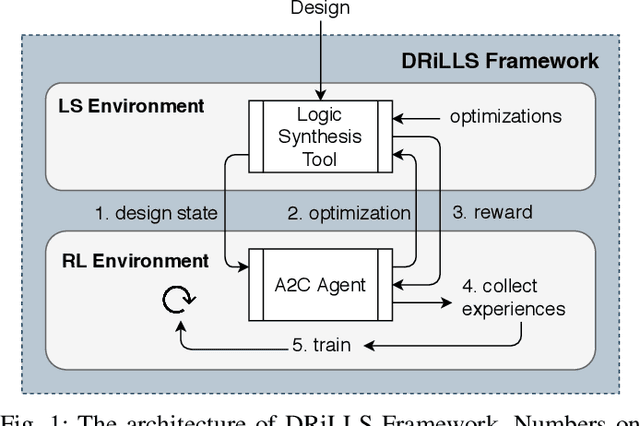
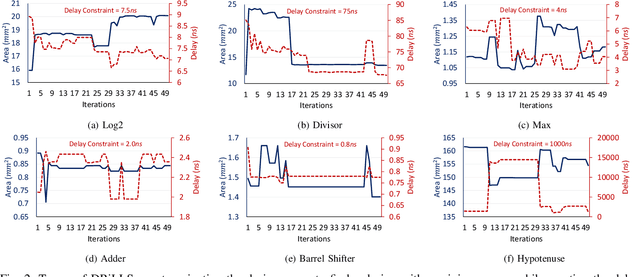
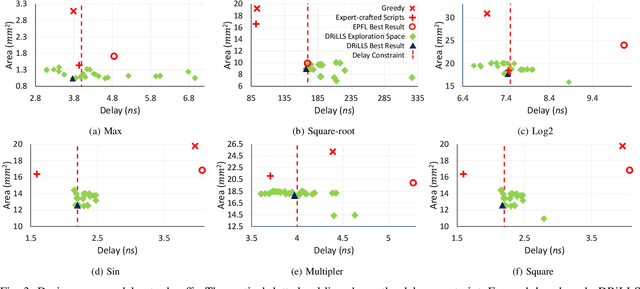
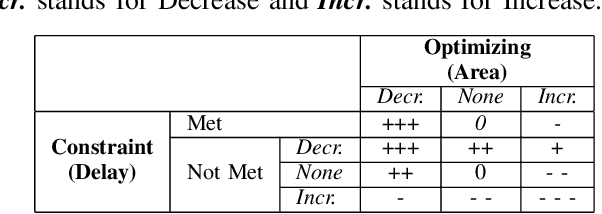
Logic synthesis requires extensive tuning of the synthesis optimization flow where the quality of results (QoR) depends on the sequence of optimizations used. Efficient design space exploration is challenging due to the exponential number of possible optimization permutations. Therefore, automating the optimization process is necessary. In this work, we propose a novel reinforcement learning-based methodology that navigates the optimization space without human intervention. We demonstrate the training of an Advantage Actor Critic (A2C) agent that seeks to minimize area subject to a timing constraint. Using the proposed methodology, designs can be optimized autonomously with no-humans in-loop. Evaluation on the comprehensive EPFL benchmark suite shows that the agent outperforms existing exploration methodologies and improves QoRs by an average of 13%.