 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttribute-based Object Grounding and Robot Grasp Detection with Spatial Reasoning
Sep 09, 2025Enabling robots to grasp objects specified through natural language is essential for effective human-robot interaction, yet it remains a significant challenge. Existing approaches often struggle with open-form language expressions and typically assume unambiguous target objects without duplicates. Moreover, they frequently rely on costly, dense pixel-wise annotations for both object grounding and grasp configuration. We present Attribute-based Object Grounding and Robotic Grasping (OGRG), a novel framework that interprets open-form language expressions and performs spatial reasoning to ground target objects and predict planar grasp poses, even in scenes containing duplicated object instances. We investigate OGRG in two settings: (1) Referring Grasp Synthesis (RGS) under pixel-wise full supervision, and (2) Referring Grasp Affordance (RGA) using weakly supervised learning with only single-pixel grasp annotations. Key contributions include a bi-directional vision-language fusion module and the integration of depth information to enhance geometric reasoning, improving both grounding and grasping performance. Experiment results show that OGRG outperforms strong baselines in tabletop scenes with diverse spatial language instructions. In RGS, it operates at 17.59 FPS on a single NVIDIA RTX 2080 Ti GPU, enabling potential use in closed-loop or multi-object sequential grasping, while delivering superior grounding and grasp prediction accuracy compared to all the baselines considered. Under the weakly supervised RGA setting, OGRG also surpasses baseline grasp-success rates in both simulation and real-robot trials, underscoring the effectiveness of its spatial reasoning design. Project page: https://z.umn.edu/ogrg
Correspondence-Free SE(3) Point Cloud Registration in RKHS via Unsupervised Equivariant Learning
Jul 29, 2024This paper introduces a robust unsupervised SE(3) point cloud registration method that operates without requiring point correspondences. The method frames point clouds as functions in a reproducing kernel Hilbert space (RKHS), leveraging SE(3)-equivariant features for direct feature space registration. A novel RKHS distance metric is proposed, offering reliable performance amidst noise, outliers, and asymmetrical data. An unsupervised training approach is introduced to effectively handle limited ground truth data, facilitating adaptation to real datasets. The proposed method outperforms classical and supervised methods in terms of registration accuracy on both synthetic (ModelNet40) and real-world (ETH3D) noisy, outlier-rich datasets. To our best knowledge, this marks the first instance of successful real RGB-D odometry data registration using an equivariant method. The code is available at {https://sites.google.com/view/eccv24-equivalign}
CSCPR: Cross-Source-Context Indoor RGB-D Place Recognition
Jul 24, 2024



We present a new algorithm, Cross-Source-Context Place Recognition (CSCPR), for RGB-D indoor place recognition that integrates global retrieval and reranking into a single end-to-end model. Unlike prior approaches that primarily focus on the RGB domain, CSCPR is designed to handle the RGB-D data. We extend the Context-of-Clusters (CoCs) for handling noisy colorized point clouds and introduce two novel modules for reranking: the Self-Context Cluster (SCC) and Cross Source Context Cluster (CSCC), which enhance feature representation and match query-database pairs based on local features, respectively. We also present two new datasets, ScanNetIPR and ARKitIPR. Our experiments demonstrate that CSCPR significantly outperforms state-of-the-art models on these datasets by at least 36.5% in Recall@1 at ScanNet-PR dataset and 44% in new datasets. Code and datasets will be released.
PoCo: Point Context Cluster for RGBD Indoor Place Recognition
Apr 03, 2024We present a novel end-to-end algorithm (PoCo) for the indoor RGB-D place recognition task, aimed at identifying the most likely match for a given query frame within a reference database. The task presents inherent challenges attributed to the constrained field of view and limited range of perception sensors. We propose a new network architecture, which generalizes the recent Context of Clusters (CoCs) to extract global descriptors directly from the noisy point clouds through end-to-end learning. Moreover, we develop the architecture by integrating both color and geometric modalities into the point features to enhance the global descriptor representation. We conducted evaluations on public datasets ScanNet-PR and ARKit with 807 and 5047 scenarios, respectively. PoCo achieves SOTA performance: on ScanNet-PR, we achieve R@1 of 64.63%, a 5.7% improvement from the best-published result CGis (61.12%); on Arkit, we achieve R@1 of 45.12%, a 13.3% improvement from the best-published result CGis (39.82%). In addition, PoCo shows higher efficiency than CGis in inference time (1.75X-faster), and we demonstrate the effectiveness of PoCo in recognizing places within a real-world laboratory environment.
Tabletop Transparent Scene Reconstruction via Epipolar-Guided Optical Flow with Monocular Depth Completion Prior
Oct 15, 2023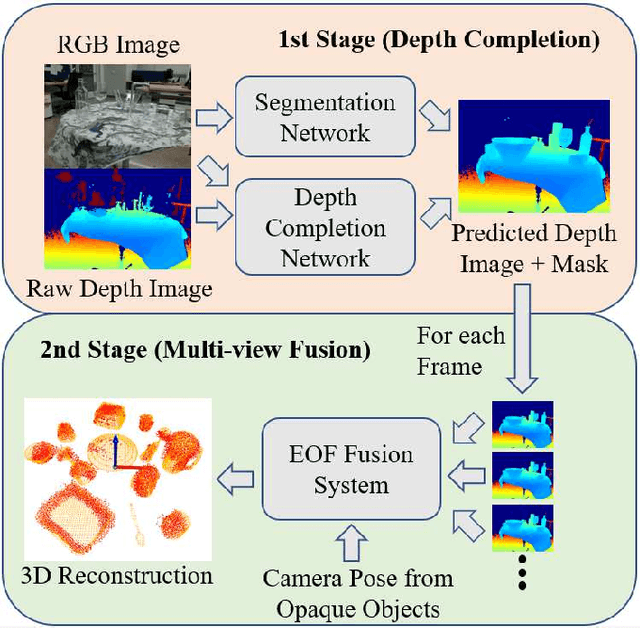


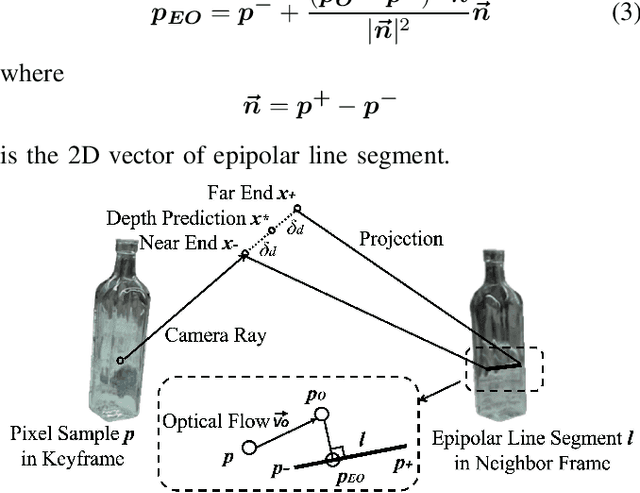
Reconstructing transparent objects using affordable RGB-D cameras is a persistent challenge in robotic perception due to inconsistent appearances across views in the RGB domain and inaccurate depth readings in each single-view. We introduce a two-stage pipeline for reconstructing transparent objects tailored for mobile platforms. In the first stage, off-the-shelf monocular object segmentation and depth completion networks are leveraged to predict the depth of transparent objects, furnishing single-view shape prior. Subsequently, we propose Epipolar-guided Optical Flow (EOF) to fuse several single-view shape priors from the first stage to a cross-view consistent 3D reconstruction given camera poses estimated from opaque part of the scene. Our key innovation lies in EOF which employs boundary-sensitive sampling and epipolar-line constraints into optical flow to accurately establish 2D correspondences across multiple views on transparent objects. Quantitative evaluations demonstrate that our pipeline significantly outperforms baseline methods in 3D reconstruction quality, paving the way for more adept robotic perception and interaction with transparent objects.
LIT: Light-field Inference of Transparency for Refractive Object Localization
Oct 24, 2019
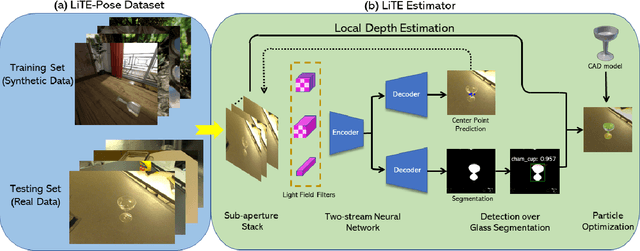
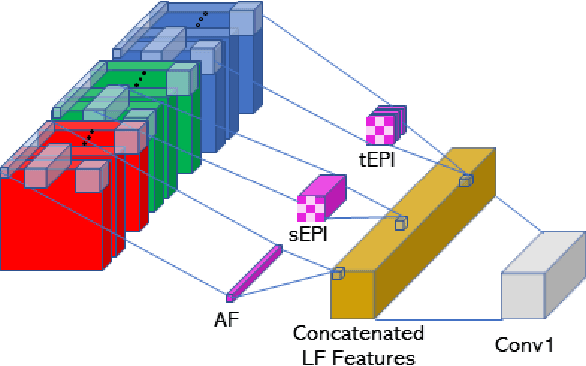

Translucency is prevalent in everyday scenes. As such, perception of transparent objects is essential for robots to perform manipulation. Compared with texture-rich or texture-less Lambertian objects, transparency induces significant uncertainty on object appearance. Ambiguity can be due to changes in lighting, viewpoint, and backgrounds, each of which brings challenges to existing object pose estimation algorithms. In this work, we propose LIT, a two-stage method for transparent object pose estimation using light-field sensing and photorealistic rendering. LIT employs multiple filters specific to light-field imagery in deep networks to capture transparent material properties combined with robust depth and pose estimators based on generative sampling. Along with the LIT algorithm, we introduce the first light-field transparent object dataset for the task of recognition, localization and pose estimation. Using proposed algorithm on our dataset, we show that LIT outperforms both a state-of-the-art end-to-end pose estimation method and a generative pose estimator on transparent objects.
GlassLoc: Plenoptic Grasp Pose Detection in Transparent Clutter
Sep 17, 2019
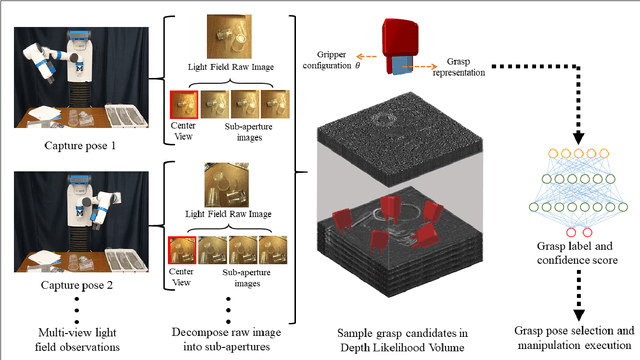
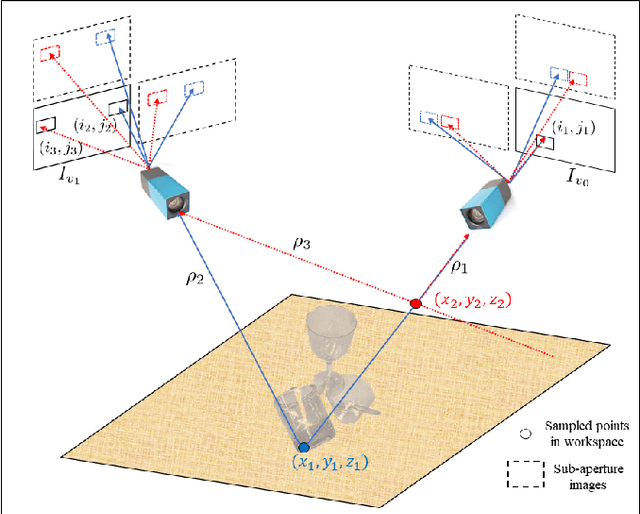
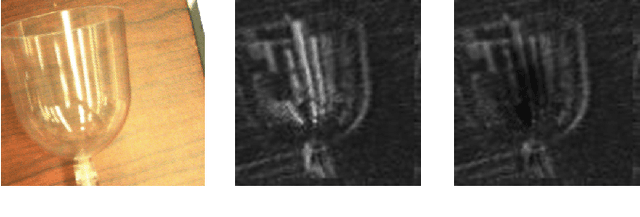
Transparent objects are prevalent across many environments of interest for dexterous robotic manipulation. Such transparent material leads to considerable uncertainty for robot perception and manipulation, and remains an open challenge for robotics. This problem is exacerbated when multiple transparent objects cluster into piles of clutter. In household environments, for example, it is common to encounter piles of glassware in kitchens, dining rooms, and reception areas, which are essentially invisible to modern robots. We present the GlassLoc algorithm for grasp pose detection of transparent objects in transparent clutter using plenoptic sensing. GlassLoc classifies graspable locations in space informed by a Depth Likelihood Volume (DLV) descriptor. We extend the DLV to infer the occupancy of transparent objects over a given space from multiple plenoptic viewpoints. We demonstrate and evaluate the GlassLoc algorithm on a Michigan Progress Fetch mounted with a first-generation Lytro. The effectiveness of our algorithm is evaluated through experiments for grasp detection and execution with a variety of transparent glassware in minor clutter.
Plenoptic Monte Carlo Object Localization for Robot Grasping under Layered Translucency
Dec 02, 2018
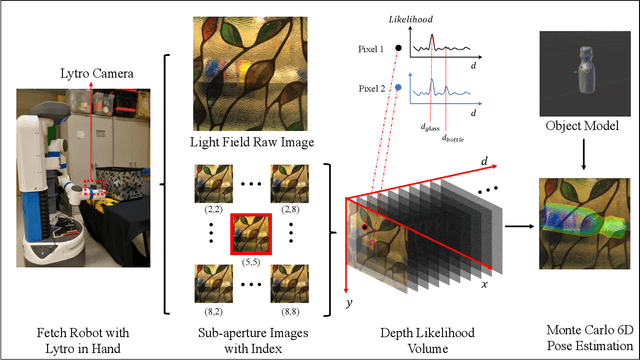
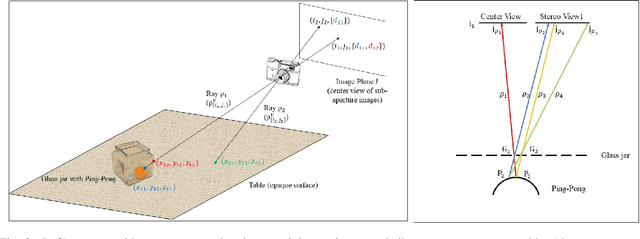

In order to fully function in human environments, robot perception will need to account for the uncertainty caused by translucent materials. Translucency poses several open challenges in the form of transparent objects (e.g., drinking glasses), refractive media (e.g., water), and diffuse partial occlusions (e.g., objects behind stained glass panels). This paper presents Plenoptic Monte Carlo Localization (PMCL) as a method for localizing object poses in the presence of translucency using plenoptic (light-field) observations. We propose a new depth descriptor, the Depth Likelihood Volume (DLV), and its use within a Monte Carlo object localization algorithm. We present results of localizing and manipulating objects with translucent materials and objects occluded by layers of translucency. Our PMCL implementation uses observations from a Lytro first generation light field camera to allow a Michigan Progress Fetch robot to perform grasping.
Semantic Robot Programming for Goal-Directed Manipulation in Cluttered Scenes
Oct 18, 2018
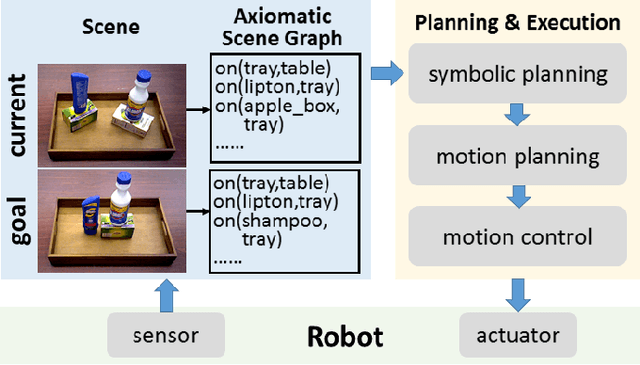

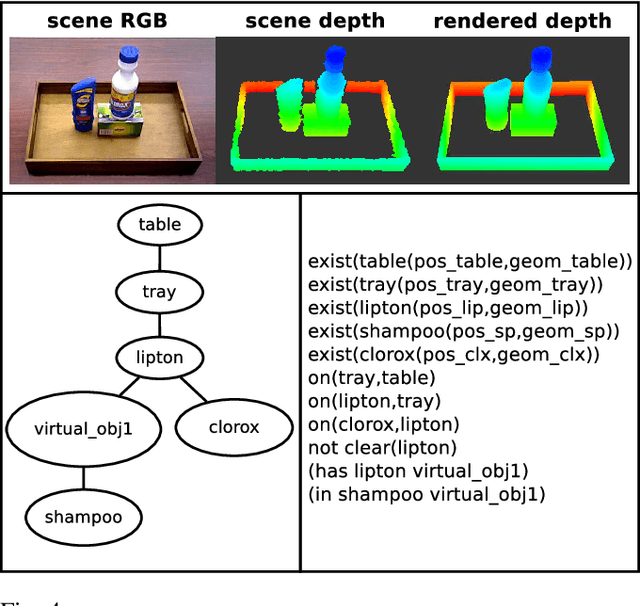
We present the Semantic Robot Programming (SRP) paradigm as a convergence of robot programming by demonstration and semantic mapping. In SRP, a user can directly program a robot manipulator by demonstrating a snapshot of their intended goal scene in workspace. The robot then parses this goal as a scene graph comprised of object poses and inter-object relations, assuming known object geometries. Task and motion planning is then used to realize the user's goal from an arbitrary initial scene configuration. Even when faced with different initial scene configurations, SRP enables the robot to seamlessly adapt to reach the user's demonstrated goal. For scene perception, we propose the Discriminatively-Informed Generative Estimation of Scenes and Transforms (DIGEST) method to infer the initial and goal states of the world from RGBD images. The efficacy of SRP with DIGEST perception is demonstrated for the task of tray-setting with a Michigan Progress Fetch robot. Scene perception and task execution are evaluated with a public household occlusion dataset and our cluttered scene dataset.
SUM: Sequential Scene Understanding and Manipulation
Mar 22, 2017
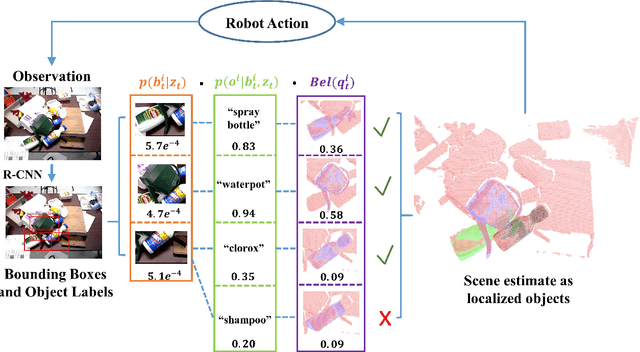
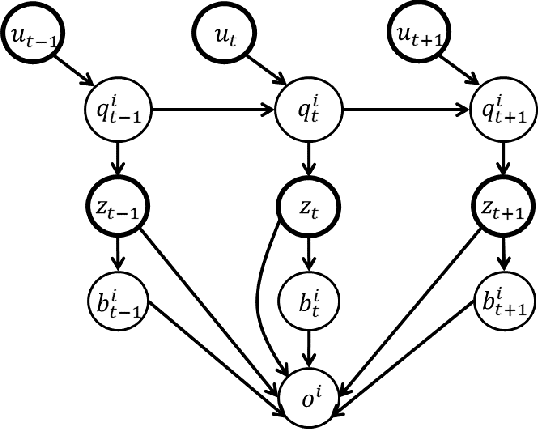
In order to perform autonomous sequential manipulation tasks, perception in cluttered scenes remains a critical challenge for robots. In this paper, we propose a probabilistic approach for robust sequential scene estimation and manipulation - Sequential Scene Understanding and Manipulation(SUM). SUM considers uncertainty due to discriminative object detection and recognition in the generative estimation of the most likely object poses maintained over time to achieve a robust estimation of the scene under heavy occlusions and unstructured environment. Our method utilizes candidates from discriminative object detector and recognizer to guide the generative process of sampling scene hypothesis, and each scene hypotheses is evaluated against the observations. Also SUM maintains beliefs of scene hypothesis over robot physical actions for better estimation and against noisy detections. We conduct extensive experiments to show that our approach is able to perform robust estimation and manipulation.