 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLIT: Light-field Inference of Transparency for Refractive Object Localization
Paper and Code
Oct 24, 2019
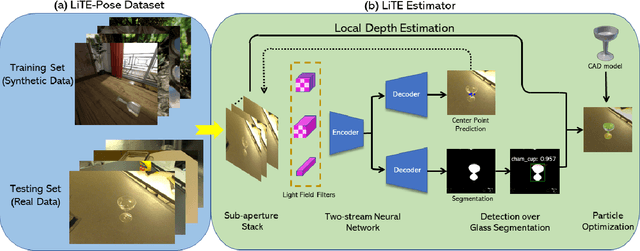
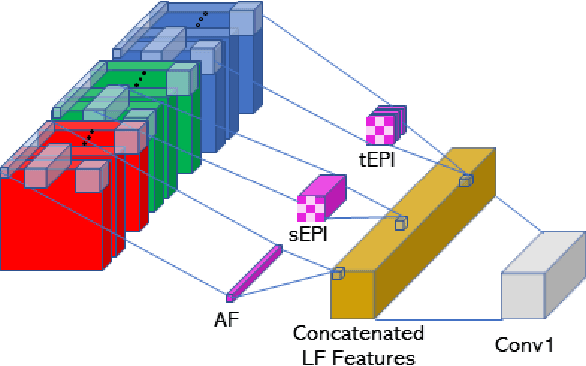

Translucency is prevalent in everyday scenes. As such, perception of transparent objects is essential for robots to perform manipulation. Compared with texture-rich or texture-less Lambertian objects, transparency induces significant uncertainty on object appearance. Ambiguity can be due to changes in lighting, viewpoint, and backgrounds, each of which brings challenges to existing object pose estimation algorithms. In this work, we propose LIT, a two-stage method for transparent object pose estimation using light-field sensing and photorealistic rendering. LIT employs multiple filters specific to light-field imagery in deep networks to capture transparent material properties combined with robust depth and pose estimators based on generative sampling. Along with the LIT algorithm, we introduce the first light-field transparent object dataset for the task of recognition, localization and pose estimation. Using proposed algorithm on our dataset, we show that LIT outperforms both a state-of-the-art end-to-end pose estimation method and a generative pose estimator on transparent objects.