 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEEGsig machine learning-based toolbox for End-to-End EEG signal processing
Oct 24, 2020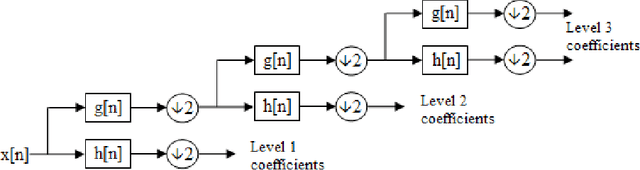
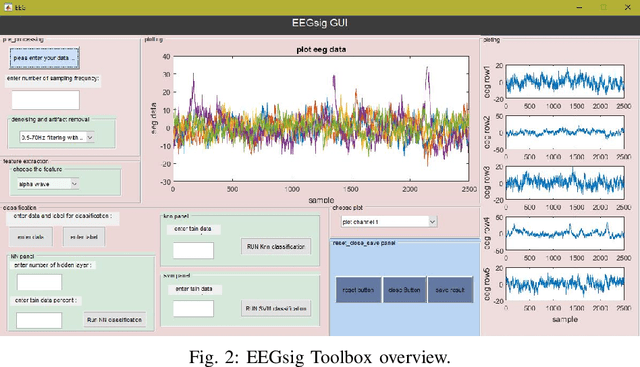
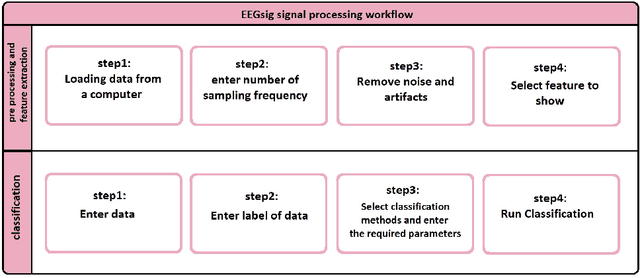
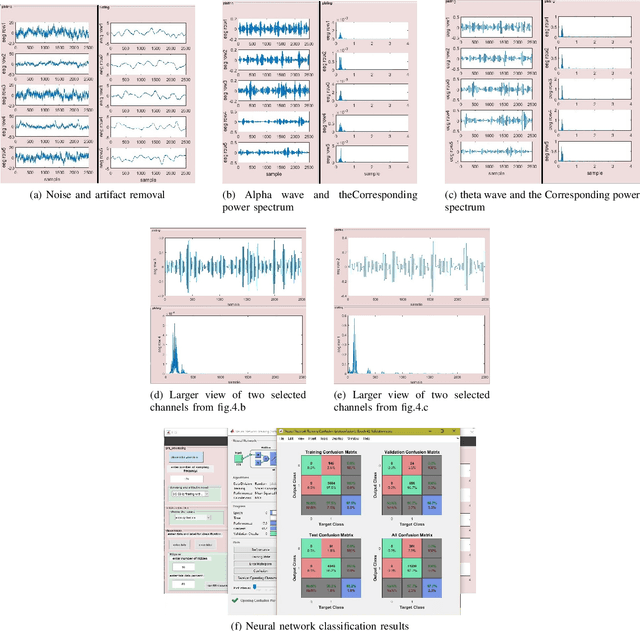
In the quest to realize comprehensive EEG signal processing toolbox, in this paper, we demonstrate the first toolbox contain three states of EEG signal processing (preprocessing, feature extraction, classification) together. Our goal is to provide a comprehensive toolbox for EEG signal processing. Using MATLAB software, we have developed an open-source toolbox for end-to-end processing of the EEG signal. As we know, in many research work in the field of neuroscience and EEG signal processing, we first clear the signal and remove noise, artifact, etc. Which we know as preprocessing, and then extract the feature from the relevant signal, and finally Machine learning classifiers used to classification of signal. We have tried to provide all the above steps in the form of EEGsig as a graphical user interface(GUI) so that there is no need for programming for all the above steps and reduce the time to complete these projects to a desirable level.
DRiLLS: Deep Reinforcement Learning for Logic Synthesis
Nov 13, 2019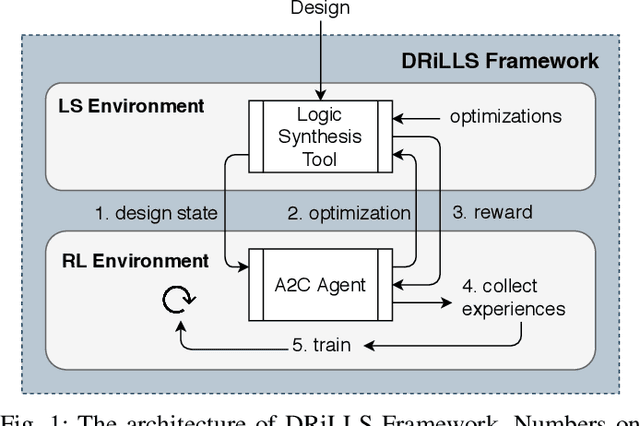
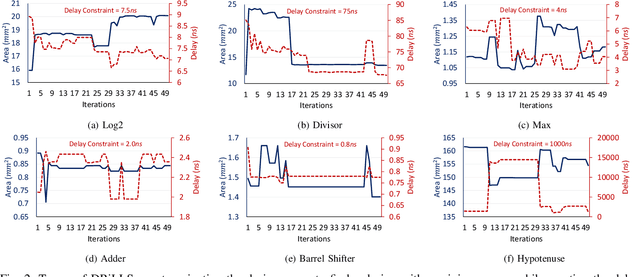
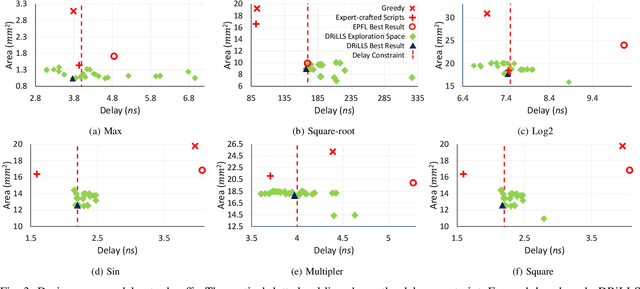
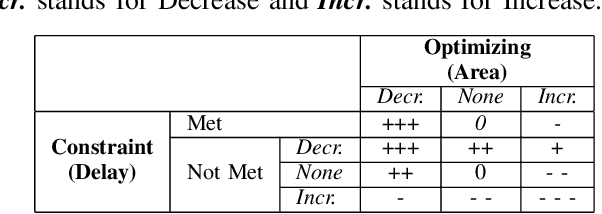
Logic synthesis requires extensive tuning of the synthesis optimization flow where the quality of results (QoR) depends on the sequence of optimizations used. Efficient design space exploration is challenging due to the exponential number of possible optimization permutations. Therefore, automating the optimization process is necessary. In this work, we propose a novel reinforcement learning-based methodology that navigates the optimization space without human intervention. We demonstrate the training of an Advantage Actor Critic (A2C) agent that seeks to minimize area subject to a timing constraint. Using the proposed methodology, designs can be optimized autonomously with no-humans in-loop. Evaluation on the comprehensive EPFL benchmark suite shows that the agent outperforms existing exploration methodologies and improves QoRs by an average of 13%.
Flexible Deep Neural Network Processing
Jan 23, 2018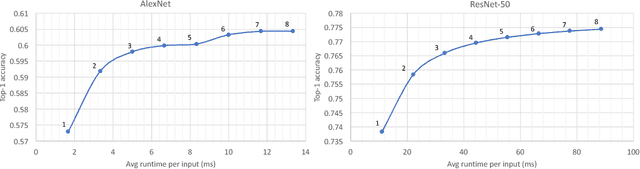
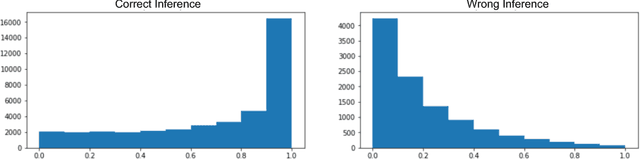
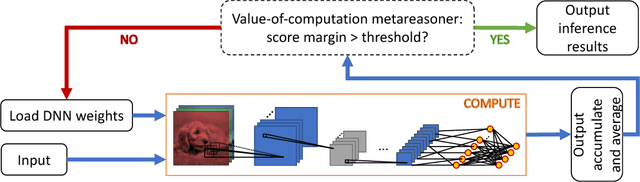
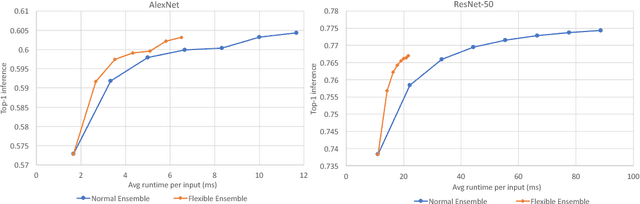
The recent success of Deep Neural Networks (DNNs) has drastically improved the state of the art for many application domains. While achieving high accuracy performance, deploying state-of-the-art DNNs is a challenge since they typically require billions of expensive arithmetic computations. In addition, DNNs are typically deployed in ensemble to boost accuracy performance, which further exacerbates the system requirements. This computational overhead is an issue for many platforms, e.g. data centers and embedded systems, with tight latency and energy budgets. In this article, we introduce flexible DNNs ensemble processing technique, which achieves large reduction in average inference latency while incurring small to negligible accuracy drop. Our technique is flexible in that it allows for dynamic adaptation between quality of results (QoR) and execution runtime. We demonstrate the effectiveness of the technique on AlexNet and ResNet-50 using the ImageNet dataset. This technique can also easily handle other types of networks.
Hardware-Software Codesign of Accurate, Multiplier-free Deep Neural Networks
May 11, 2017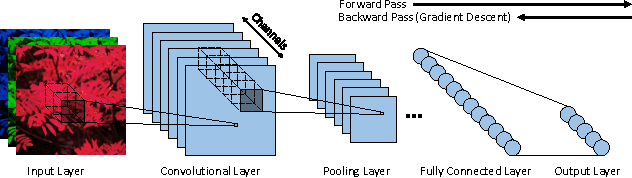
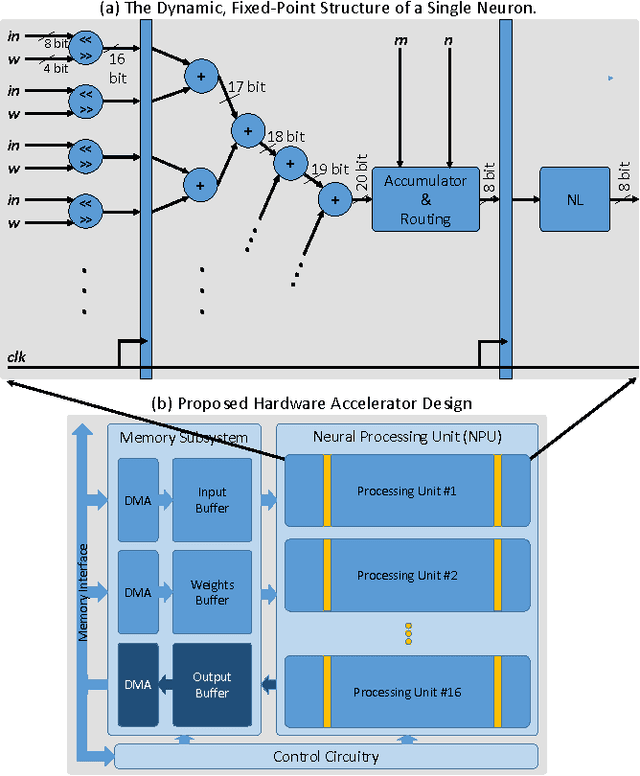

While Deep Neural Networks (DNNs) push the state-of-the-art in many machine learning applications, they often require millions of expensive floating-point operations for each input classification. This computation overhead limits the applicability of DNNs to low-power, embedded platforms and incurs high cost in data centers. This motivates recent interests in designing low-power, low-latency DNNs based on fixed-point, ternary, or even binary data precision. While recent works in this area offer promising results, they often lead to large accuracy drops when compared to the floating-point networks. We propose a novel approach to map floating-point based DNNs to 8-bit dynamic fixed-point networks with integer power-of-two weights with no change in network architecture. Our dynamic fixed-point DNNs allow different radix points between layers. During inference, power-of-two weights allow multiplications to be replaced with arithmetic shifts, while the 8-bit fixed-point representation simplifies both the buffer and adder design. In addition, we propose a hardware accelerator design to achieve low-power, low-latency inference with insignificant degradation in accuracy. Using our custom accelerator design with the CIFAR-10 and ImageNet datasets, we show that our method achieves significant power and energy savings while increasing the classification accuracy.
Understanding the Impact of Precision Quantization on the Accuracy and Energy of Neural Networks
Dec 12, 2016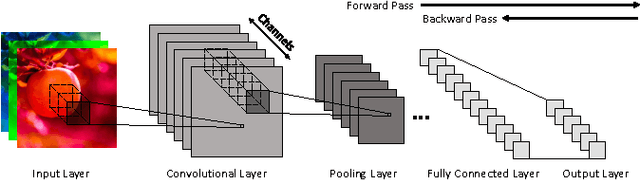
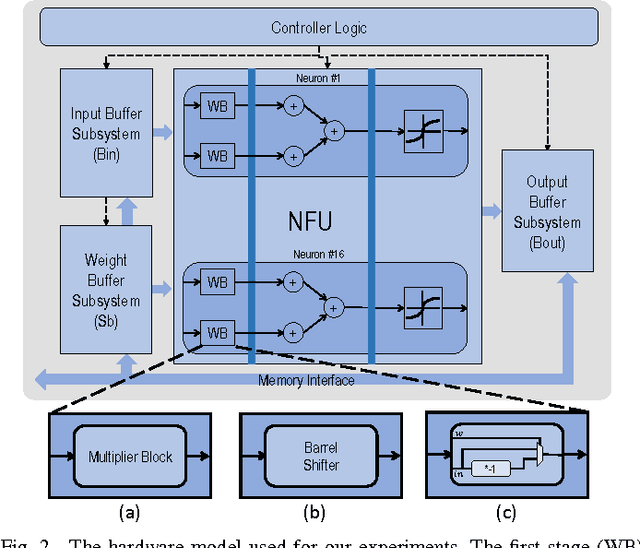
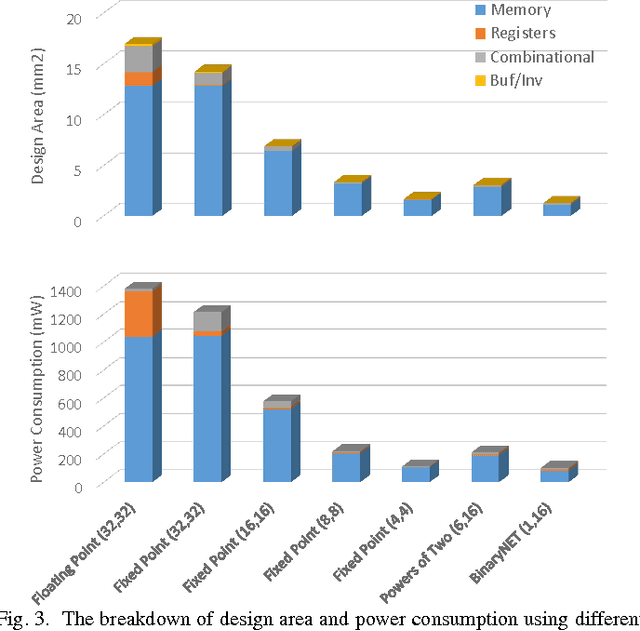
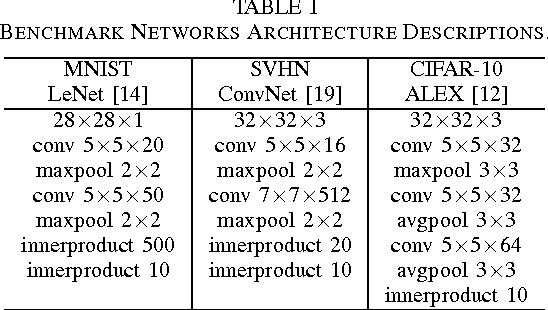
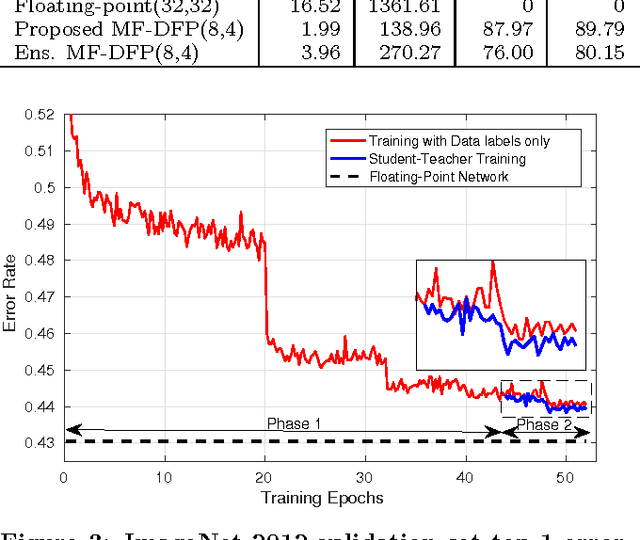
Deep neural networks are gaining in popularity as they are used to generate state-of-the-art results for a variety of computer vision and machine learning applications. At the same time, these networks have grown in depth and complexity in order to solve harder problems. Given the limitations in power budgets dedicated to these networks, the importance of low-power, low-memory solutions has been stressed in recent years. While a large number of dedicated hardware using different precisions has recently been proposed, there exists no comprehensive study of different bit precisions and arithmetic in both inputs and network parameters. In this work, we address this issue and perform a study of different bit-precisions in neural networks (from floating-point to fixed-point, powers of two, and binary). In our evaluation, we consider and analyze the effect of precision scaling on both network accuracy and hardware metrics including memory footprint, power and energy consumption, and design area. We also investigate training-time methodologies to compensate for the reduction in accuracy due to limited bit precision and demonstrate that in most cases, precision scaling can deliver significant benefits in design metrics at the cost of very modest decreases in network accuracy. In addition, we propose that a small portion of the benefits achieved when using lower precisions can be forfeited to increase the network size and therefore the accuracy. We evaluate our experiments, using three well-recognized networks and datasets to show its generality. We investigate the trade-offs and highlight the benefits of using lower precisions in terms of energy and memory footprint.
Runtime Configurable Deep Neural Networks for Energy-Accuracy Trade-off
Jul 20, 2016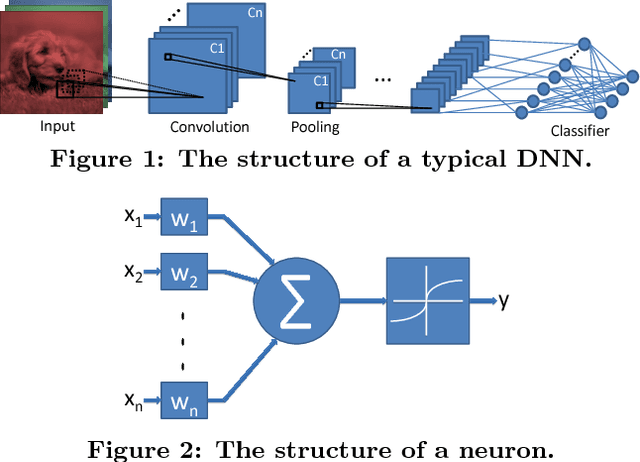
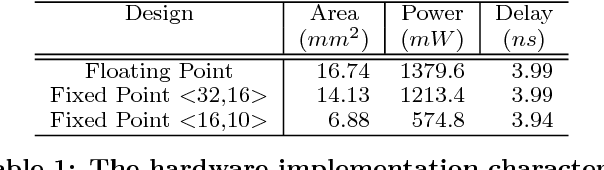
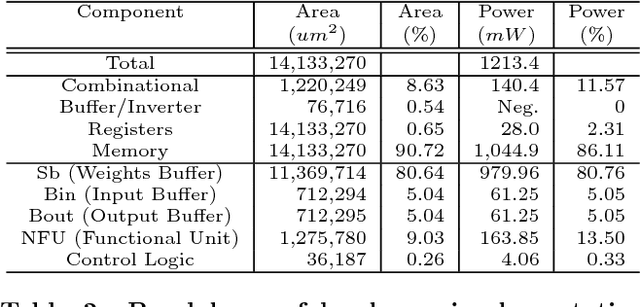
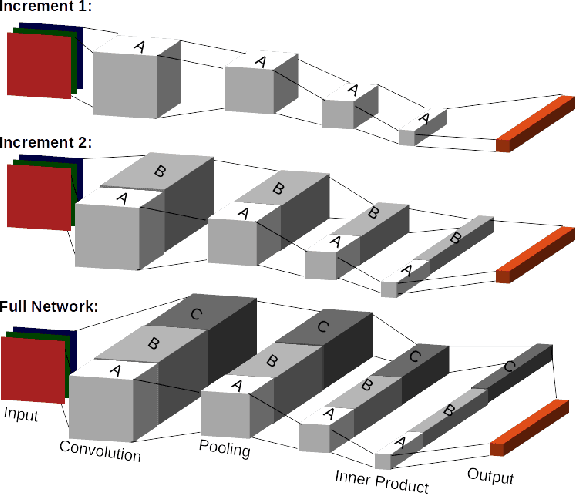
We present a novel dynamic configuration technique for deep neural networks that permits step-wise energy-accuracy trade-offs during runtime. Our configuration technique adjusts the number of channels in the network dynamically depending on response time, power, and accuracy targets. To enable this dynamic configuration technique, we co-design a new training algorithm, where the network is incrementally trained such that the weights in channels trained in earlier steps are fixed. Our technique provides the flexibility of multiple networks while storing and utilizing one set of weights. We evaluate our techniques using both an ASIC-based hardware accelerator as well as a low-power embedded GPGPU and show that our approach leads to only a small or negligible loss in the final network accuracy. We analyze the performance of our proposed methodology using three well-known networks for MNIST, CIFAR-10, and SVHN datasets, and we show that we are able to achieve up to 95% energy reduction with less than 1% accuracy loss across the three benchmarks. In addition, compared to prior work on dynamic network reconfiguration, we show that our approach leads to approximately 50% savings in storage requirements, while achieving similar accuracy.