 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBitTrain: Sparse Bitmap Compression for Memory-Efficient Training on the Edge
Paper and Code
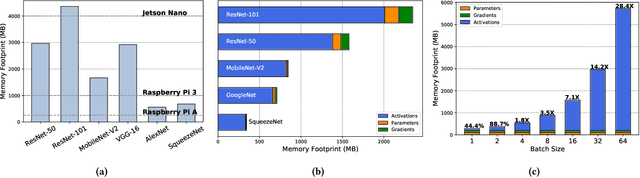


Training on the Edge enables neural networks to learn continuously from new data after deployment on memory-constrained edge devices. Previous work is mostly concerned with reducing the number of model parameters which is only beneficial for inference. However, memory footprint from activations is the main bottleneck for training on the edge. Existing incremental training methods fine-tune the last few layers sacrificing accuracy gains from re-training the whole model. In this work, we investigate the memory footprint of training deep learning models, and use our observations to propose BitTrain. In BitTrain, we exploit activation sparsity and propose a novel bitmap compression technique that reduces the memory footprint during training. We save the activations in our proposed bitmap compression format during the forward pass of the training, and restore them during the backward pass for the optimizer computations. The proposed method can be integrated seamlessly in the computation graph of modern deep learning frameworks. Our implementation is safe by construction, and has no negative impact on the accuracy of model training. Experimental results show up to 34% reduction in the memory footprint at a sparsity level of 50%. Further pruning during training results in more than 70% sparsity, which can lead to up to 56% reduction in memory footprint. BitTrain advances the efforts towards bringing more machine learning capabilities to edge devices. Our source code is available at https://github.com/scale-lab/BitTrain.