 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn End-to-End Learning-Based Multi-Sensor Fusion for Autonomous Vehicle Localization
Mar 07, 2025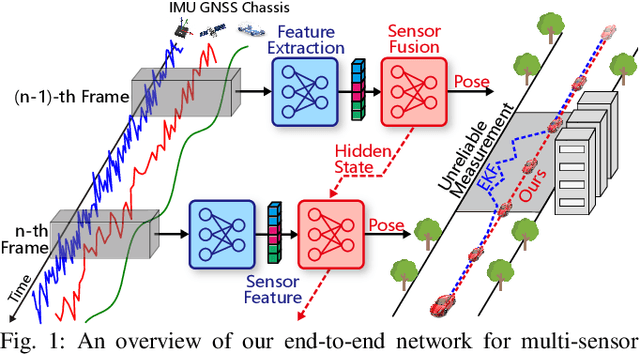
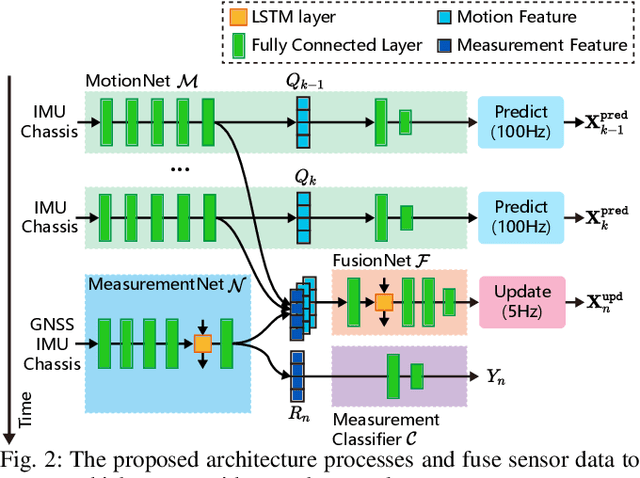
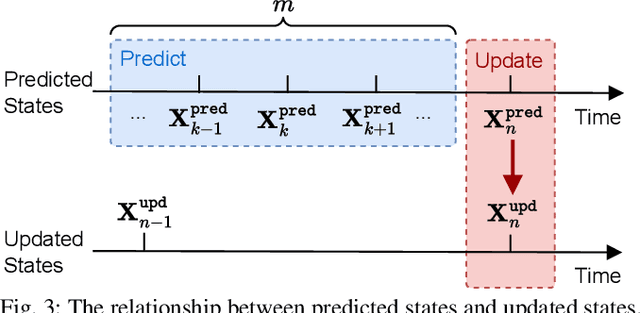

Multi-sensor fusion is essential for autonomous vehicle localization, as it is capable of integrating data from various sources for enhanced accuracy and reliability. The accuracy of the integrated location and orientation depends on the precision of the uncertainty modeling. Traditional methods of uncertainty modeling typically assume a Gaussian distribution and involve manual heuristic parameter tuning. However, these methods struggle to scale effectively and address long-tail scenarios. To address these challenges, we propose a learning-based method that encodes sensor information using higher-order neural network features, thereby eliminating the need for uncertainty estimation. This method significantly eliminates the need for parameter fine-tuning by developing an end-to-end neural network that is specifically designed for multi-sensor fusion. In our experiments, we demonstrate the effectiveness of our approach in real-world autonomous driving scenarios. Results show that the proposed method outperforms existing multi-sensor fusion methods in terms of both accuracy and robustness. A video of the results can be viewed at https://youtu.be/q4iuobMbjME.
GeoFusion: Geometric Consistency informed Scene Estimation in Dense Clutter
Mar 27, 2020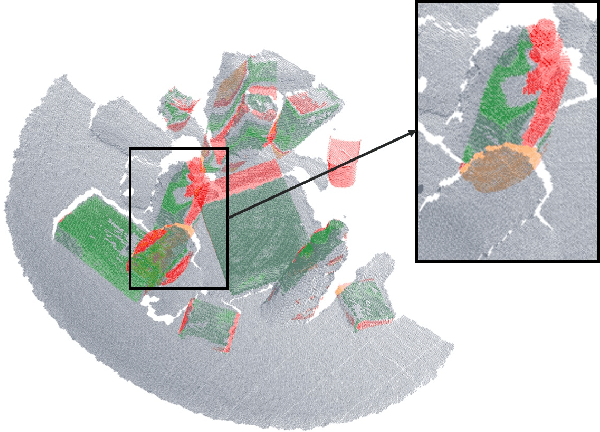
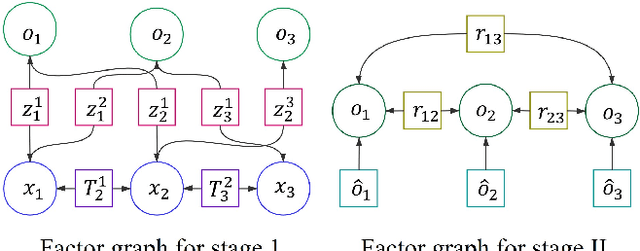
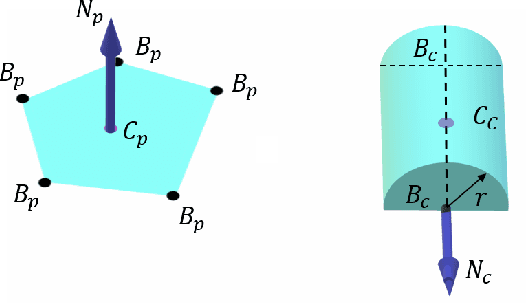
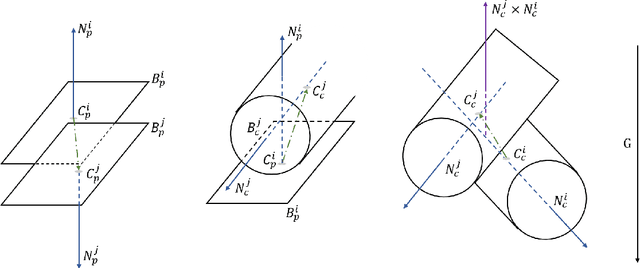
We propose GeoFusion, a SLAM-based scene estimation method for building an object-level semantic map in dense clutter. In dense clutter, objects are often in close contact and severe occlusions, which brings more false detections and noisy pose estimates from existing perception methods. To solve these problems, our key insight is to consider geometric consistency at the object level within a general SLAM framework. The geometric consistency is defined in two parts: geometric consistency score and geometric relation. The geometric consistency score describes the compatibility between object geometry model and observation point cloud. Meanwhile it provides a reliable measure to filter out false positives in data association. The geometric relation represents the relationship (e.g. contact) between geometric features (e.g. planes) among objects. The geometric relation makes the graph optimization for poses more robust and accurate. GeoFusion can robustly and efficiently infer the object labels, 6D object poses and spatial relations from continutous noisy semantic measurements. We quantitatively evaluate our method using observations from a Fetch mobile manipulation robot. Our results demonstrate greater robustness against false estimates than frame-by-frame pose estimation from the state-of-the-art convolutional neural network.
GRIP: Generative Robust Inference and Perception for Semantic Robot Manipulation in Adversarial Environments
Mar 20, 2019
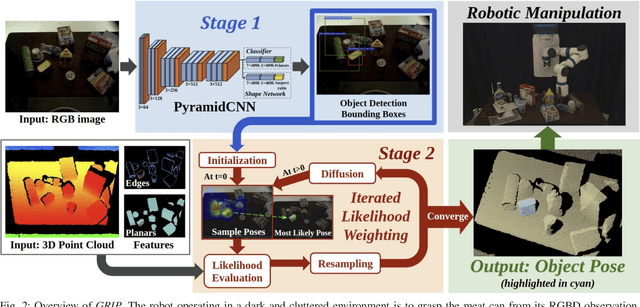
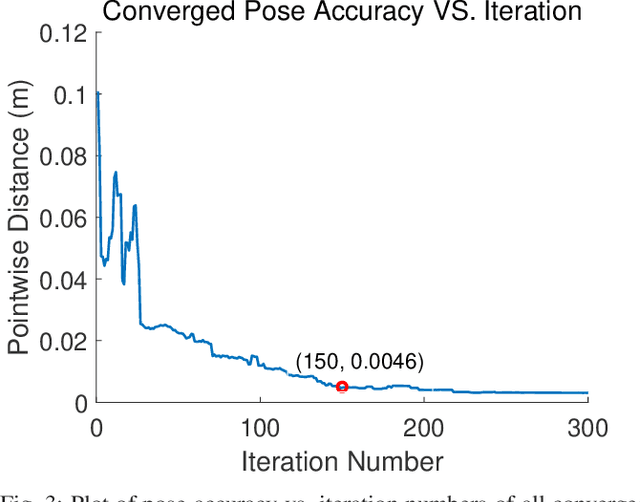

Recent advancements have led to a proliferation of machine learning systems used to assist humans in a wide range of tasks. However, we are still far from accurate, reliable, and resource-efficient operations of these systems. For robot perception, convolutional neural networks (CNNs) for object detection and pose estimation are recently coming into widespread use. However, neural networks are known to suffer overfitting during training process and are less robust within unseen conditions, which are especially vulnerable to {\em adversarial scenarios}. In this work, we propose {\em Generative Robust Inference and Perception (GRIP)} as a two-stage object detection and pose estimation system that aims to combine relative strengths of discriminative CNNs and generative inference methods to achieve robust estimation. Our results show that a second stage of sample-based generative inference is able to recover from false object detection by CNNs, and produce robust estimations in adversarial conditions. We demonstrate the efficacy of {\em GRIP} robustness through comparison with state-of-the-art learning-based pose estimators and pick-and-place manipulation in dark and cluttered environments.
Plenoptic Monte Carlo Object Localization for Robot Grasping under Layered Translucency
Dec 02, 2018
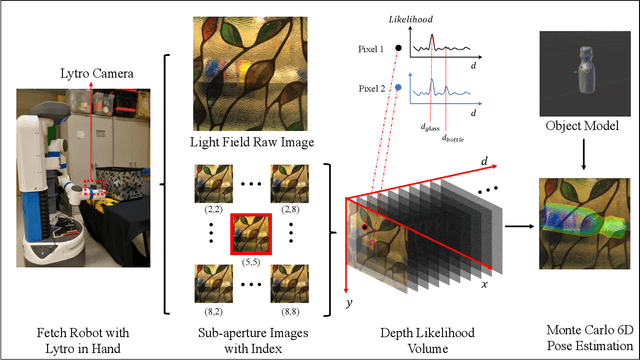
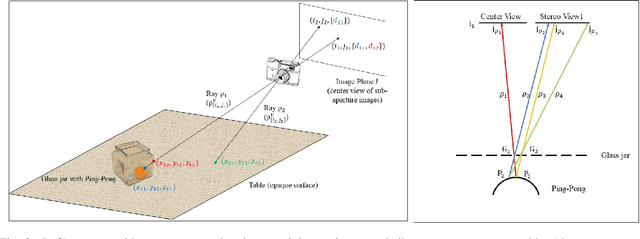

In order to fully function in human environments, robot perception will need to account for the uncertainty caused by translucent materials. Translucency poses several open challenges in the form of transparent objects (e.g., drinking glasses), refractive media (e.g., water), and diffuse partial occlusions (e.g., objects behind stained glass panels). This paper presents Plenoptic Monte Carlo Localization (PMCL) as a method for localizing object poses in the presence of translucency using plenoptic (light-field) observations. We propose a new depth descriptor, the Depth Likelihood Volume (DLV), and its use within a Monte Carlo object localization algorithm. We present results of localizing and manipulating objects with translucent materials and objects occluded by layers of translucency. Our PMCL implementation uses observations from a Lytro first generation light field camera to allow a Michigan Progress Fetch robot to perform grasping.
Semantic Robot Programming for Goal-Directed Manipulation in Cluttered Scenes
Oct 18, 2018
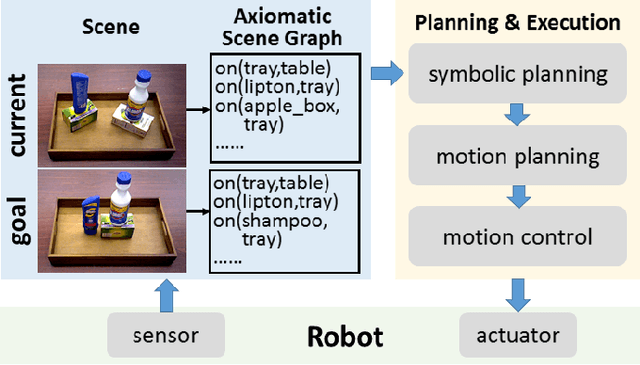

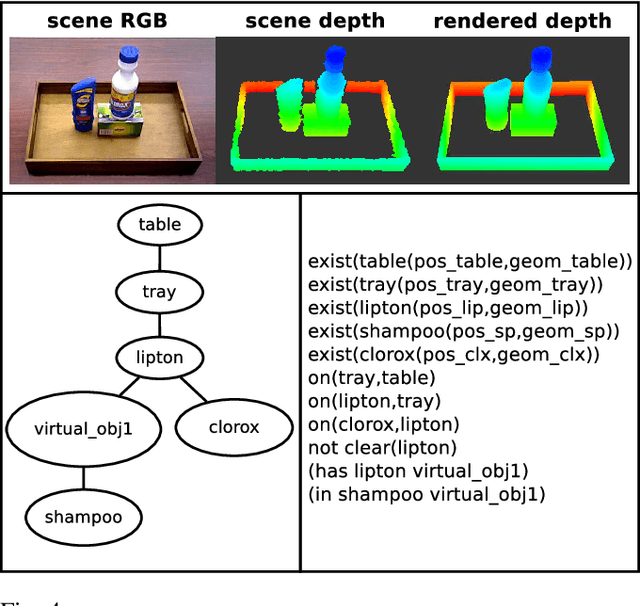
We present the Semantic Robot Programming (SRP) paradigm as a convergence of robot programming by demonstration and semantic mapping. In SRP, a user can directly program a robot manipulator by demonstrating a snapshot of their intended goal scene in workspace. The robot then parses this goal as a scene graph comprised of object poses and inter-object relations, assuming known object geometries. Task and motion planning is then used to realize the user's goal from an arbitrary initial scene configuration. Even when faced with different initial scene configurations, SRP enables the robot to seamlessly adapt to reach the user's demonstrated goal. For scene perception, we propose the Discriminatively-Informed Generative Estimation of Scenes and Transforms (DIGEST) method to infer the initial and goal states of the world from RGBD images. The efficacy of SRP with DIGEST perception is demonstrated for the task of tray-setting with a Michigan Progress Fetch robot. Scene perception and task execution are evaluated with a public household occlusion dataset and our cluttered scene dataset.
Never Mind the Bounding Boxes, Here's the SAND Filters
Aug 15, 2018
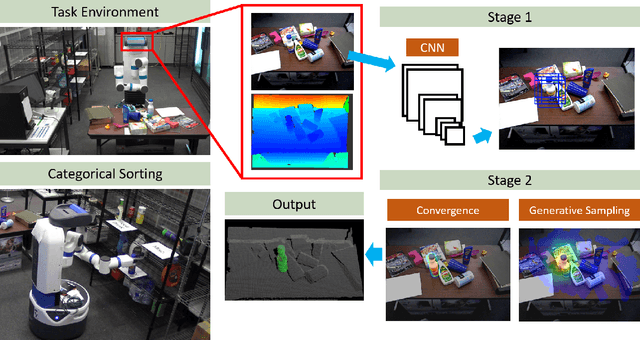
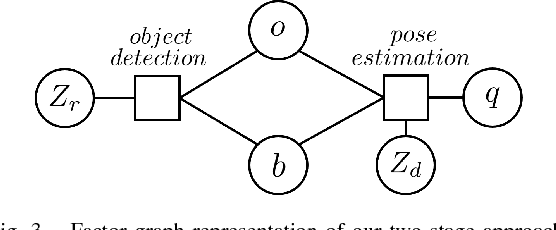
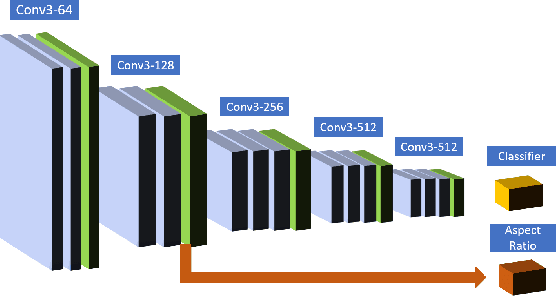
Perception is the main bottleneck to perform autonomous mobile manipulation tasks, especially in cluttered and unstructured environment. In this paper, we propose a novel two-stage paradigm that leverage both CNN object prior and generative sampling to perform object detection and 6D pose estimation. Our two-stage approach builds upon both CNN and generative sampling-based local search method to achieve sampling the network density, or SAND filter. We show the quantitative results that SAND effectively improve object detection result by reducing false positive and false negative recognitions, and further produces accurate pose estimation. We also conduct extensive categorical object sorting experiments to show our method is able to produce accurate and reliable detections and object poses.
SUM: Sequential Scene Understanding and Manipulation
Mar 22, 2017
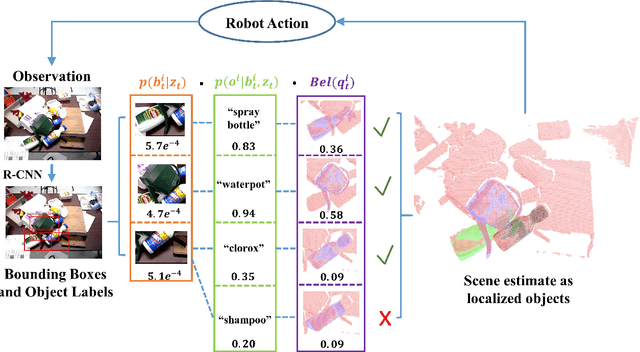
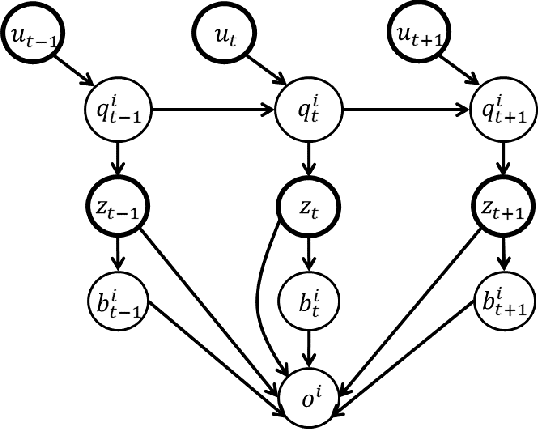
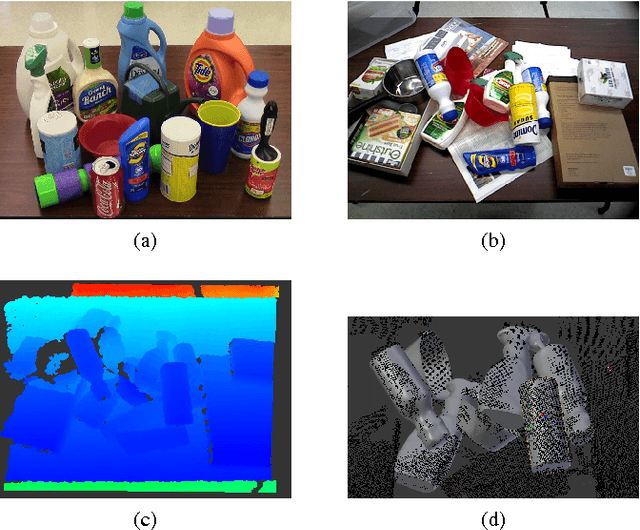
In order to perform autonomous sequential manipulation tasks, perception in cluttered scenes remains a critical challenge for robots. In this paper, we propose a probabilistic approach for robust sequential scene estimation and manipulation - Sequential Scene Understanding and Manipulation(SUM). SUM considers uncertainty due to discriminative object detection and recognition in the generative estimation of the most likely object poses maintained over time to achieve a robust estimation of the scene under heavy occlusions and unstructured environment. Our method utilizes candidates from discriminative object detector and recognizer to guide the generative process of sampling scene hypothesis, and each scene hypotheses is evaluated against the observations. Also SUM maintains beliefs of scene hypothesis over robot physical actions for better estimation and against noisy detections. We conduct extensive experiments to show that our approach is able to perform robust estimation and manipulation.