 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRTL-Repo: A Benchmark for Evaluating LLMs on Large-Scale RTL Design Projects
May 27, 2024Large Language Models (LLMs) have demonstrated potential in assisting with Register Transfer Level (RTL) design tasks. Nevertheless, there remains to be a significant gap in benchmarks that accurately reflect the complexity of real-world RTL projects. To address this, this paper presents RTL-Repo, a benchmark specifically designed to evaluate LLMs on large-scale RTL design projects. RTL-Repo includes a comprehensive dataset of more than 4000 Verilog code samples extracted from public GitHub repositories, with each sample providing the full context of the corresponding repository. We evaluate several state-of-the-art models on the RTL-Repo benchmark, including GPT-4, GPT-3.5, Starcoder2, alongside Verilog-specific models like VeriGen and RTLCoder, and compare their performance in generating Verilog code for complex projects. The RTL-Repo benchmark provides a valuable resource for the hardware design community to assess and compare LLMs' performance in real-world RTL design scenarios and train LLMs specifically for Verilog code generation in complex, multi-file RTL projects. RTL-Repo is open-source and publicly available on Github.
DRiLLS: Deep Reinforcement Learning for Logic Synthesis
Nov 13, 2019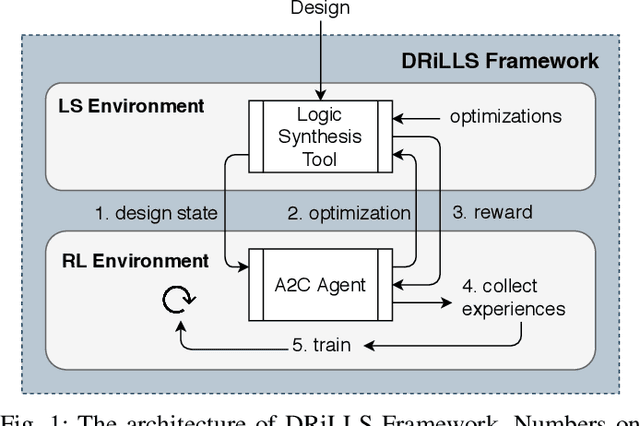
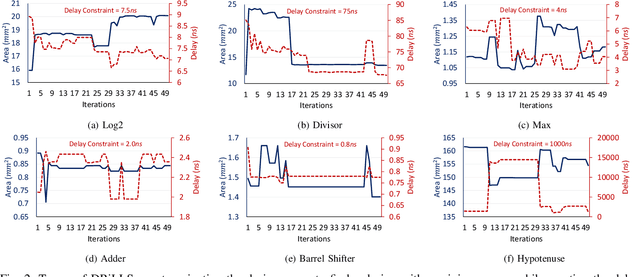
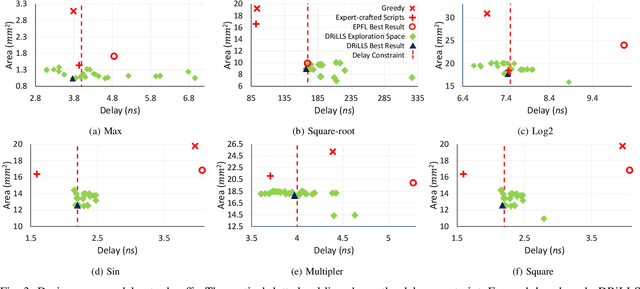
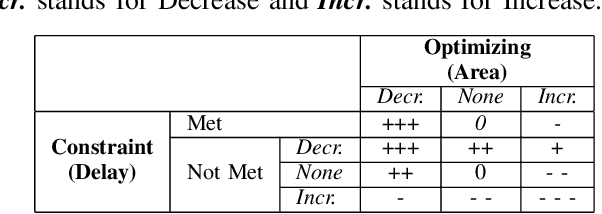
Logic synthesis requires extensive tuning of the synthesis optimization flow where the quality of results (QoR) depends on the sequence of optimizations used. Efficient design space exploration is challenging due to the exponential number of possible optimization permutations. Therefore, automating the optimization process is necessary. In this work, we propose a novel reinforcement learning-based methodology that navigates the optimization space without human intervention. We demonstrate the training of an Advantage Actor Critic (A2C) agent that seeks to minimize area subject to a timing constraint. Using the proposed methodology, designs can be optimized autonomously with no-humans in-loop. Evaluation on the comprehensive EPFL benchmark suite shows that the agent outperforms existing exploration methodologies and improves QoRs by an average of 13%.