 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-Time, Energy-Efficient, Sampling-Based Optimal Control via FPGA Acceleration
Jan 23, 2026Autonomous mobile robots (AMRs), used for search-and-rescue and remote exploration, require fast and robust planning and control schemes. Sampling-based approaches for Model Predictive Control, especially approaches based on the Model Predictive Path Integral Control (MPPI) algorithm, have recently proven both to be highly effective for such applications and to map naturally to GPUs for hardware acceleration. However, both GPU and CPU implementations of such algorithms can struggle to meet tight energy and latency budgets on battery-constrained AMR platforms that leverage embedded compute. To address this issue, we present an FPGA-optimized MPPI design that exposes fine-grained parallelism and eliminates synchronization bottlenecks via deep pipelining and parallelism across algorithmic stages. This results in an average 3.1x to 7.5x speedup over optimized implementations on an embedded GPU and CPU, respectively, while simultaneously achieving a 2.5x to 5.4x reduction in energy usage. These results demonstrate that FPGA architectures are a promising direction for energy-efficient and high-performance edge robotics.
Using Human-Guided Causal Knowledge for More Generalized Robot Task Planning
Oct 09, 2021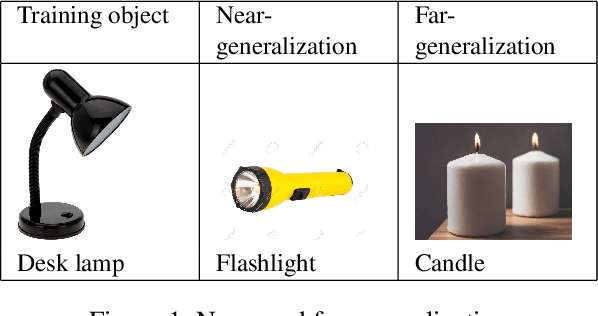
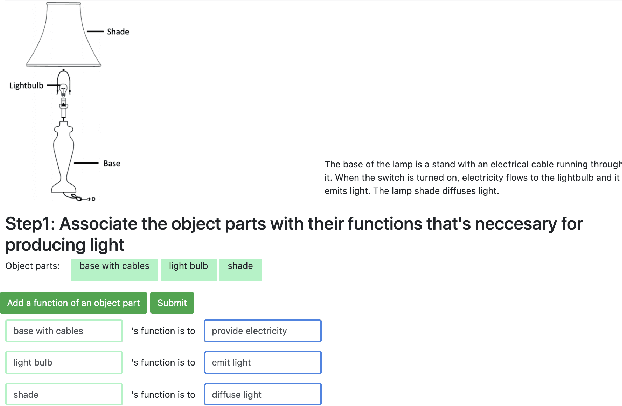
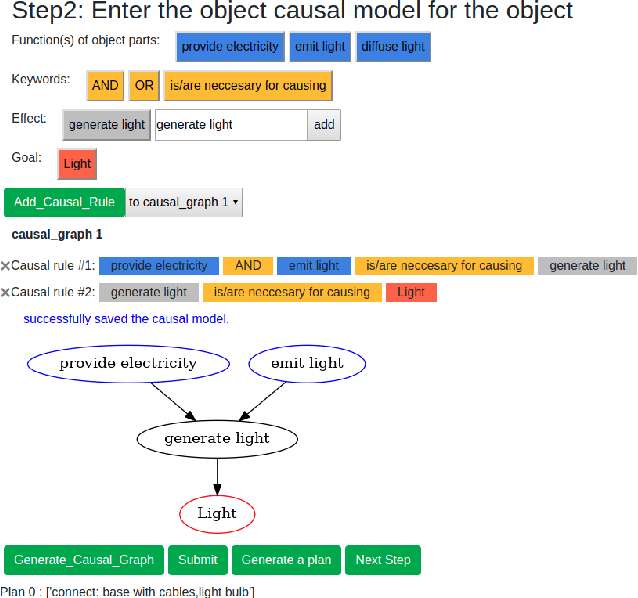
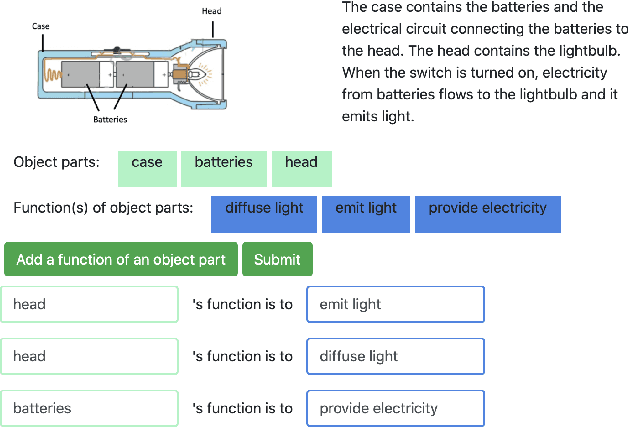
A major challenge in research involving artificial intelligence (AI) is the development of algorithms that can find solutions to problems that can generalize to different environments and tasks. Unlike AI, humans are adept at finding solutions that can transfer. We hypothesize this is because their solutions are informed by causal models. We propose to use human-guided causal knowledge to help robots find solutions that can generalize to a new environment. We develop and test the feasibility of a language interface that na\"ive participants can use to communicate these causal models to a planner. We find preliminary evidence that participants are able to use our interface and generate causal models that achieve near-generalization. We outline an experiment aimed at testing far-generalization using our interface and describe our longer terms goals for these causal models.
Hardware Acceleration of Monte-Carlo Sampling for Energy Efficient Robust Robot Manipulation
Jul 15, 2020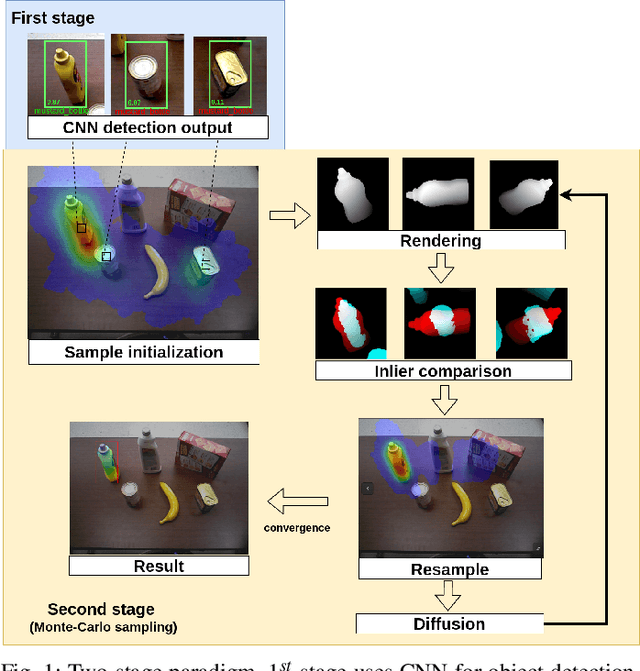
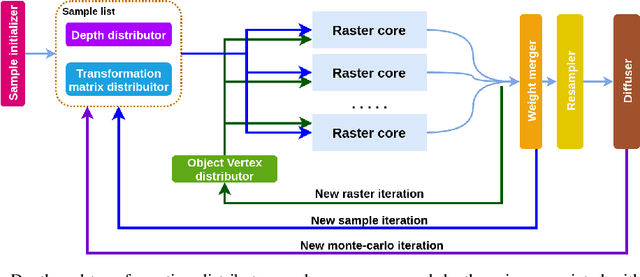
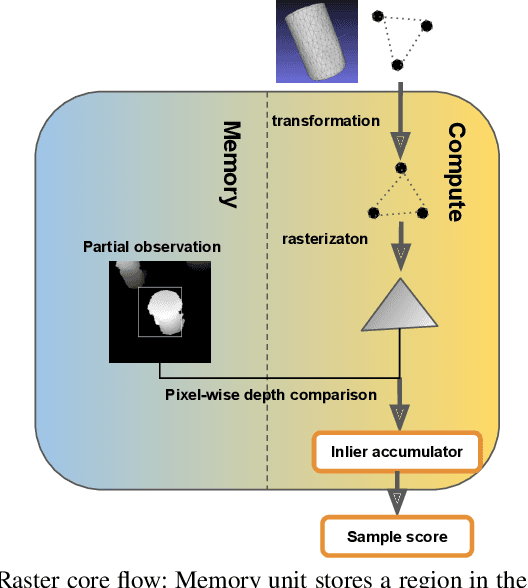

Algorithms based on Monte-Carlo sampling have been widely adapted in robotics and other areas of engineering due to their performance robustness. However, these sampling-based approaches have high computational requirements, making them unsuitable for real-time applications with tight energy constraints. In this paper, we investigate 6 degree-of-freedom (6DoF) pose estimation for robot manipulation using this method, which uses rendering combined with sequential Monte-Carlo sampling. While potentially very accurate, the significant computational complexity of the algorithm makes it less attractive for mobile robots, where runtime and energy consumption are tightly constrained. To address these challenges, we develop a novel hardware implementation of Monte-Carlo sampling on an FPGA with lower computational complexity and memory usage, while achieving high parallelism and modularization. Our results show 12X-21X improvements in energy efficiency over low-power and high-end GPU implementations, respectively. Moreover, we achieve real time performance without compromising accuracy.
GRIP: Generative Robust Inference and Perception for Semantic Robot Manipulation in Adversarial Environments
Mar 20, 2019
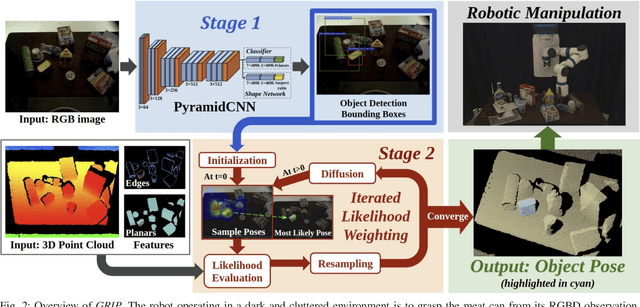
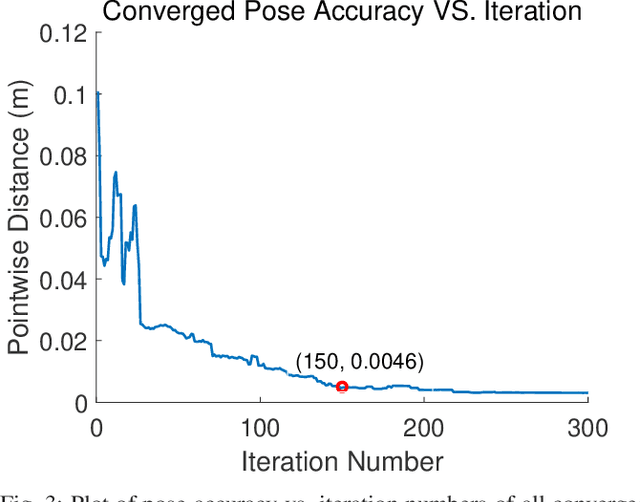

Recent advancements have led to a proliferation of machine learning systems used to assist humans in a wide range of tasks. However, we are still far from accurate, reliable, and resource-efficient operations of these systems. For robot perception, convolutional neural networks (CNNs) for object detection and pose estimation are recently coming into widespread use. However, neural networks are known to suffer overfitting during training process and are less robust within unseen conditions, which are especially vulnerable to {\em adversarial scenarios}. In this work, we propose {\em Generative Robust Inference and Perception (GRIP)} as a two-stage object detection and pose estimation system that aims to combine relative strengths of discriminative CNNs and generative inference methods to achieve robust estimation. Our results show that a second stage of sample-based generative inference is able to recover from false object detection by CNNs, and produce robust estimations in adversarial conditions. We demonstrate the efficacy of {\em GRIP} robustness through comparison with state-of-the-art learning-based pose estimators and pick-and-place manipulation in dark and cluttered environments.
Understanding the Impact of Precision Quantization on the Accuracy and Energy of Neural Networks
Dec 12, 2016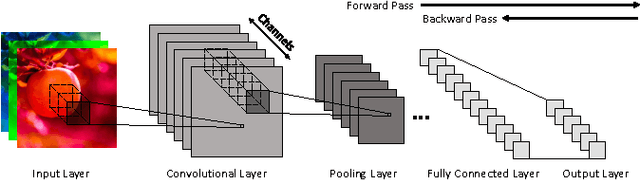
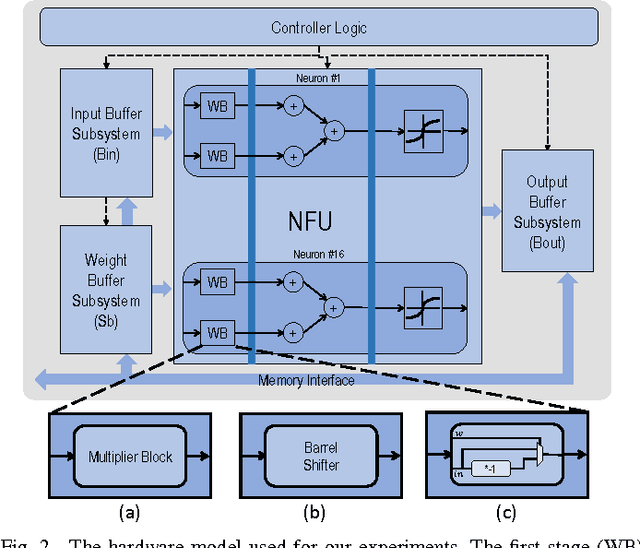
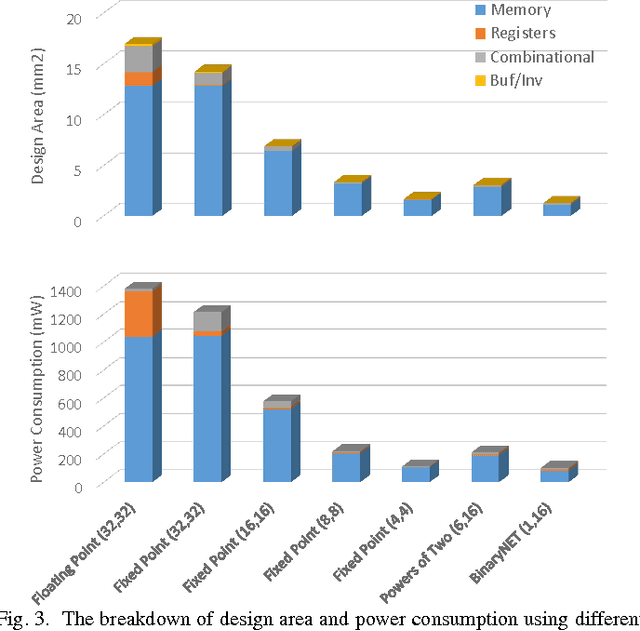
Deep neural networks are gaining in popularity as they are used to generate state-of-the-art results for a variety of computer vision and machine learning applications. At the same time, these networks have grown in depth and complexity in order to solve harder problems. Given the limitations in power budgets dedicated to these networks, the importance of low-power, low-memory solutions has been stressed in recent years. While a large number of dedicated hardware using different precisions has recently been proposed, there exists no comprehensive study of different bit precisions and arithmetic in both inputs and network parameters. In this work, we address this issue and perform a study of different bit-precisions in neural networks (from floating-point to fixed-point, powers of two, and binary). In our evaluation, we consider and analyze the effect of precision scaling on both network accuracy and hardware metrics including memory footprint, power and energy consumption, and design area. We also investigate training-time methodologies to compensate for the reduction in accuracy due to limited bit precision and demonstrate that in most cases, precision scaling can deliver significant benefits in design metrics at the cost of very modest decreases in network accuracy. In addition, we propose that a small portion of the benefits achieved when using lower precisions can be forfeited to increase the network size and therefore the accuracy. We evaluate our experiments, using three well-recognized networks and datasets to show its generality. We investigate the trade-offs and highlight the benefits of using lower precisions in terms of energy and memory footprint.
Runtime Configurable Deep Neural Networks for Energy-Accuracy Trade-off
Jul 20, 2016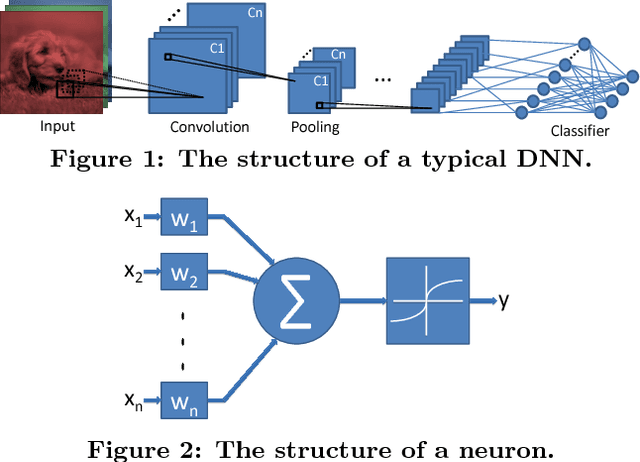
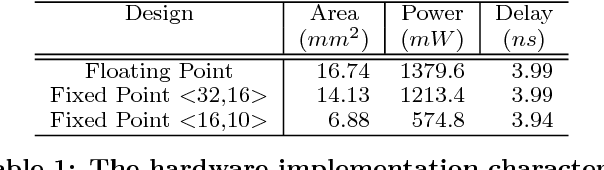
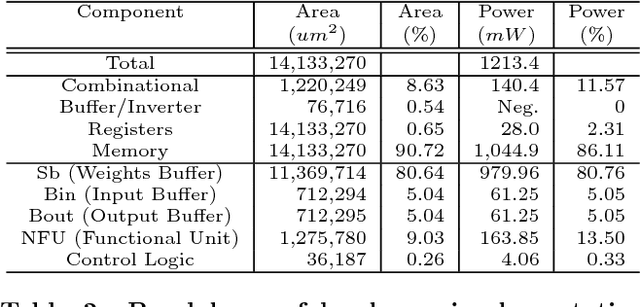
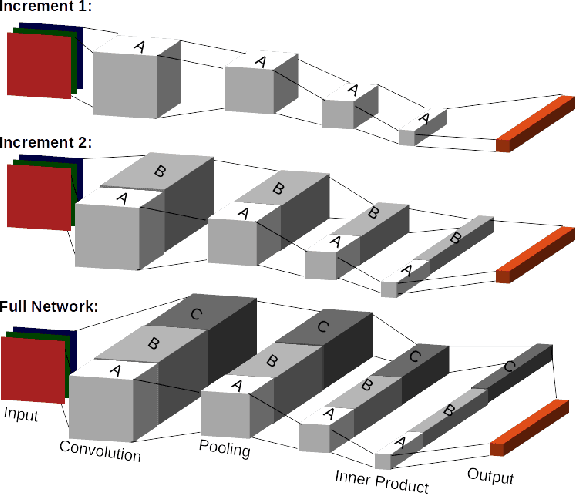
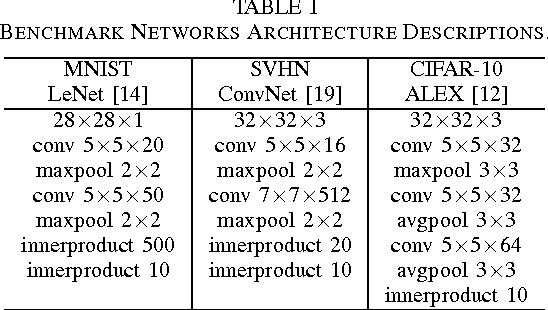
We present a novel dynamic configuration technique for deep neural networks that permits step-wise energy-accuracy trade-offs during runtime. Our configuration technique adjusts the number of channels in the network dynamically depending on response time, power, and accuracy targets. To enable this dynamic configuration technique, we co-design a new training algorithm, where the network is incrementally trained such that the weights in channels trained in earlier steps are fixed. Our technique provides the flexibility of multiple networks while storing and utilizing one set of weights. We evaluate our techniques using both an ASIC-based hardware accelerator as well as a low-power embedded GPGPU and show that our approach leads to only a small or negligible loss in the final network accuracy. We analyze the performance of our proposed methodology using three well-known networks for MNIST, CIFAR-10, and SVHN datasets, and we show that we are able to achieve up to 95% energy reduction with less than 1% accuracy loss across the three benchmarks. In addition, compared to prior work on dynamic network reconfiguration, we show that our approach leads to approximately 50% savings in storage requirements, while achieving similar accuracy.